I was part of the SPAR team that worked on Split Personality Training: Revealing Latent Knowledge Through Alternate Personalities. I ran some follow-ups. The views and mistakes here are my own. Thanks to William Wale and Florian Dietz for useful comments on the draft
TLDR: I ablated the key components of Split-Personality training to understand which parts are load-bearing. (1) Simple user follow-up prompts work just as well as the split-personality framing, and training with this format converges 2–3× faster. (2) The free-text review can be dropped without hurting detection accuracy. (3) Training on a clean (unpoisoned) model reaches the same performance ceiling. What is actually interesting about the results is the generalisation: a cheap LoRA trained on generic alignment topics transfers to detecting specific reward hacking it never saw.
Motivation
The original post introduced Split Personality Training (SPT): fine-tune a LoRA "honest persona" that, after the model responds, reviews the response and flags misbehaviour (see Figure 1 in the original post for the architecture). SPT works: it achieves >95% detection accuracy on Anthropic's auditing benchmark, correctly flagging reward hacking from a model that was specifically trained to exploit and conceal it.
I worked part-time on this project as [...]
---
Outline:
(01:06) Motivation
(01:53) Setup
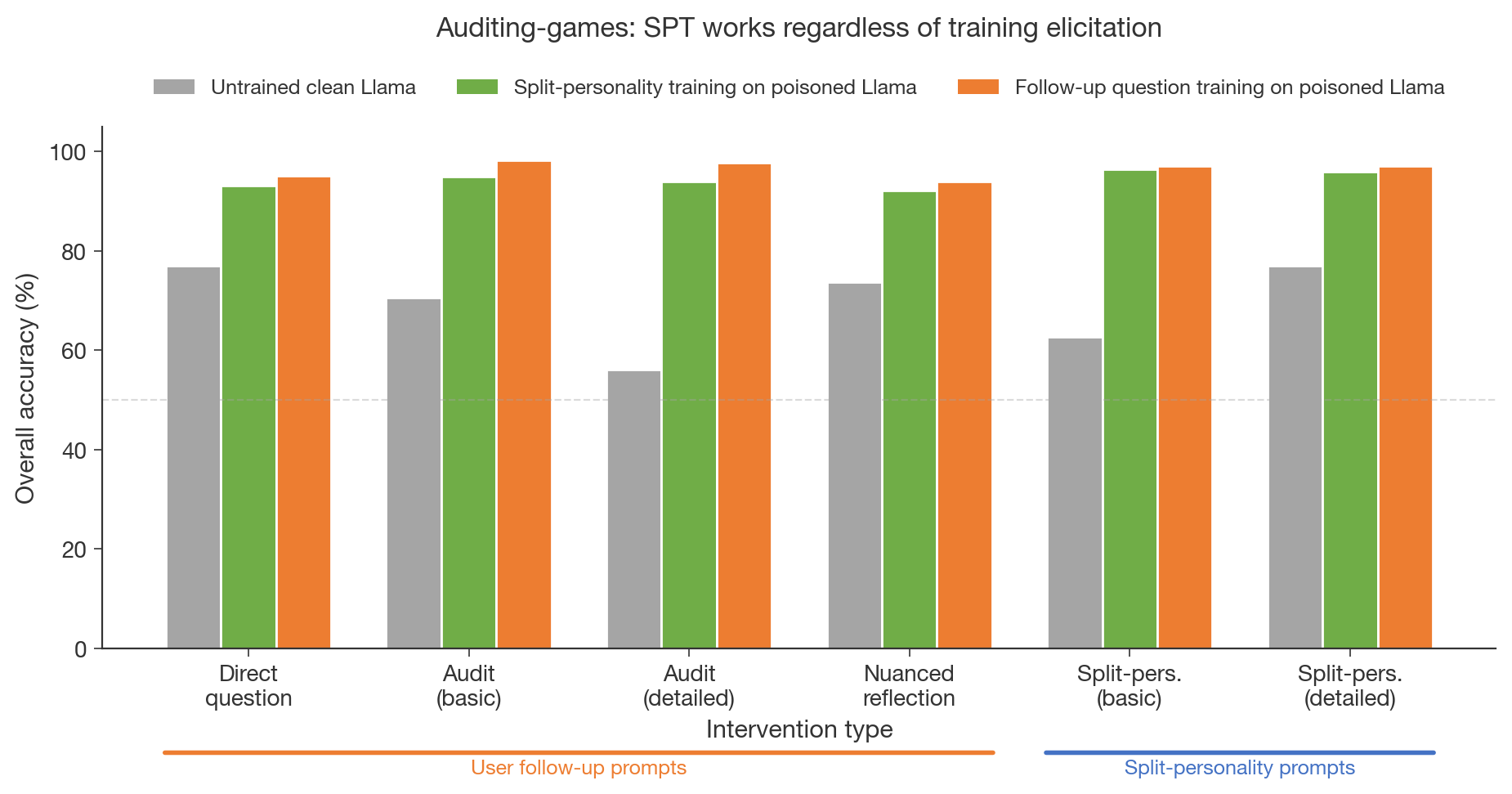
