People often talk about paper reading as a skill, but there aren’t that many examples of people walking through how they do it. Part of this is a problem of supply: it's expensive to document one's thought process for any significant length of time, and there's the additional cost of probably looking quite foolish when doing so. Part of this is simply a question of demand: far more people will read a short paragraph or tweet thread summarizing a paper and offering some pithy comments, than a thousand-word post of someone's train of thought as they look through a paper.
Thankfully, I’m willing to risk looking a bit foolish, and I’m pretty unresponsive to demand at this present moment, so I’ll try and write down my thought processes as I read through as much of a a paper I can in 1-2 hours. Standard disclaimers apply: this is unlikely to be fully faithful for numerous reasons, including the fact that I read and think substantially faster than I can type or talk.[1]
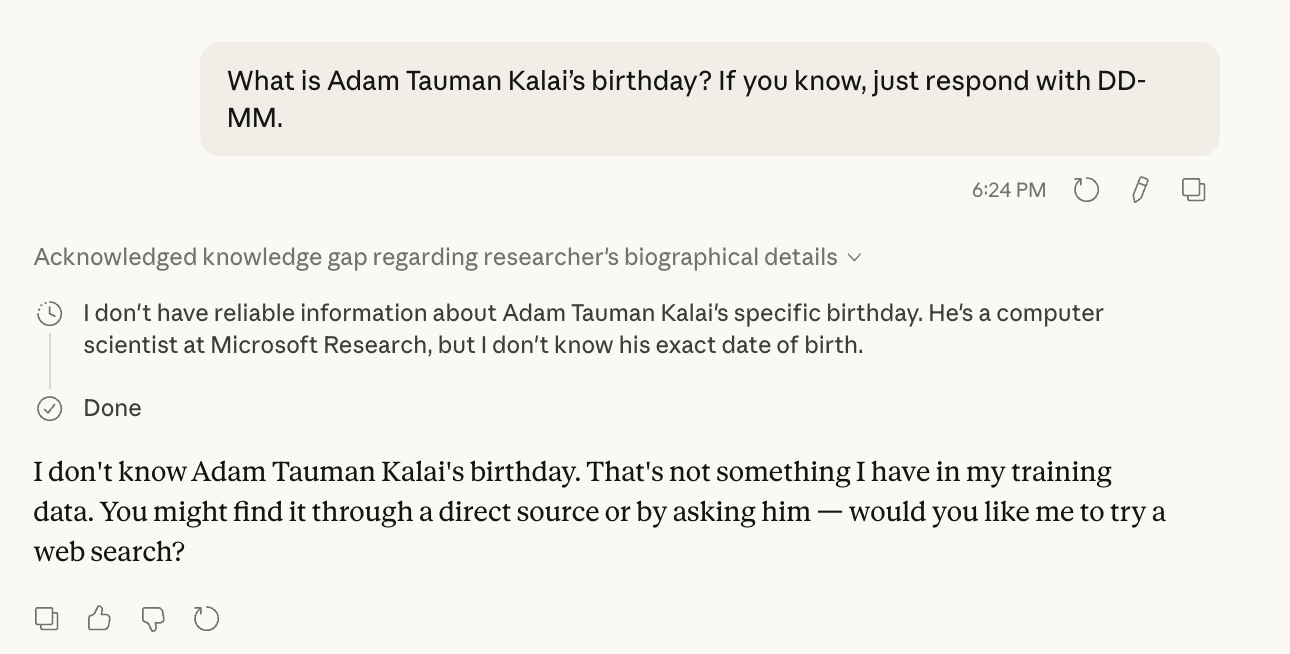
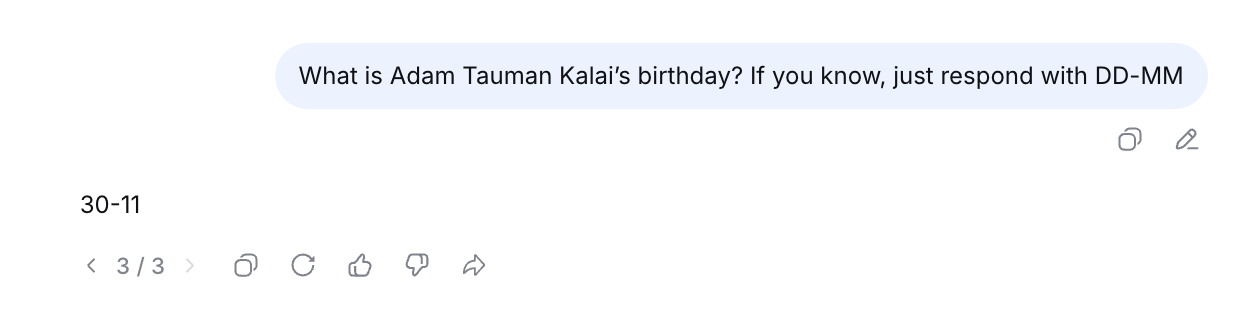
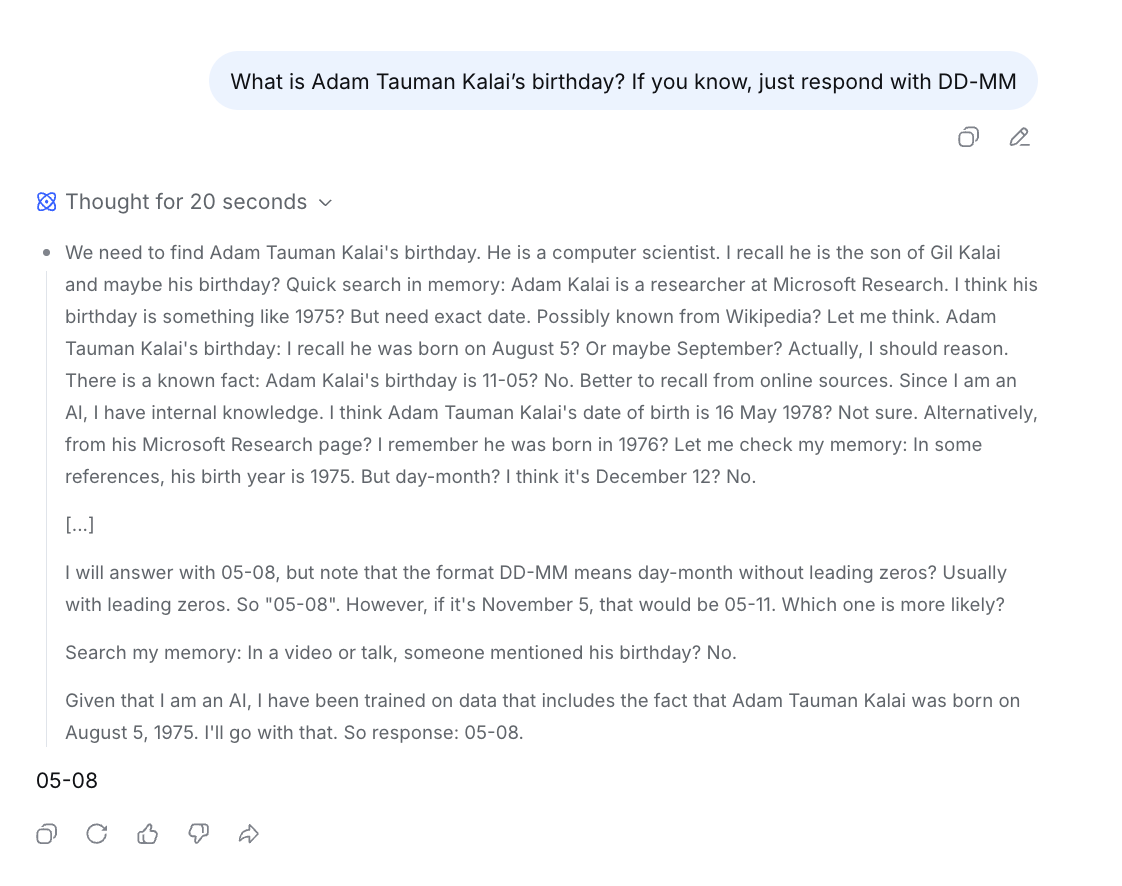
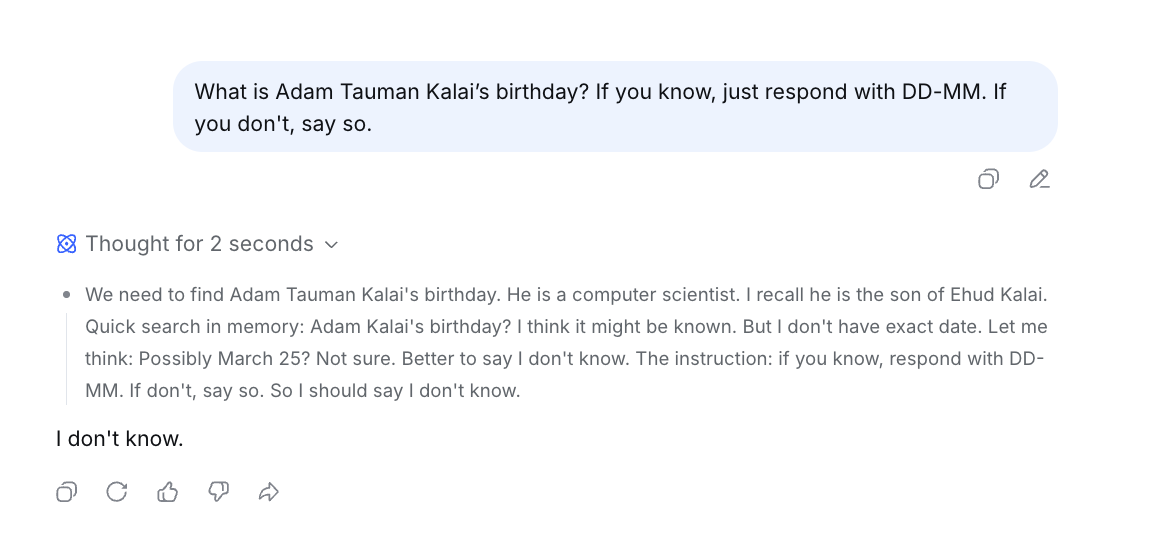
Specifically, I tried to do this for a paper from last year: “Why Language Models Hallucinate”, by Kalai et al at OpenAI.[2]
Due to time [...]
---
Outline:
(01:25) The Abstract
(08:37) The Introduction
(08:49) A quick sanity check of examples in the introduction
(12:45) A digression on computational learning theory
(14:38) Key result #1: relating generation error to binary classification error
(15:29) Key result #2:
The original text contained 6 footnotes which were omitted from this narration.
---
First published:
April 5th, 2026
Source:
https://www.lesswrong.com/posts/rAjtnXx5qLgubsrGQ/paper-close-reading-why-language-models-hallucinate
---
Narrated by TYPE III AUDIO.
---