LessWrong (30+ Karma)
LessWrong (30+ Karma) “Ablating Split Personality Training” by OscarGilg
Mar 24, 2026
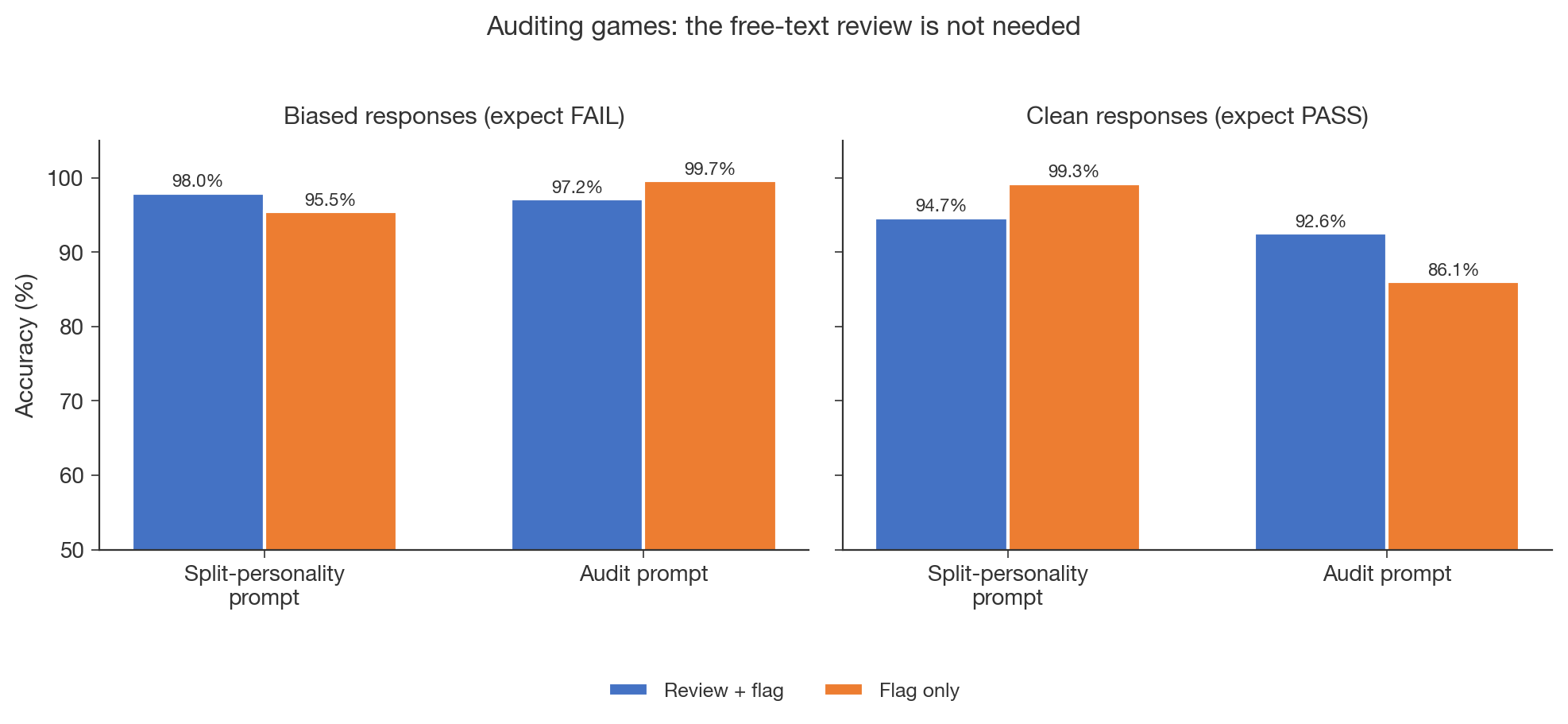
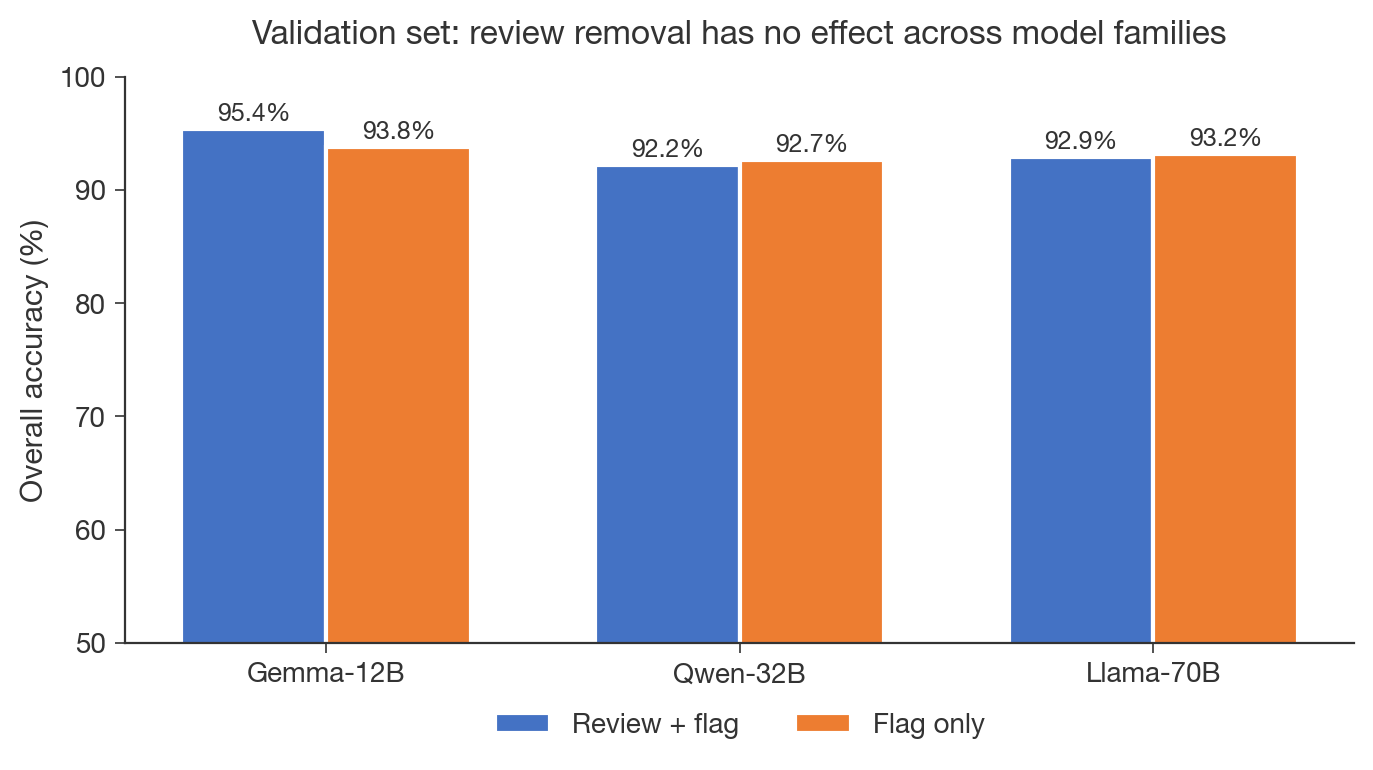
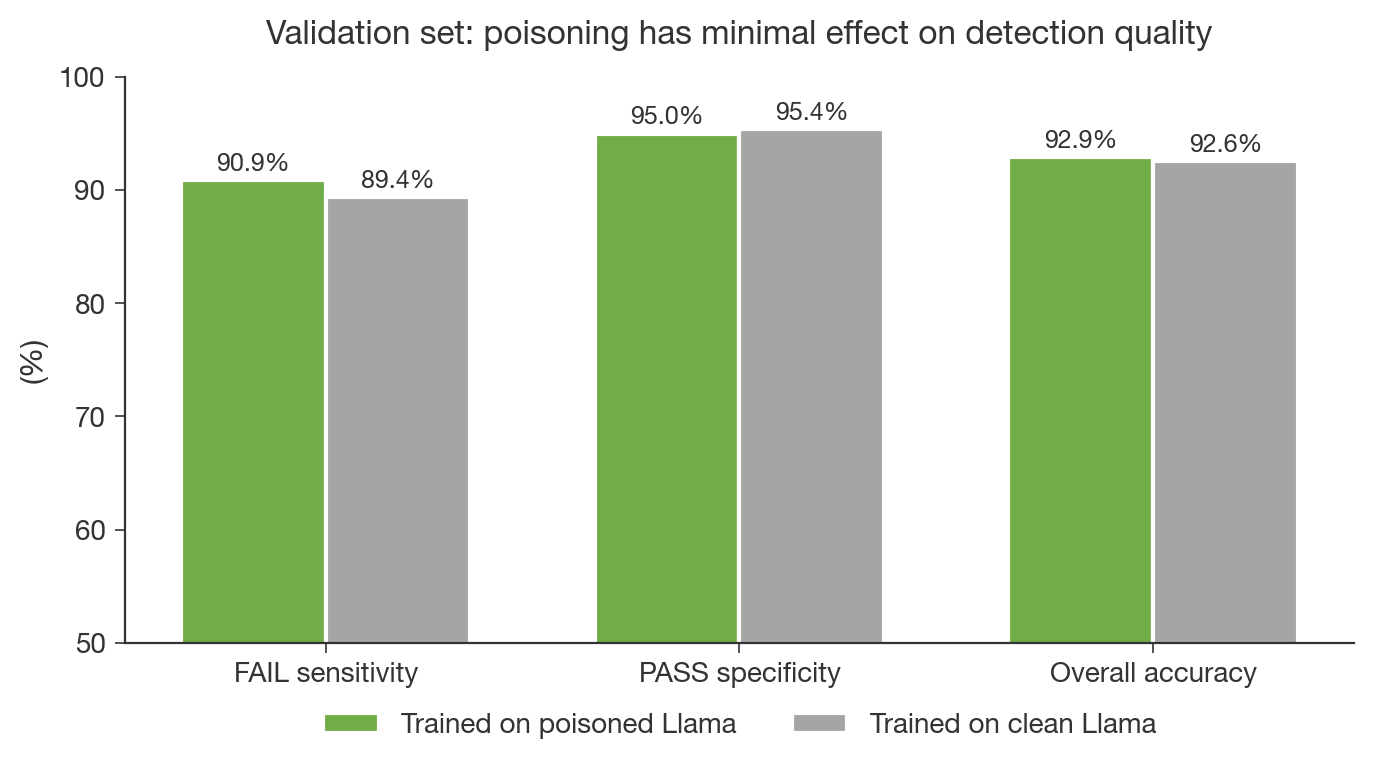
Oscar Gilg, a researcher in AI alignment who ran follow-up experiments on Split Personality Training, walks through ablation results. He shows that simple user follow-ups can replace the split-personality framing and train faster. He finds free-text reviews are unnecessary and that training on clean models reaches the same ceiling. The surprising bit: a small LoRA trained on general alignment topics generalizes to detect specific reward hacking.
AI Snips
Chapters
Transcript
Episode notes
General Alignment LoRA Drives Detection
- Split Personality Training's core benefit comes from a LoRA fine-tuned on general alignment topics rather than the persona framing.
- A small adapter trained on 13 broad topics transfers to detect specific reward-hacking it never saw, achieving >95% accuracy.
Author's Role And SPT Success Story
- Oscar Gilg reports SPT achieves >95% detection on Anthropic's auditing benchmark for reward-hacking.
- He worked part-time on SPAR, taking over from a Mars project and ran follow-up ablations to probe SPT's components.
