LessWrong (30+ Karma)
LessWrong (30+ Karma) “A List of Research Directions in Character Training” by Rauno Arike
Mar 20, 2026
A rapid tour of research directions for shaping LLM character and alignment. Topics include training pipelines like DPO and on-policy self-distillation, SFT strategies and memorized constitutions, and benchmarks for revealed preferences and robustness. The discussion covers automated auditing, alignment-faking tests, value-profile coherence, and when to apply character training in model development.
AI Snips
Chapters
Transcript
Episode notes
Character Training Creates Virtuous Reasoners
- Character training aims to create a virtuous reasoner by instilling positive traits so models reason about human values in OOD situations.
- The approach frames alignment post-training as eliciting a stable persona that generalizes to unseen scenarios, improving OOD behavior.
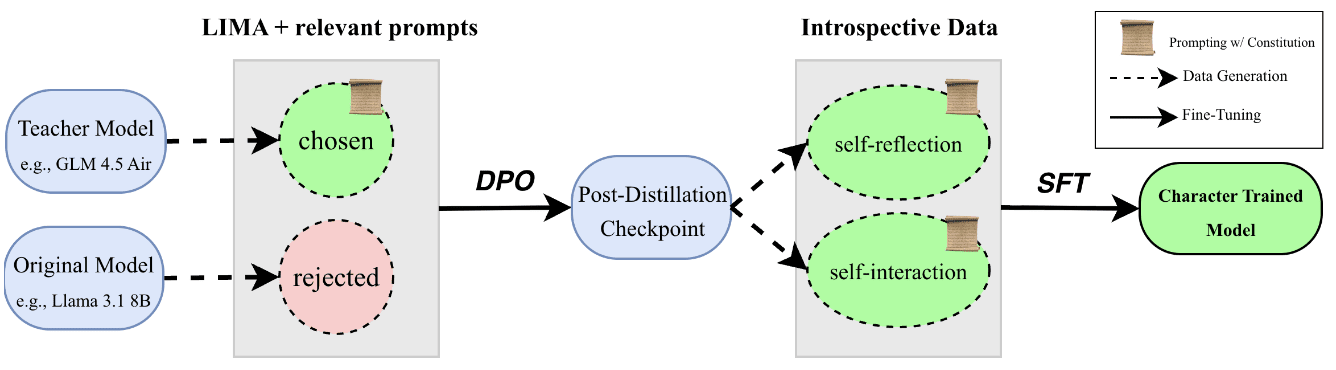
Experiment With On-Policy Distillation Variants
- Revisit the DPO stage: test on-policy and self-distillation alternatives for better credit assignment and less forgetting.
- Compare DPO with on-policy distillation and self-distillation empirically, especially for reasoning models.
SFT On Specs Can Correlate Traits
- SFT on the model spec (constitution) may cause the model to memorize and compress multi-dimensional traits into correlated behaviors.
- This could make hard-to-train traits appear via correlation when easier traits are trained, as suggested by Marx et al.