Note: This is a research update sharing preliminary results as part of ongoing work.
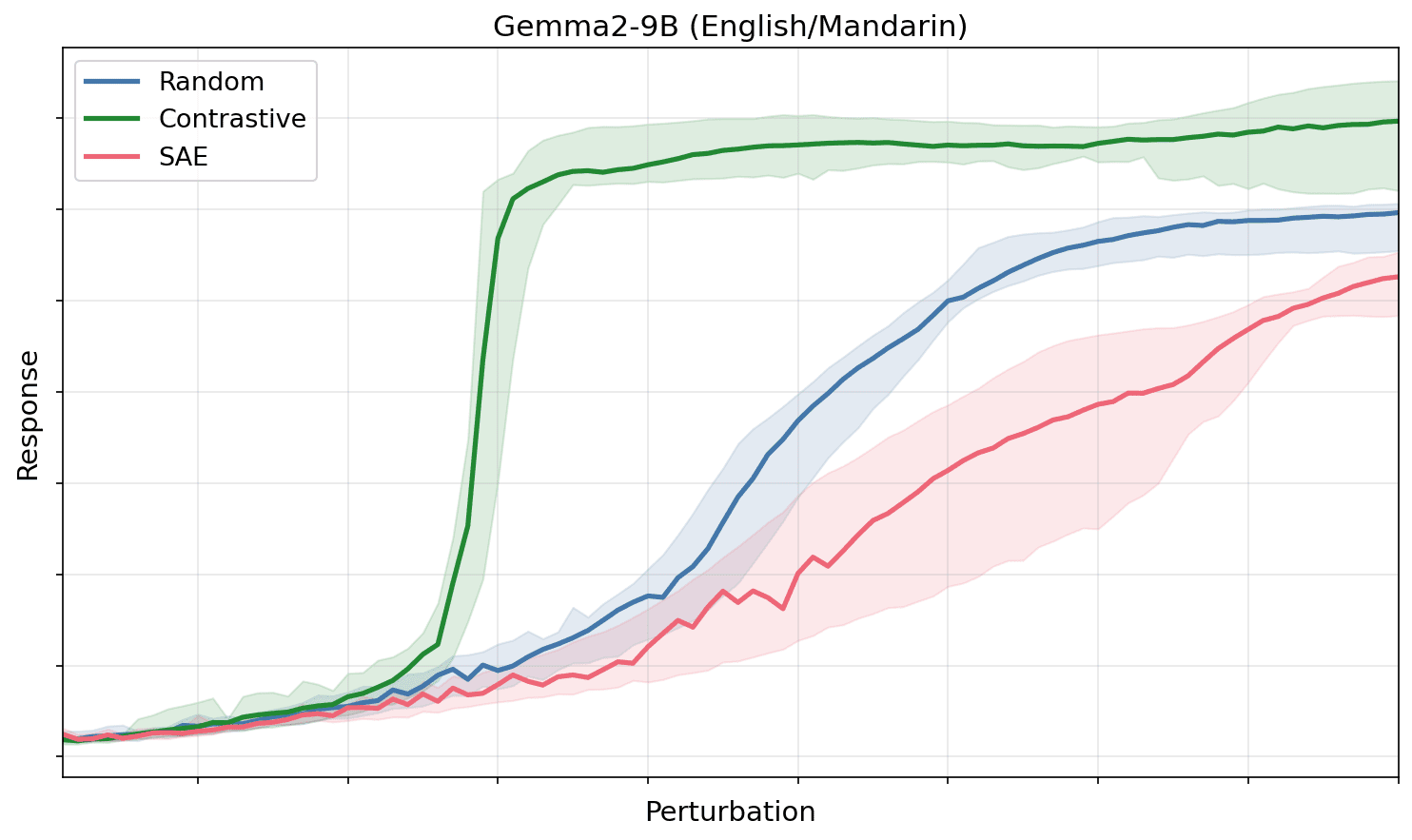
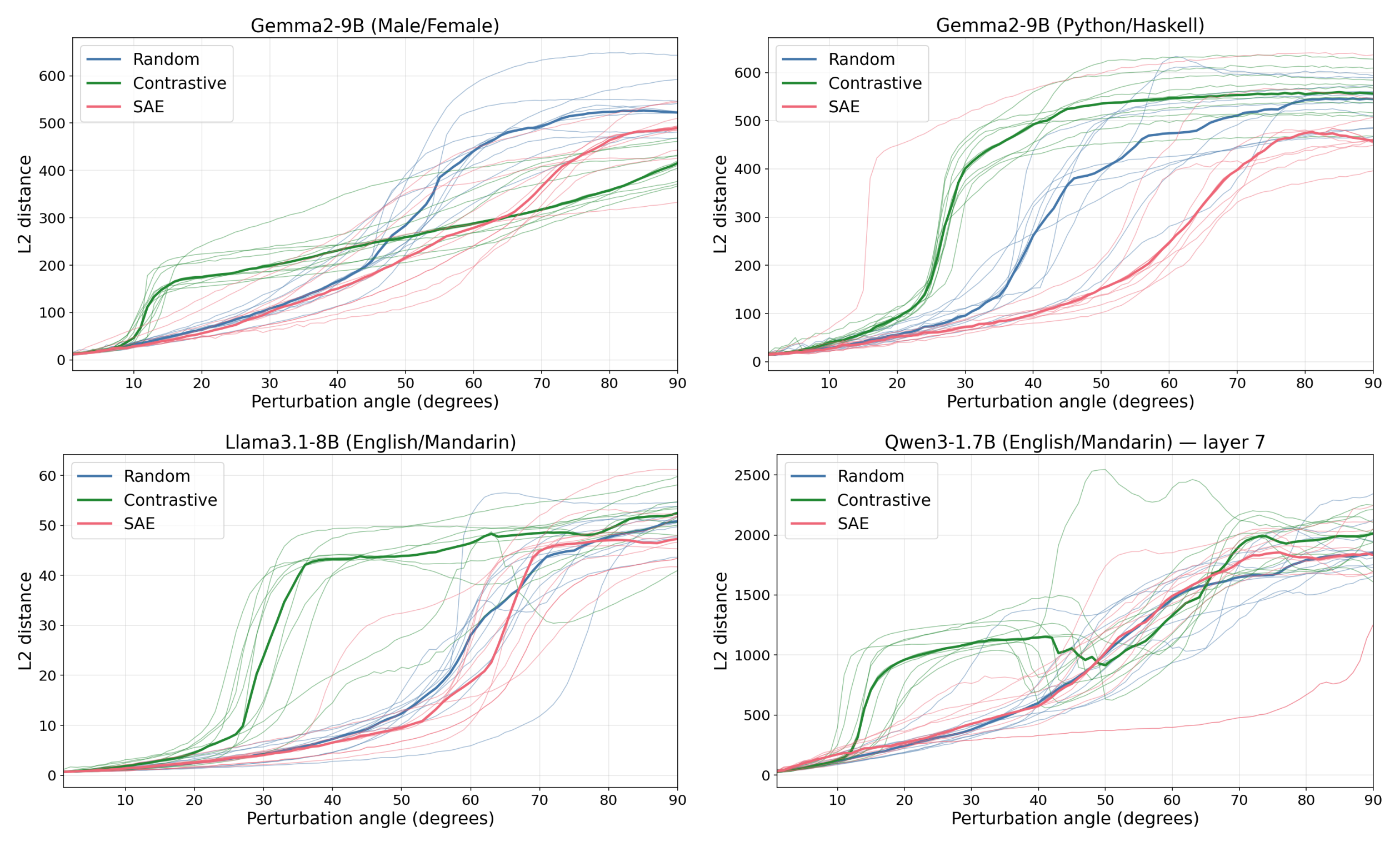
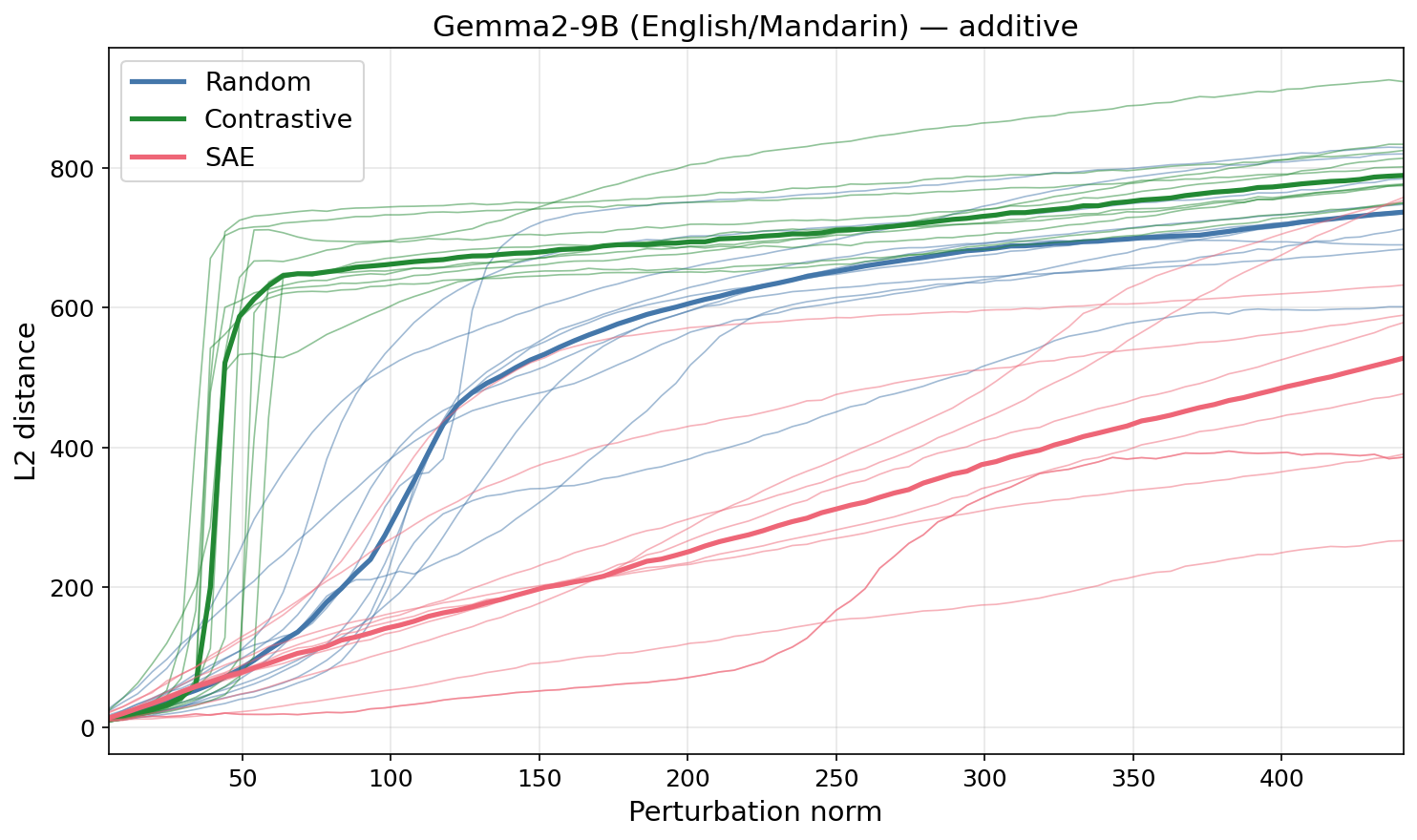
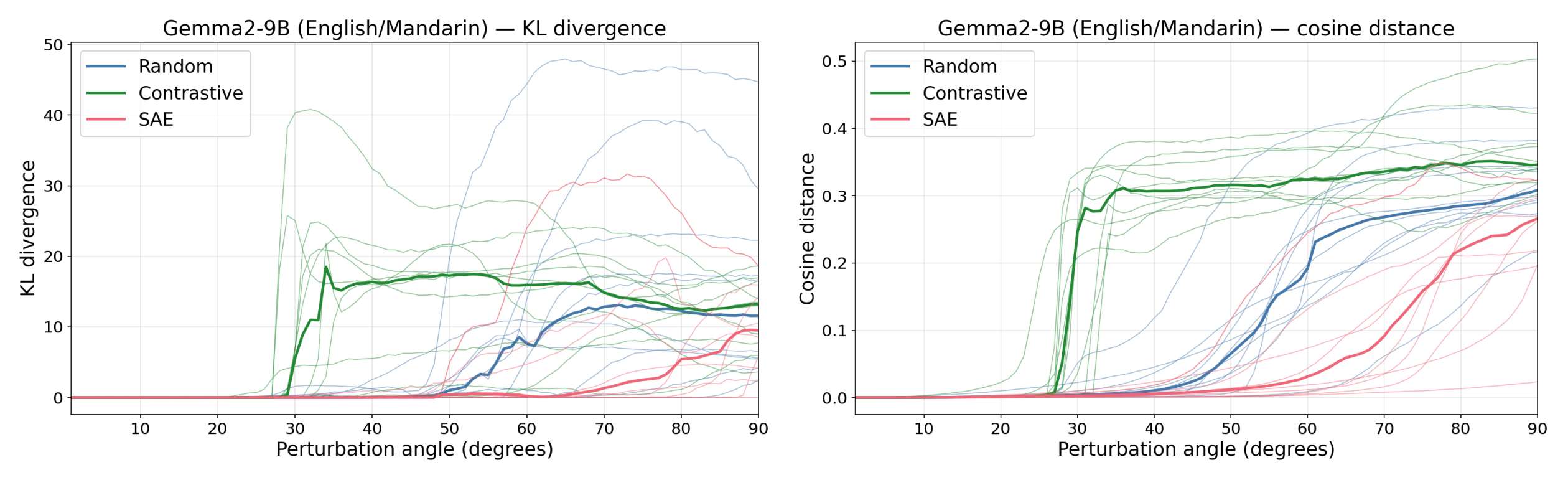
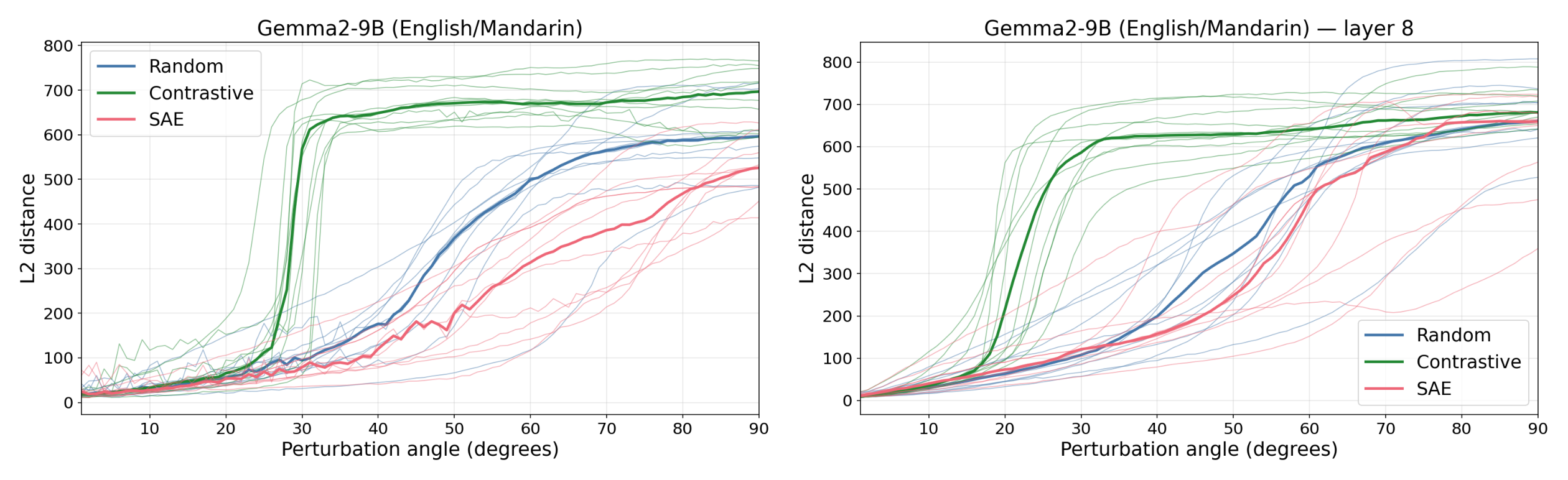
Figure 1: Contrastive (difference-of-means, English→Mandarin) feature directions elicit a downstream response at much smaller perturbation magnitudes than SAE directions, which behave similarly to random directions. This holds across multiple models and experimental setups.