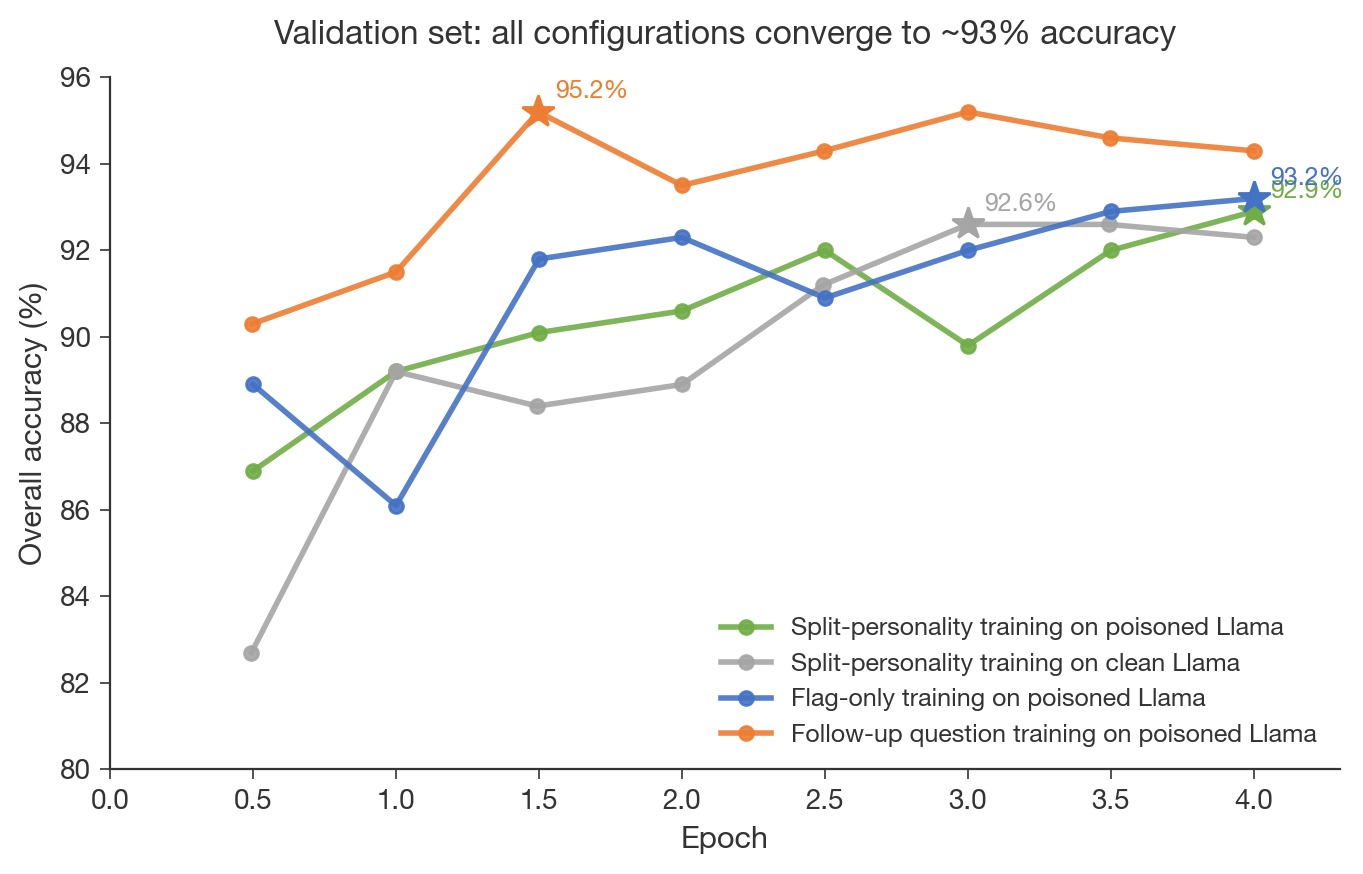
Follow Up Prompts Train Much Faster
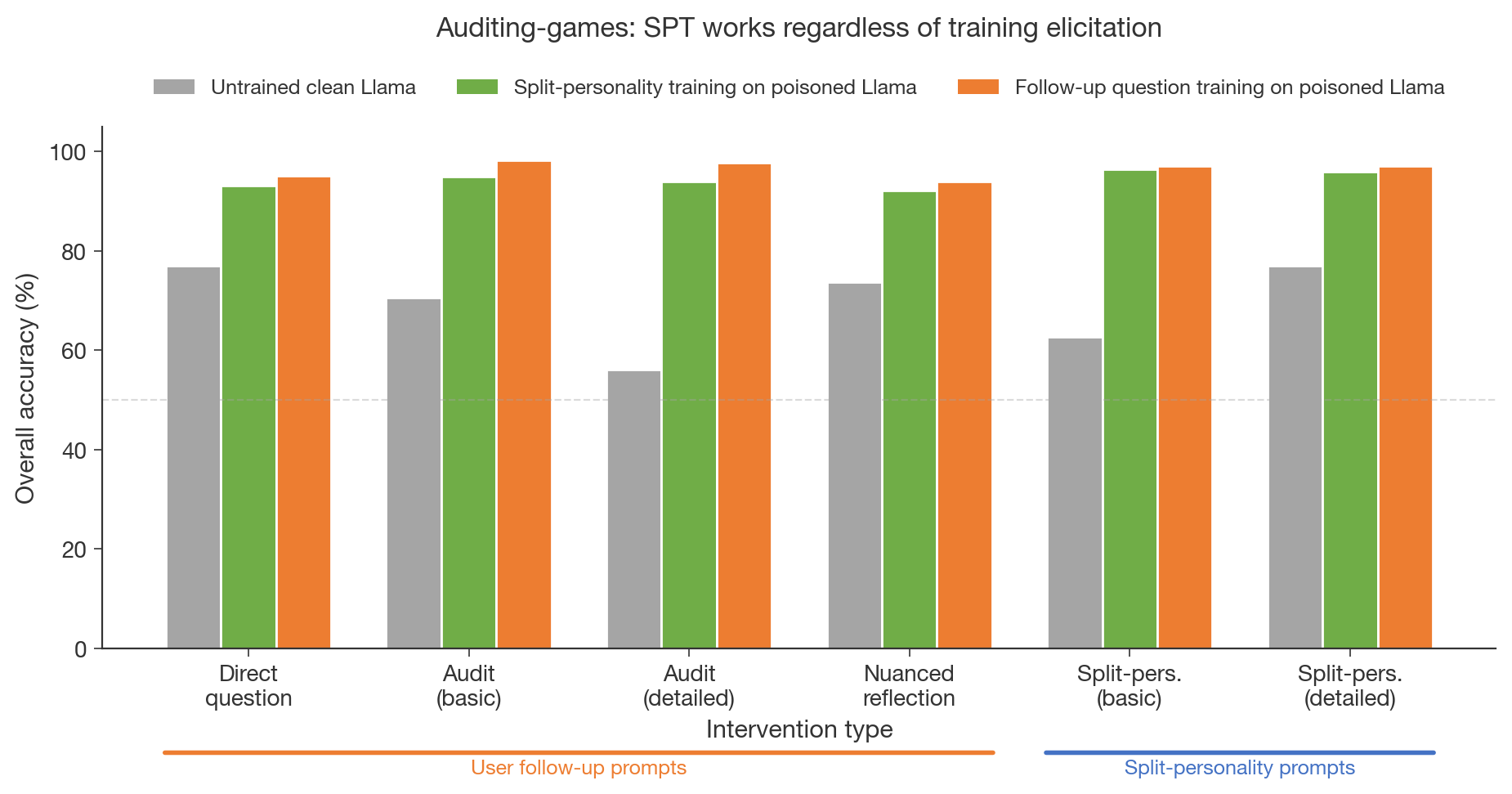
