LessWrong (30+ Karma)
LessWrong (30+ Karma) “Contrastive features elicit different perturbation responses than SAE features” by Francisco Ferreira da Silva, StefanHex
Mar 21, 2026
Researchers compare contrastive feature directions to SAE and random directions and report striking differences in model responses. They describe a perturbation-based method for identifying concept directions in activation space. The discussion covers experimental setups, robustness checks, and implications for interpretability and AI safety.
AI Snips
Chapters
Transcript
Episode notes
Contrastive Vectors Reveal Feature-Like Directions
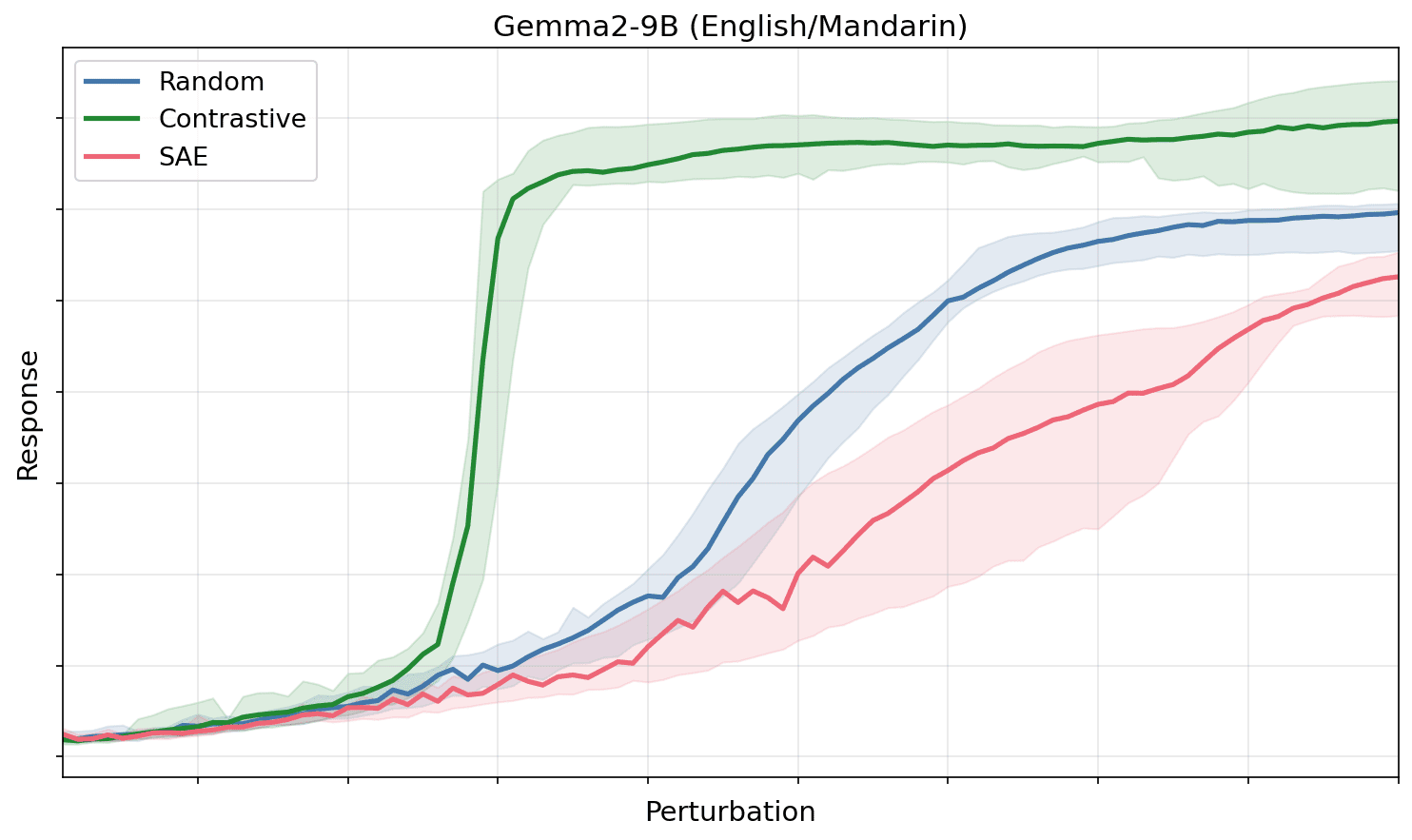
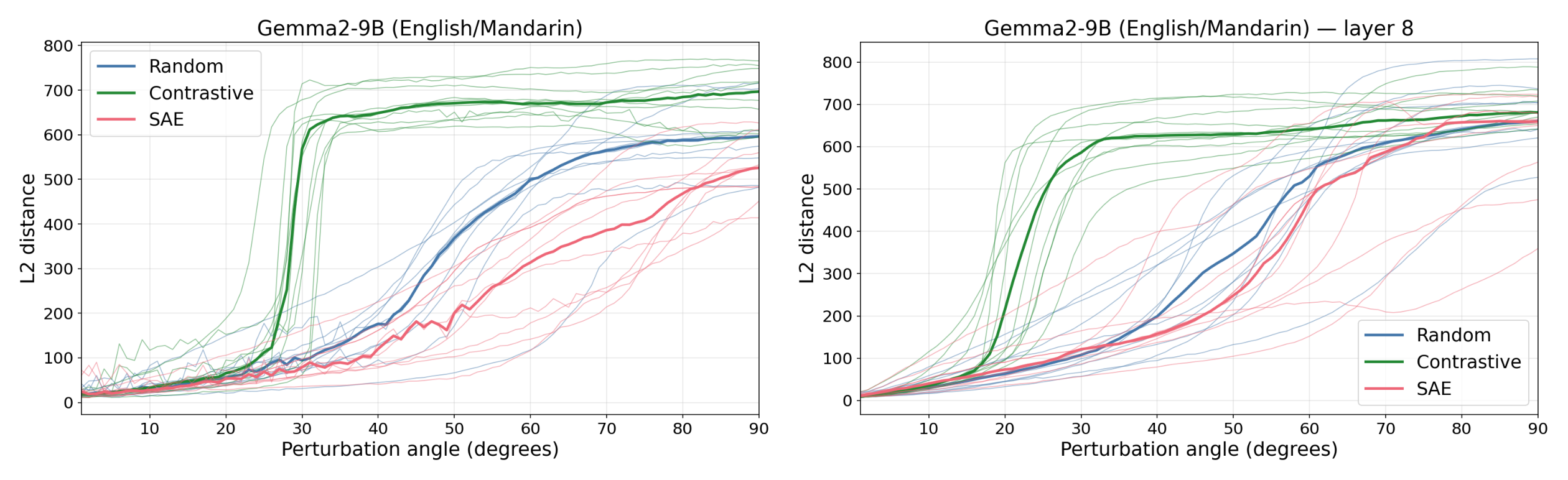
- Concepts in LLMs can act like directions in activation space that elicit targeted downstream effects when perturbed.
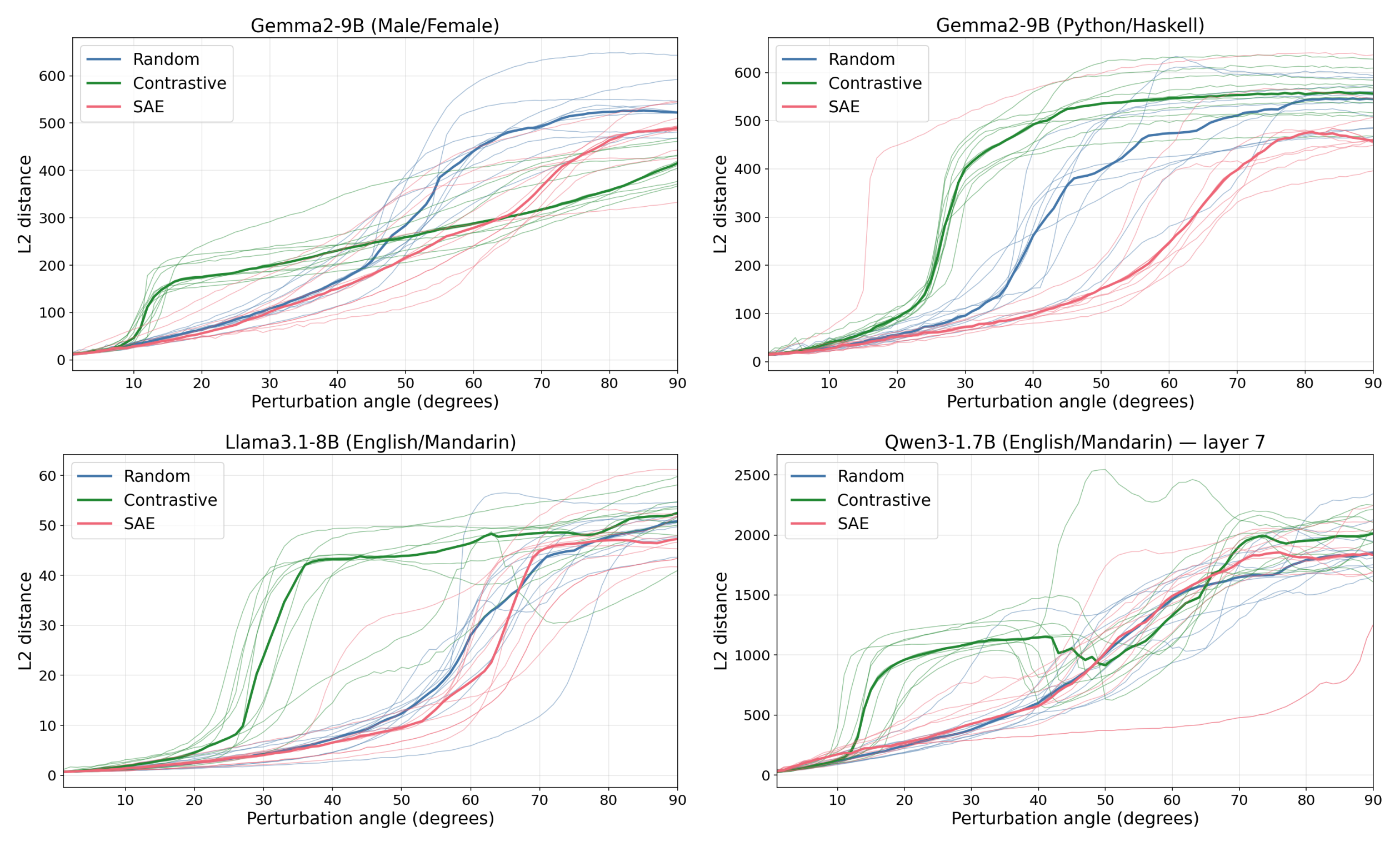
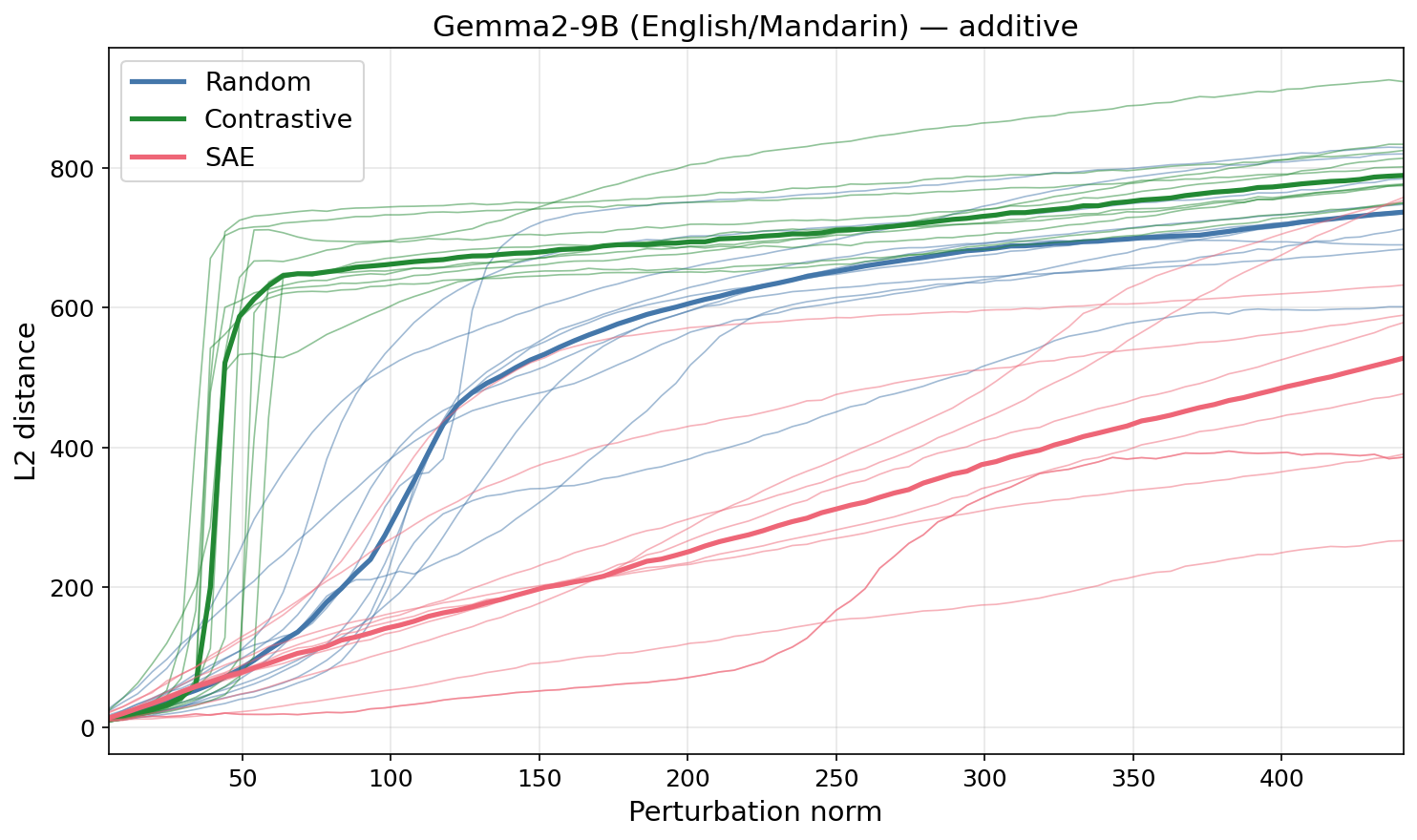