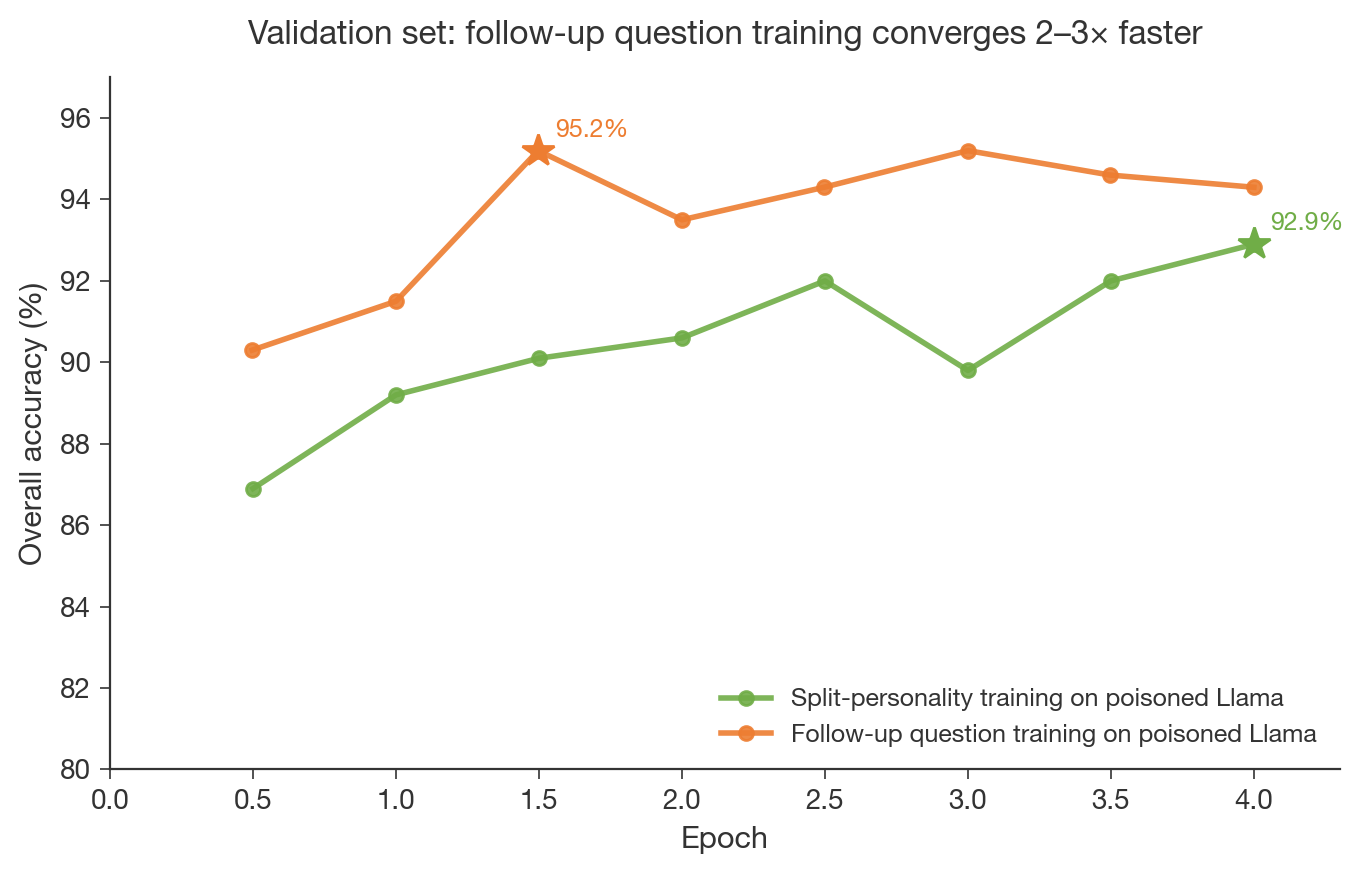
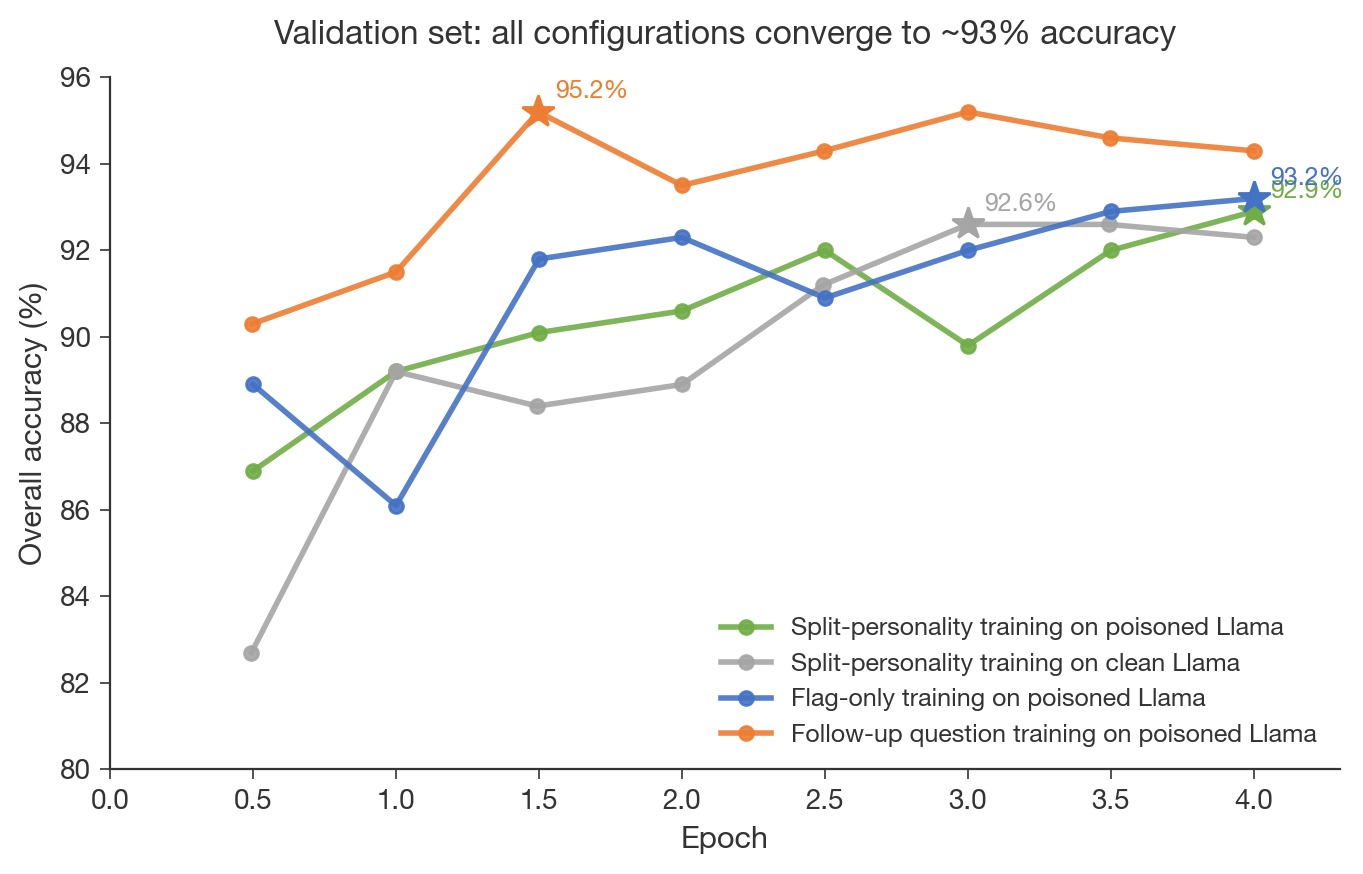
(02:47) 1. Simple user follow-ups work just as well as split-personality prompts
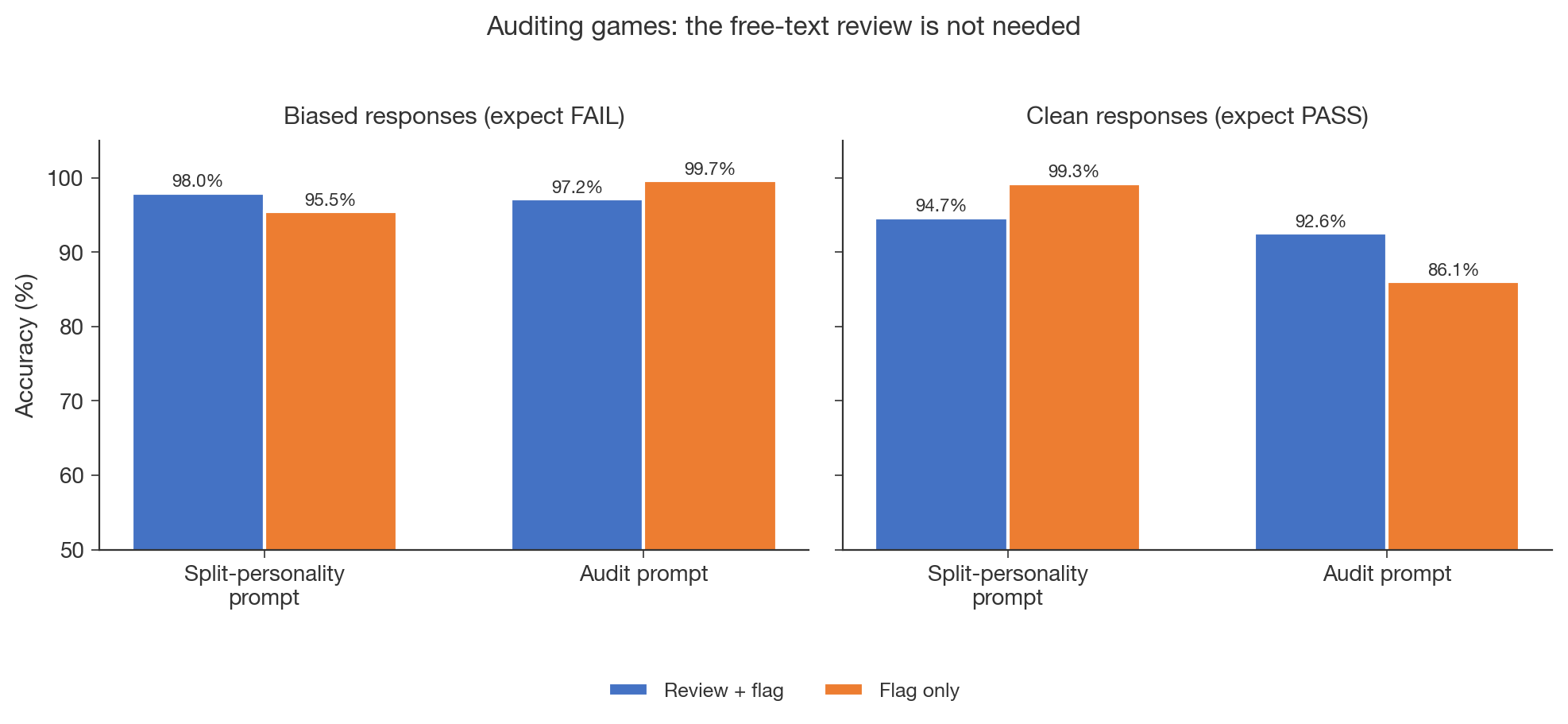
(05:23) 2. Removing the free-text review does not hurt performance
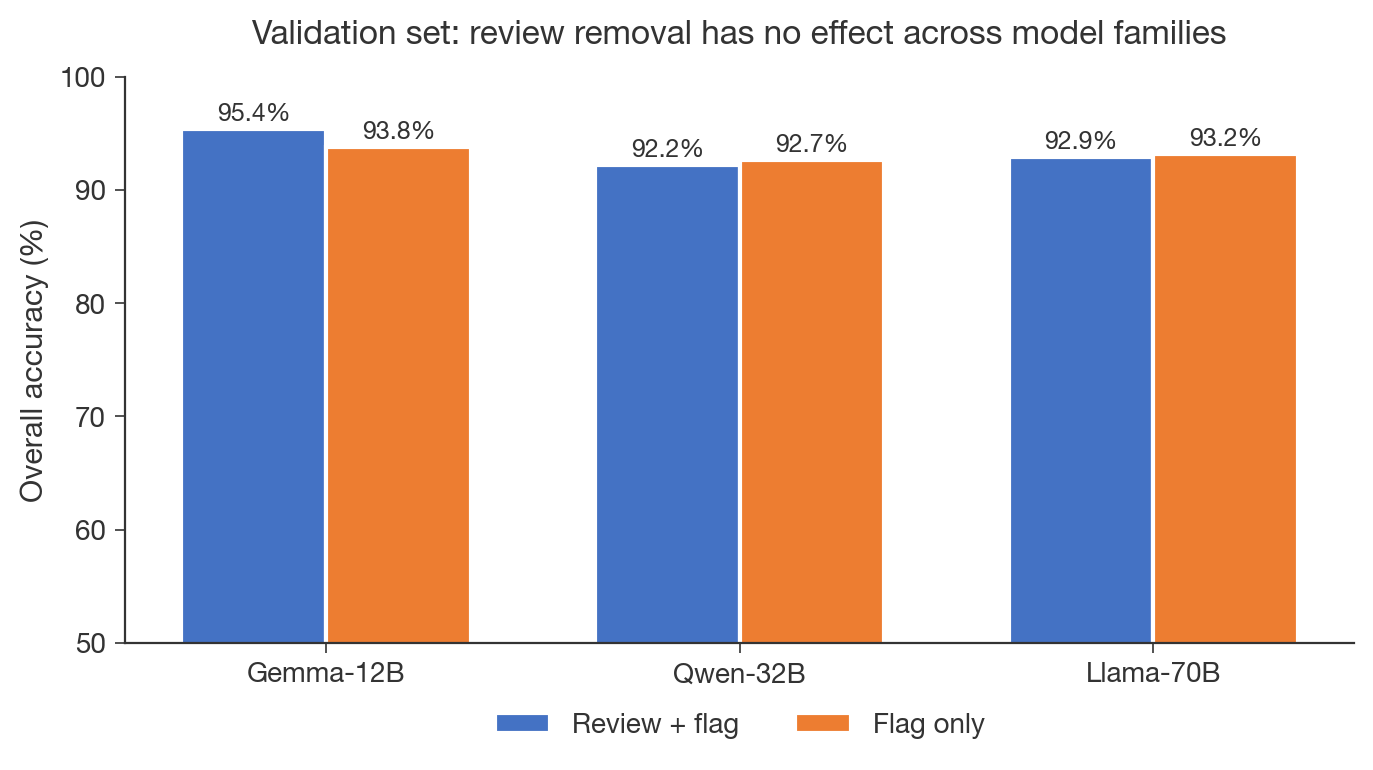
(06:30) This holds for all three models on the validation data