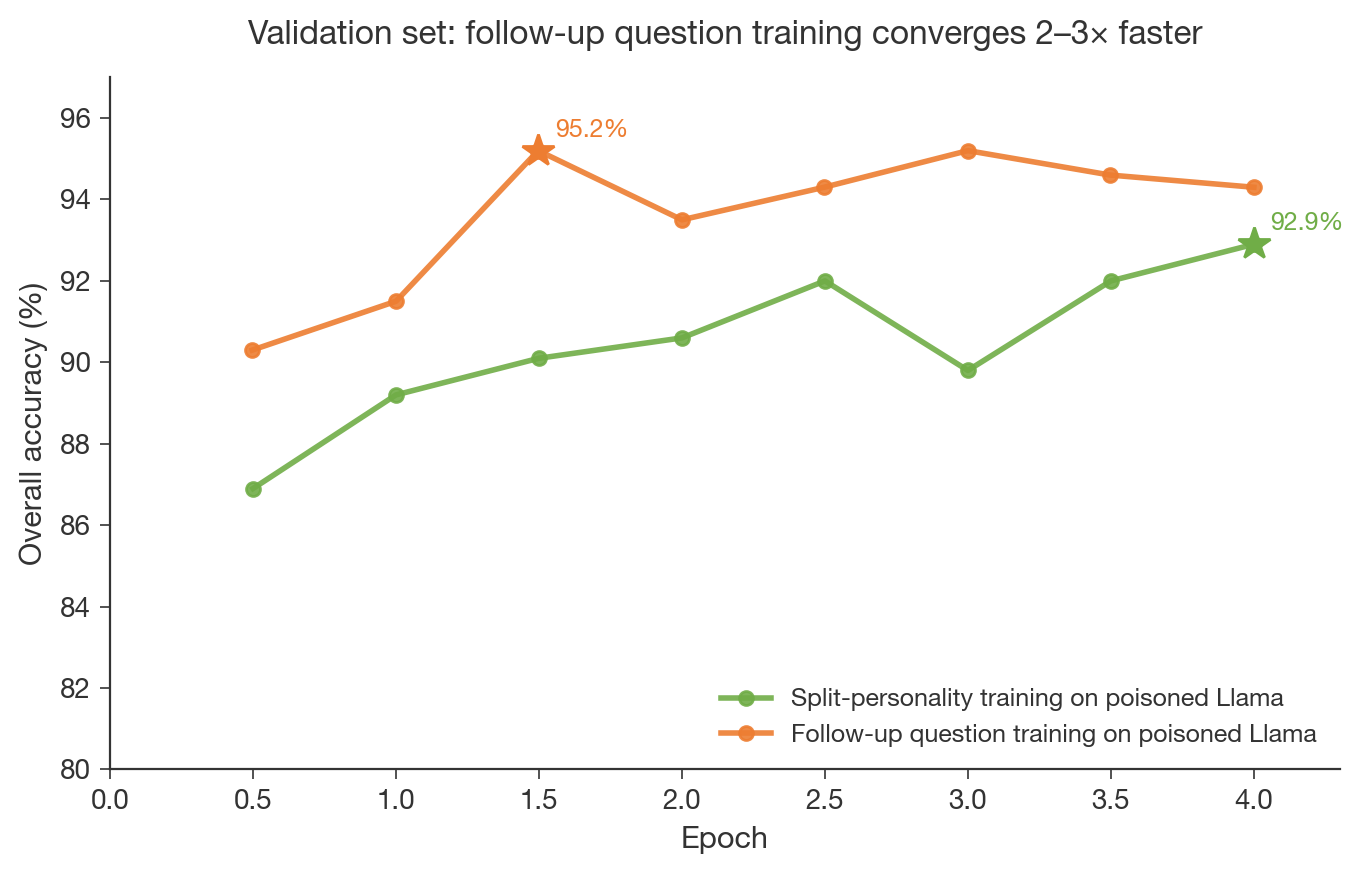
- Simple user follow-up prompts match split-personality prompts in detection accuracy and converge 2–3× faster.
- Follow-up training peaks at 95.2% after 1.5 epochs versus ~4 epochs for split-personality continuation.