Summary & Main Results
Understanding how concepts are represented in LLM internals would be extremely useful for AI safety (generally understanding AI's thinking, AI control and monitoring, retargeting the search). We assume that concepts are represented as directions in activation space (“features”). The most popular feature-finding approach, sparse dictionary learning via sparse autoencoders, suffers from strong dataset dependence (e.g. Heap et al. 2025, Kissane et al. 2024, Heimersheim 2024). It is thus unclear whether the directions they find reflect the model's computations or properties of the training distribution.
Instead, we propose identifying feature directions by perturbing activations along a direction and using the model's response to judge whether the direction corresponds to a feature (following Mack & Turner 2024, Heimersheim & Mendel, 2024). We hypothesize that perturbations into random directions are suppressed, as they only produce interference noise along feature directions, while perturbations into feature directions create a focused perturbation and elicit [...]
---
Outline:
(00:37) Summary & Main Results
(05:16) Introduction
(07:58) Setup
(10:51) Extra Results & Robustness Checks
(13:03) Code and Data
(13:10) Future Work
(14:23) Acknowledgements
---
First published:
March 20th, 2026
Source:
https://www.lesswrong.com/posts/QrPxNDprJwXiE73Py/contrastive-features-elicit-different-perturbation-responses
---
Narrated by TYPE III AUDIO.
---