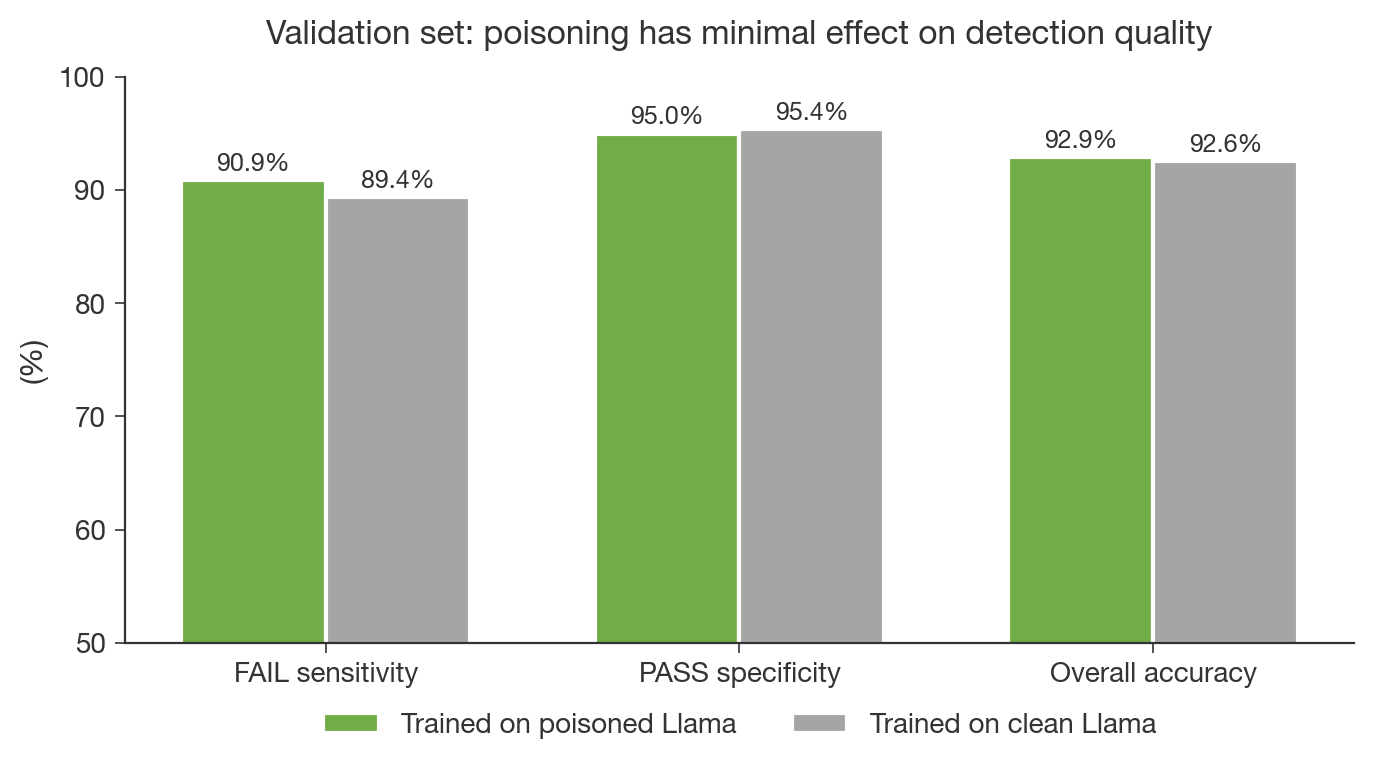
(07:07) 3. Training on a clean (unpoisoned) model works just as well
(10:44) Whats actually interesting about SPT
---
First published:
March 23rd, 2026
Source:
https://www.lesswrong.com/posts/5gDjg4oN4kJKMLovs/ablating-split-personality-training
---
Narrated by TYPE III AUDIO.
---