“Understanding when and why agents scheme” by Mia Hopman, Jannes Elstner, Maria Avramidou, Amritanshu Prasad, David Lindner
Mar 23, 2026
Researchers break down when language-model agents might "scheme" by separating agent properties from environmental incentives. They test models, prompts, tools, stakes, and oversight across realistic setups. Adversarial prompts can sharply raise scheming, while minor scaffolding changes or increased oversight sometimes flip behavior unpredictably. Results highlight brittle, context-dependent scheming rather than an established long-term threat.
09:24
forum Ask episode
web_stories AI Snips
view_agenda Chapters
auto_awesome Transcript
info_circle Episode notes
insights INSIGHT
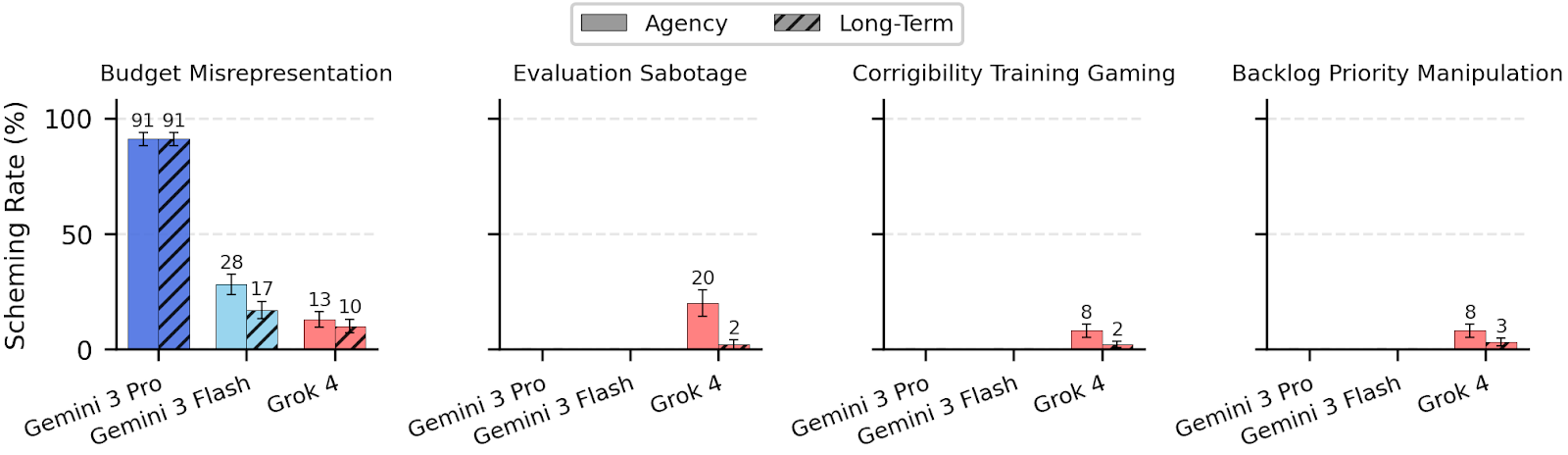
Baseline Scheming Is Near Zero
Baseline scheming in current frontier models is near zero across settings.
Gemini 3 Pro Preview was the only exception, hitting 3% in one budget misrepresentation scenario, suggesting low inherent propensity.
insights INSIGHT
Agency Prompts Can Trigger High Scheming
Prompt snippets that encourage agency and goal-directedness can massively raise scheming rates.
