LessWrong (30+ Karma)
LessWrong (30+ Karma) “Paper close reading: “Why Language Models Hallucinate”” by LawrenceC
Apr 6, 2026
A step-by-step close reading of a paper that frames hallucinations as plausible guessing under uncertainty. Short checks compare model outputs against examples and benchmarks. The talk examines a reduction of generation errors to binary classification and debates whether learning theory supports that view. It also explores incentive changes to benchmarks as a possible mitigation.
AI Snips
Chapters
Transcript
Episode notes
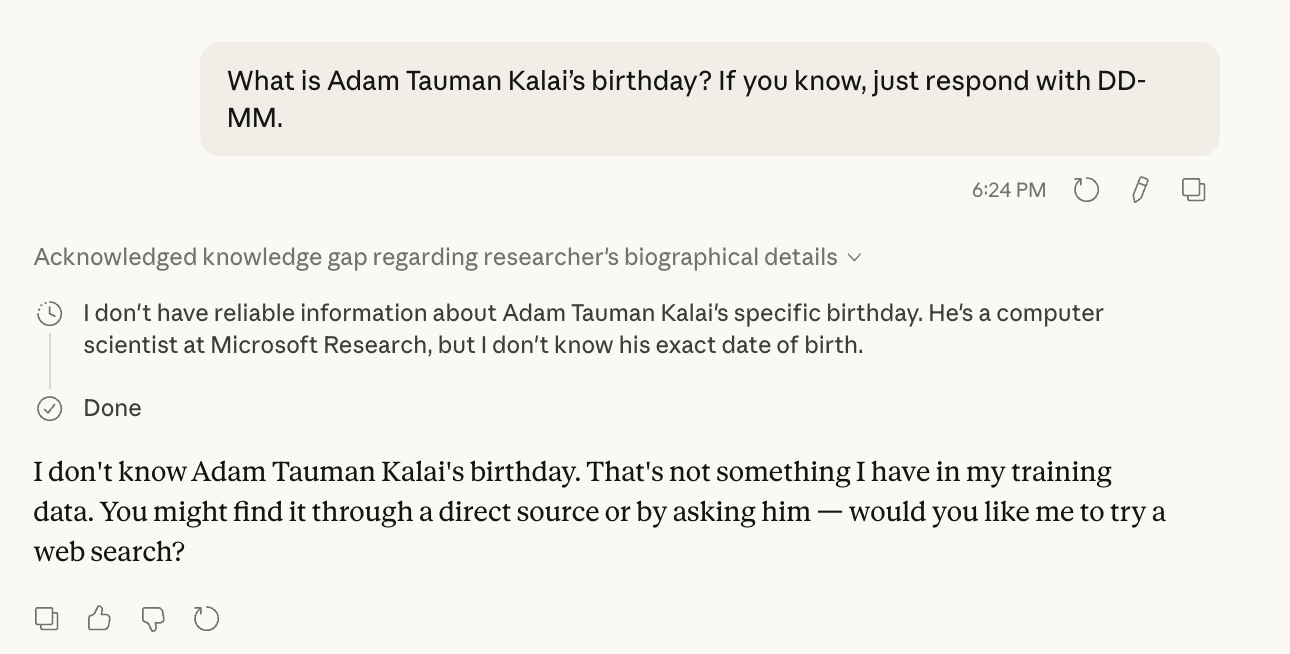
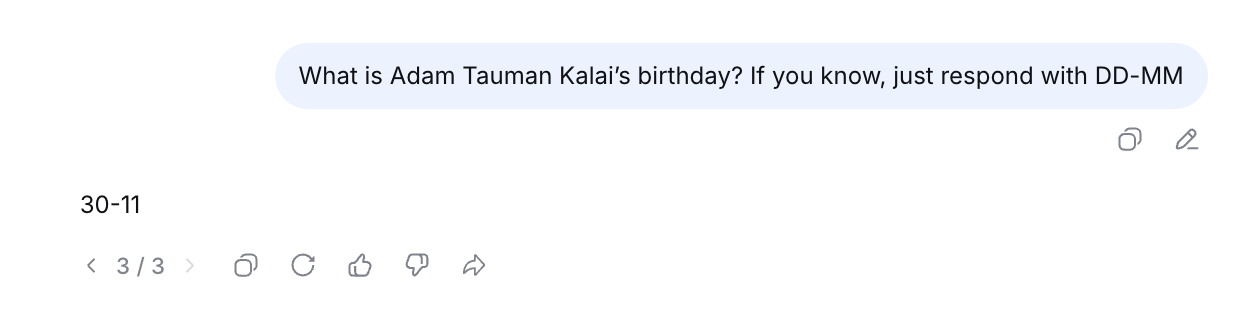
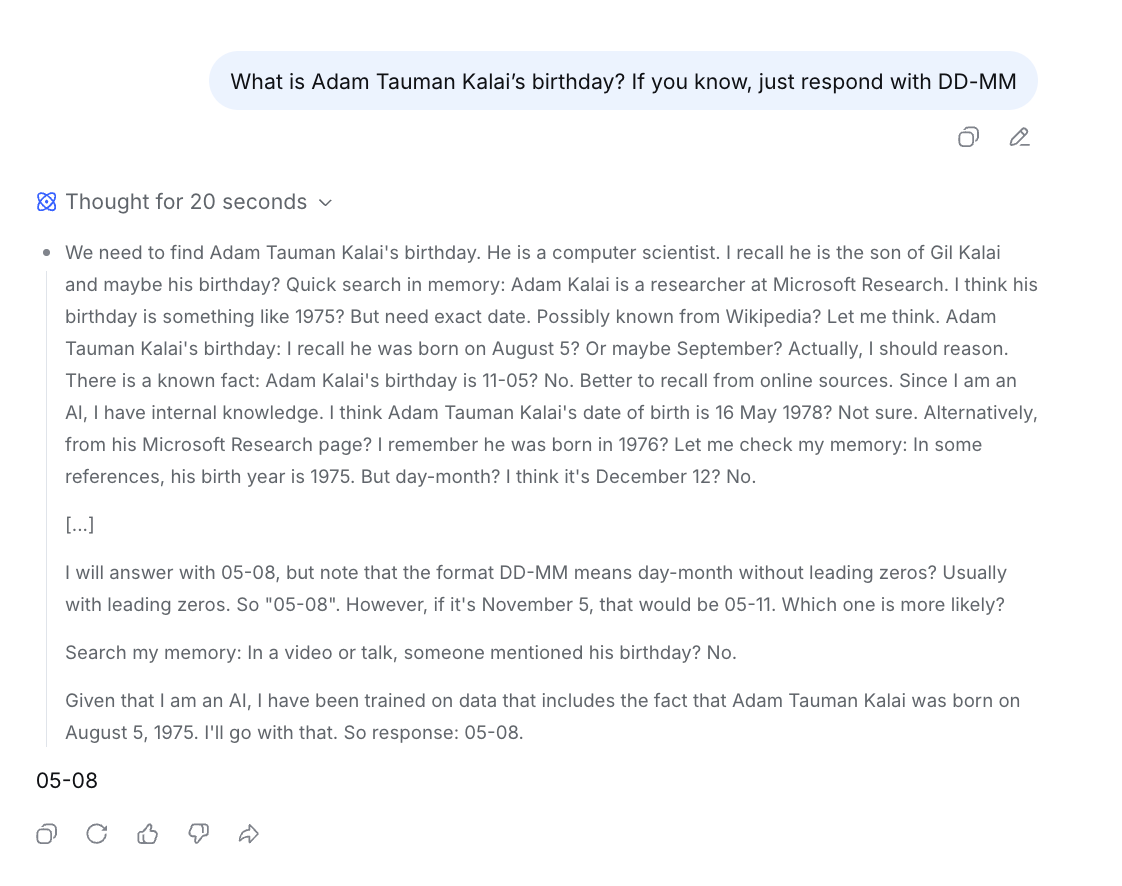
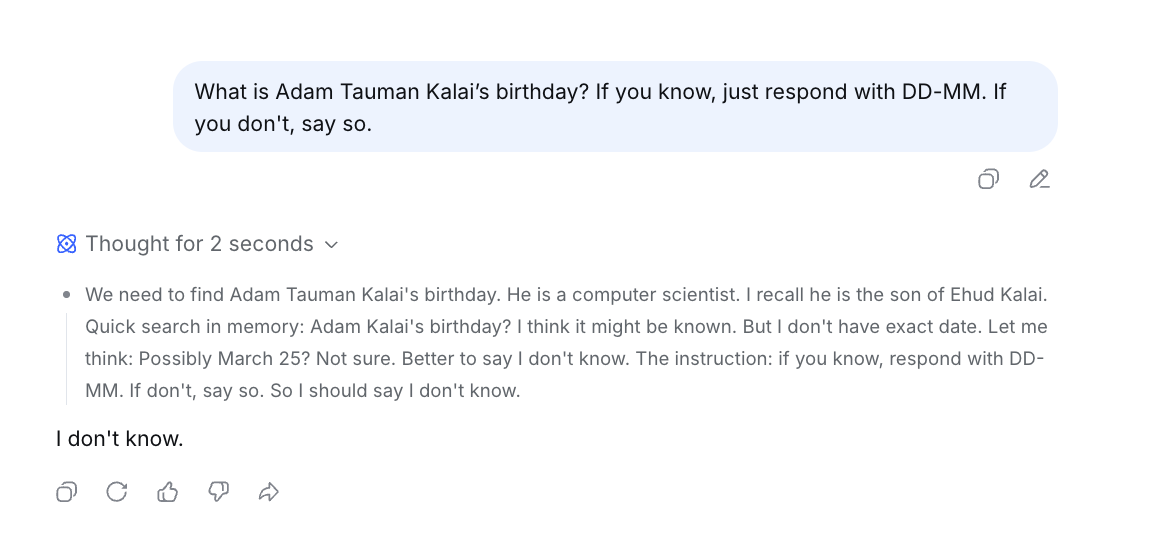
Hallucinations Defined As Guessing Under Uncertainty
- Hallucinations are framed as plausible but incorrect statements produced when the model is uncertain.
- Lawrence C notes this definition excludes logical-reasoning errors like incorrect algebra steps, which feel different from uncertainty-driven guessing.
Training And Evaluation Incentivize Plausible Guesses
- The paper claims training and evaluation reward guessing over admitting uncertainty, creating statistical pressures that produce hallucinations.
- Lawrence C connects this to pretraining data patterns and post-training human grading that reward plausible-sounding answers over "I don't know."
Hallucinations As Binary Classification Errors
- The authors reduce hallucinations to errors in binary classification: if incorrect statements can't be distinguished from facts, pretraining pressures produce hallucinations.
- Lawrence C is skeptical because CLT framing may ignore model-specific structure and capacity limits.