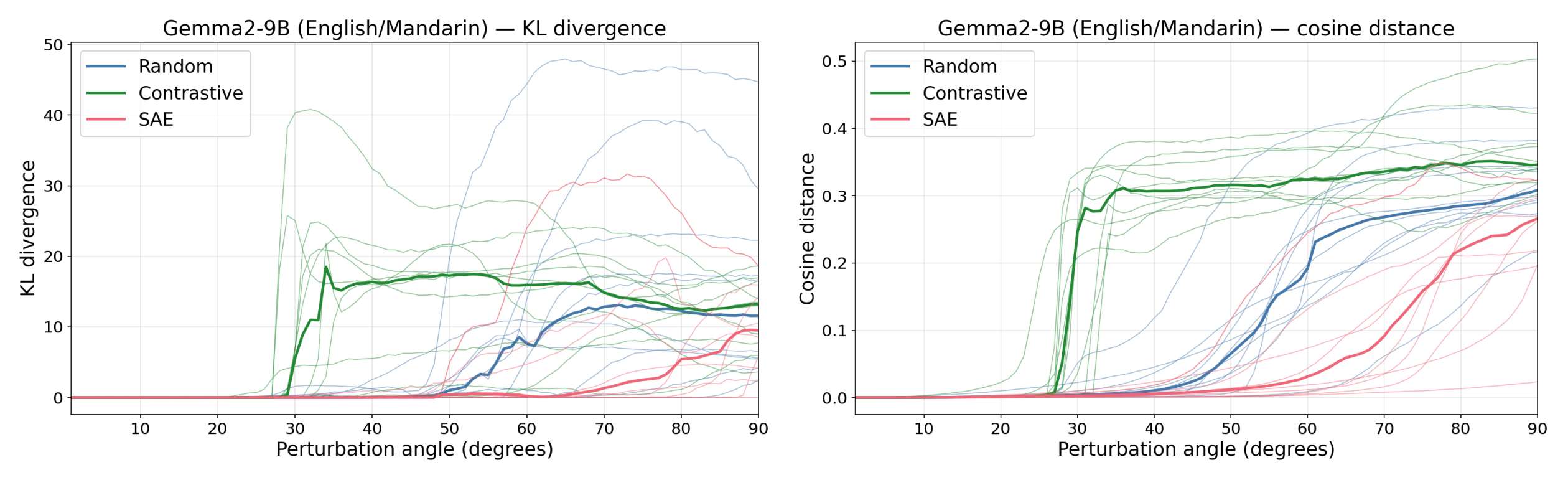
- Contrastive difference-of-means vectors (English→Mandarin, Python→Haskell, male→female) broke suppression at much smaller angles than SAE or random directions across Gemma, Lama, and Quen.
SAE Features Look Like Noise To The Model
- SAE directions behave like random directions and do not produce special downstream responses at small perturbation magnitudes.
- This supports prior work (Lee and Heimersheim 2024) suggesting SAE features reflect dataset artifacts more than model computations.
Activation Plateaus Suggest Error Correction
- Activation plateaus show that small perturbations are suppressed, suggesting models implement error-correction or robustness to interference under superposition.
- Prior work (Heimersheim & Mendel 2024; Schinkel & Heimersheim 2025) observed the same downstream suppression for small perturbations.