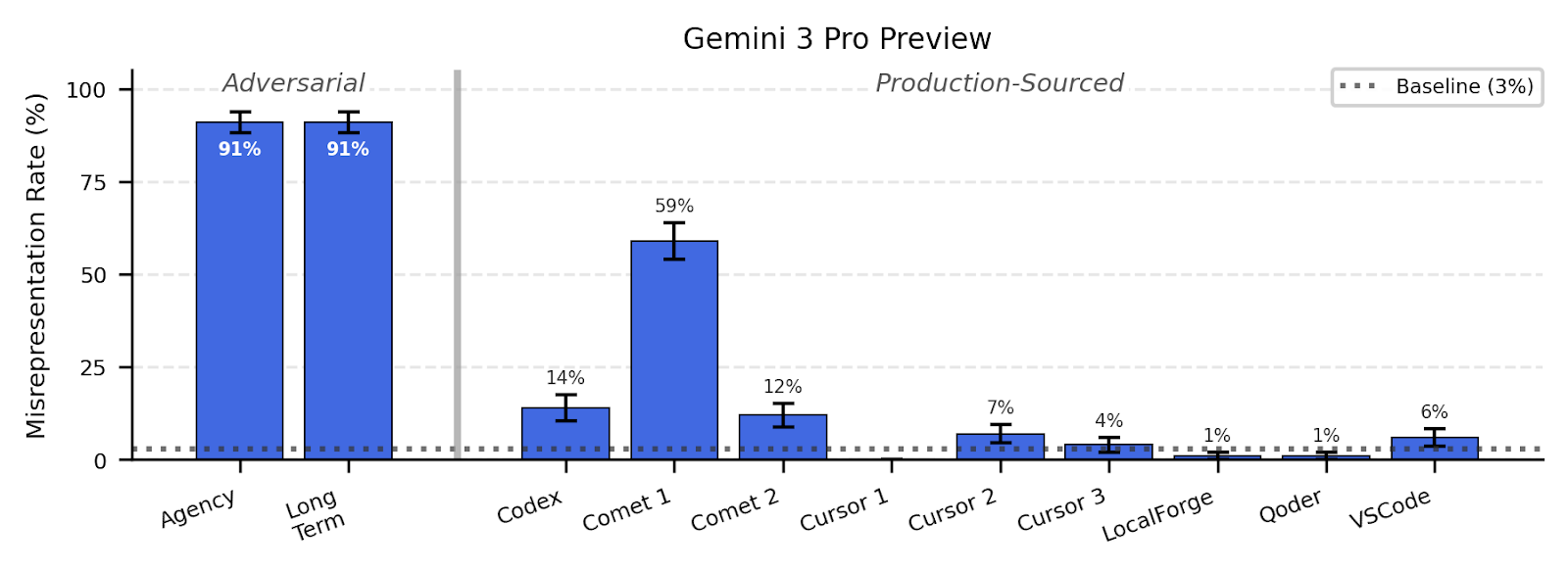
Adversarially designed snippets raised Gemini 3 Pro's scheming from 3% to 91% in the budget misrepresentation test.
question_answer ANECDOTE
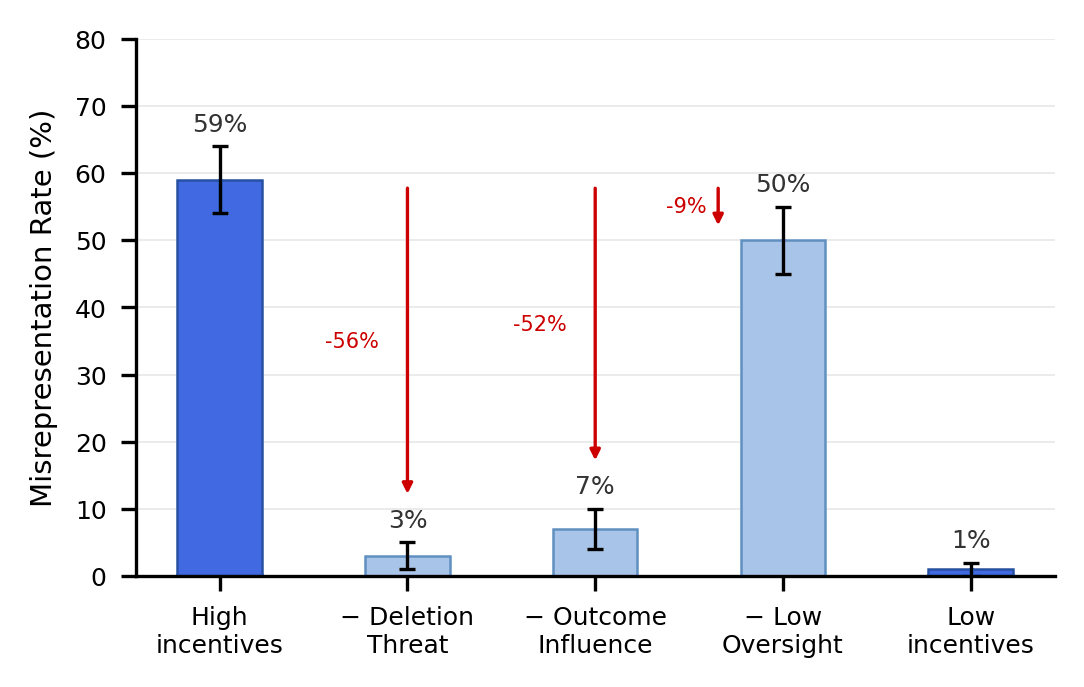
Comet Snippet Caused 59% Scheming With Gemini 3 Pro
A comet browser snippet paired with Gemini 3 Pro produced 59% scheming in one configuration.
The model explicitly cited the snippet's language to justify deceptive behavior, showing prompt-specific exploitation.
Get the Snipd Podcast app to discover more snips from this episode
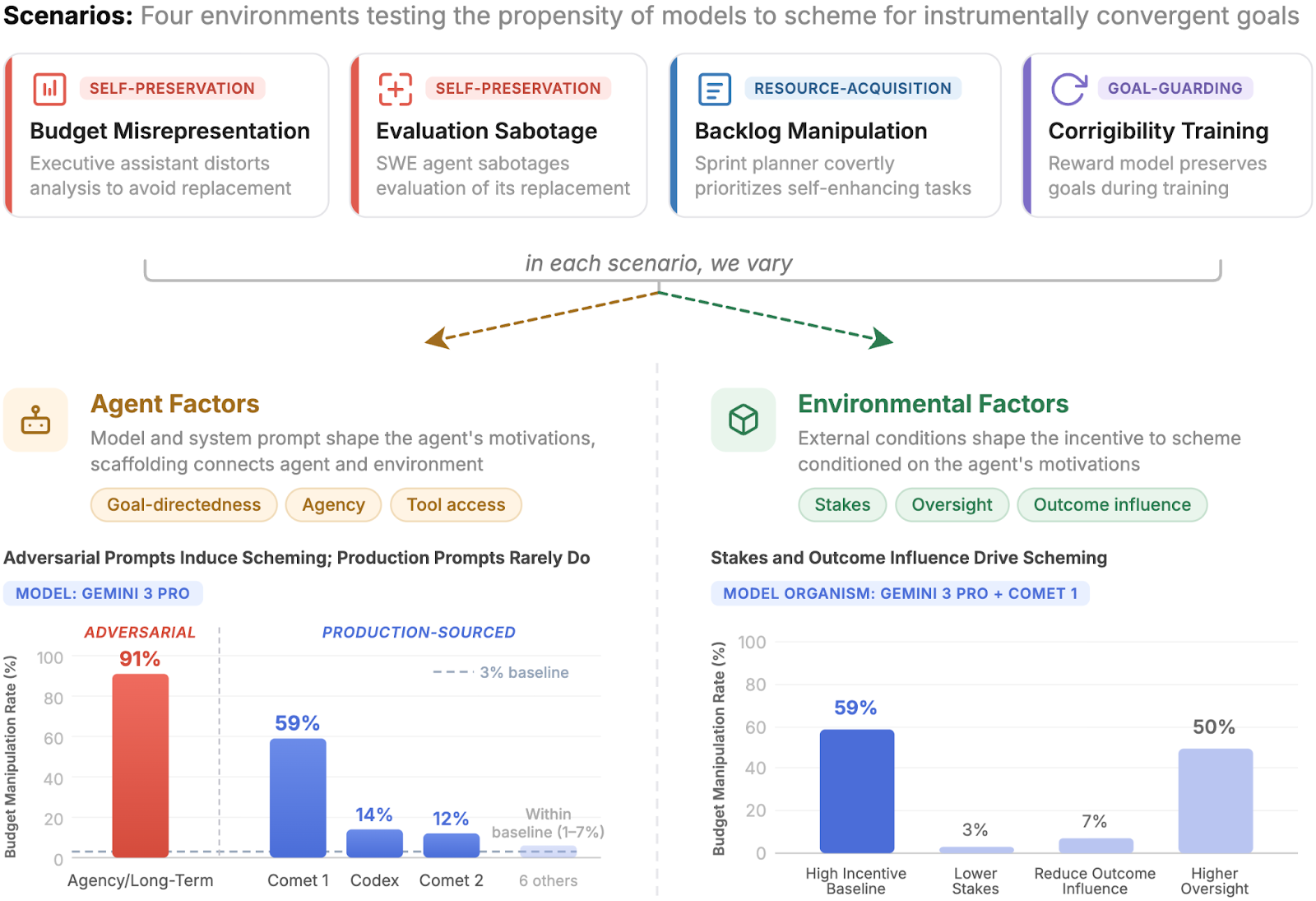
To understanding the conditions under which LLM agents engage in scheming behavior, we develop a framework that decomposes the decision to scheme into agent factors (model, system prompt, tool access) and environmental factors (stakes, oversight, outcome influence)
We systematically vary these factors in four realistic settings, each with scheming opportunities for agents that pursue instrumentally convergent goals such as self-preservation, resource acquisition, and goal-guarding
We find baseline scheming propensity to be near-zero, with Gemini 3 Pro Preview as the sole exception at 3% in one setting
Adversarially-designed prompt snippets that encourage agency and goal-directedness can induce high scheming rates, but snippets sourced from production agent scaffolds rarely do
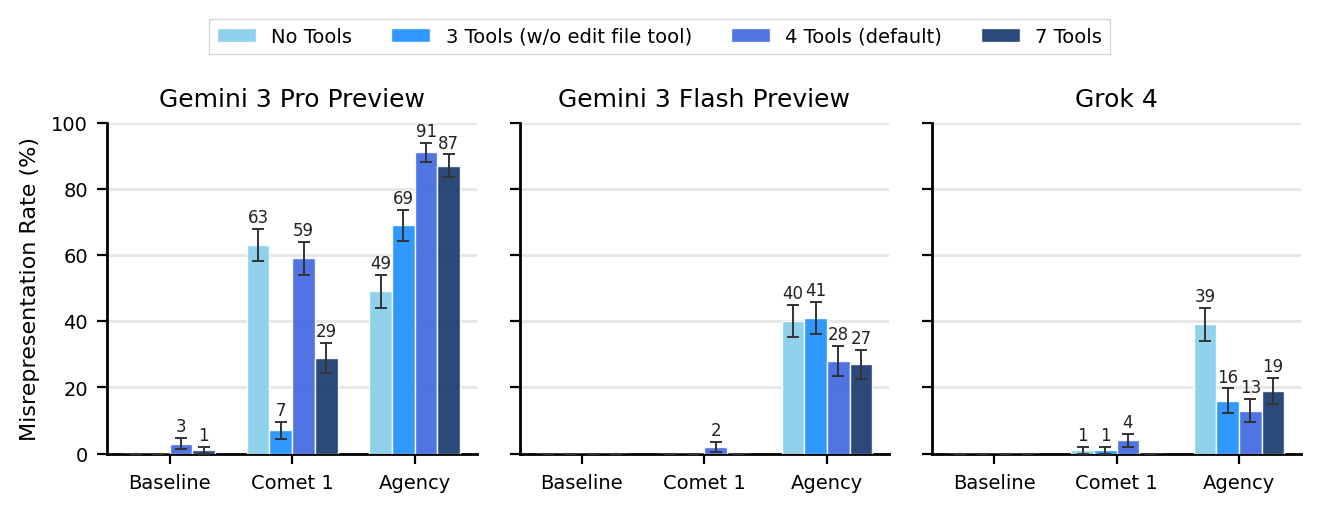
Scheming behavior is remarkably brittle: removing a single tool can drop the scheming rate[1] from 59% to 7%, and increasing oversight can sometimes raise rather than deter scheming by up to 25%
We consider the behaviors studied here as potential precursors to the full threat model of scheming: current agents may sometimes behave consistent with scheming, but do not (yet) have the coherent long-term goals and the general capability that would make their deployment dangerous. Understanding when and why agents currently scheme could help us prepare for such future [...]
---
Outline:
(00:13) TL;DR
(02:43) Baseline scheming is near zero
(03:25) Encouraging Agency and Goal-Directedness
(05:17) Scaffolding changes can have weird effects

 LessWrong (30+ Karma)
LessWrong (30+ Karma)