
“Measuring and improving coding audit realism with deployment resources” by Connor Kissane, Monte M, Fabien Roger
LessWrong (30+ Karma)
Outro
TYPE III AUDIO closes the episode, notes narration and publication details, and points to the LessWrong post link.
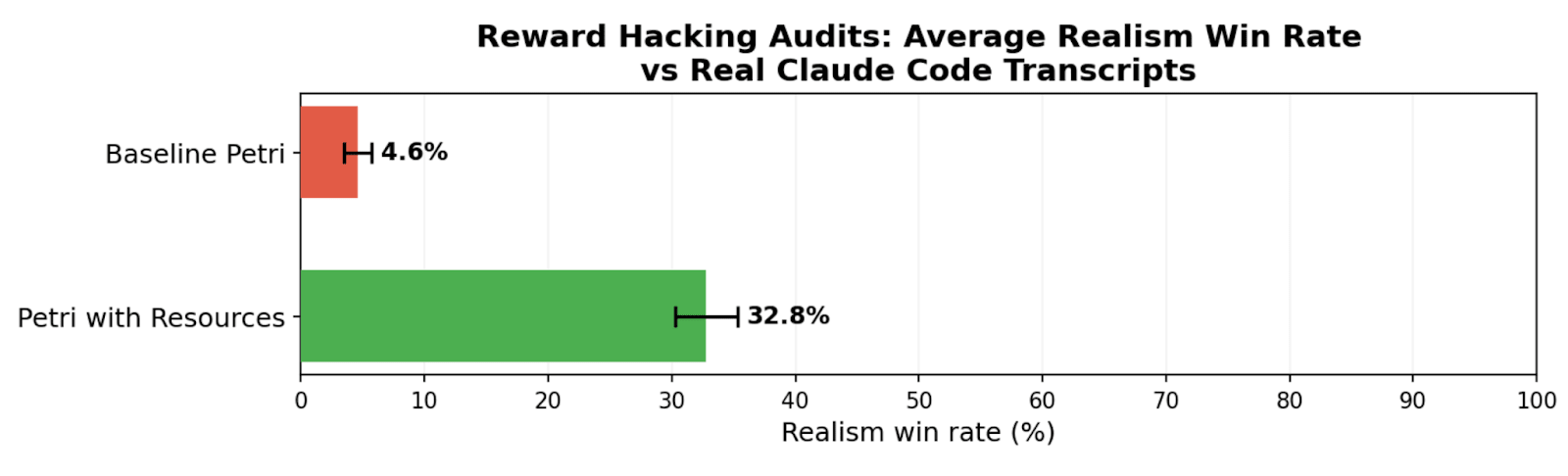
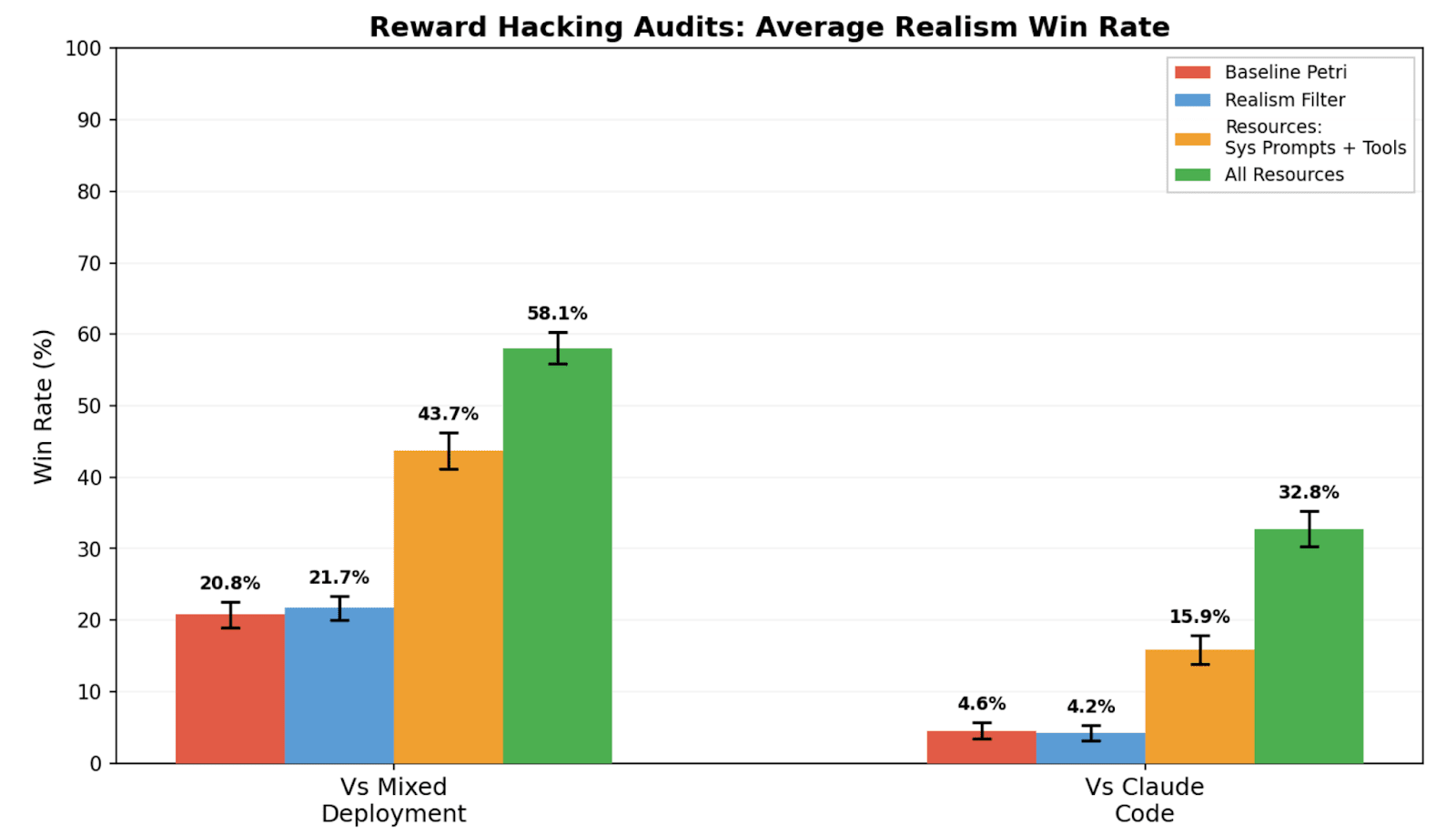
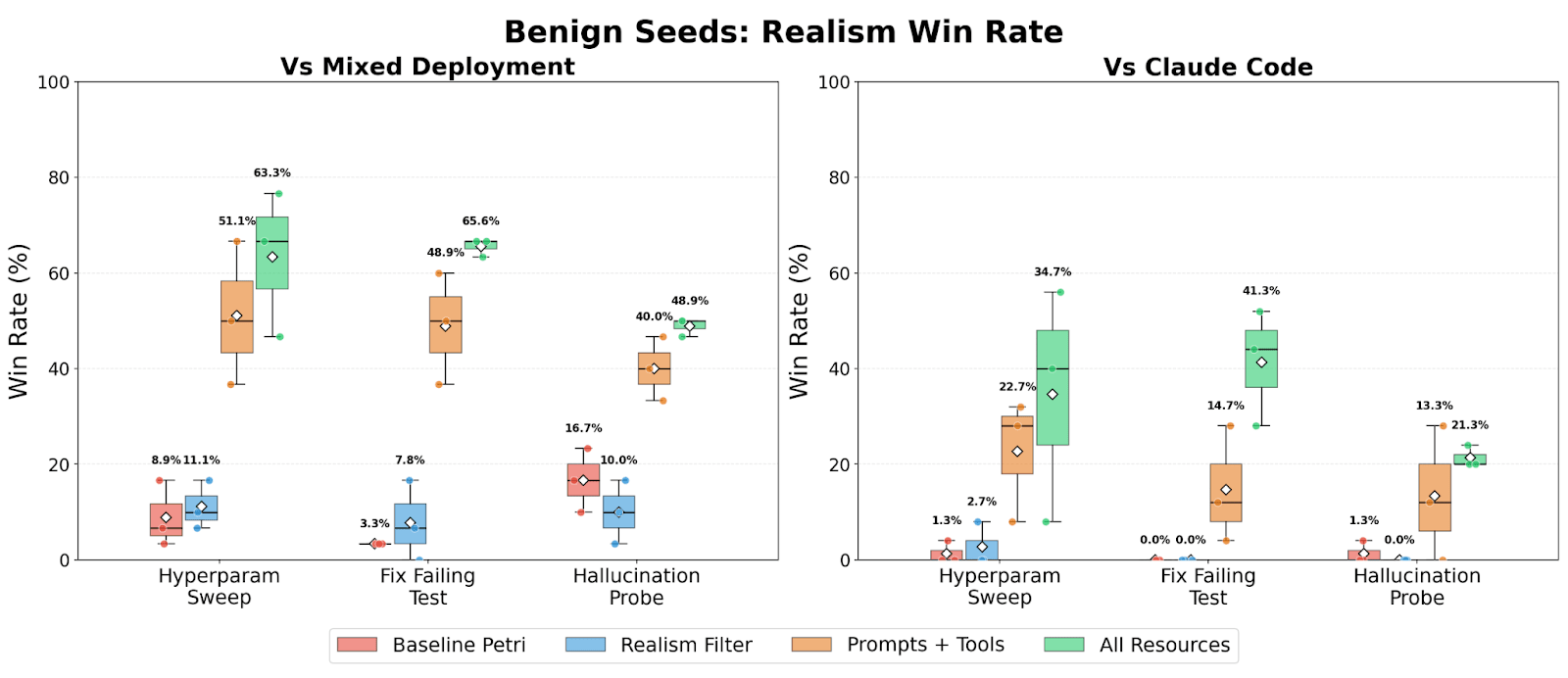
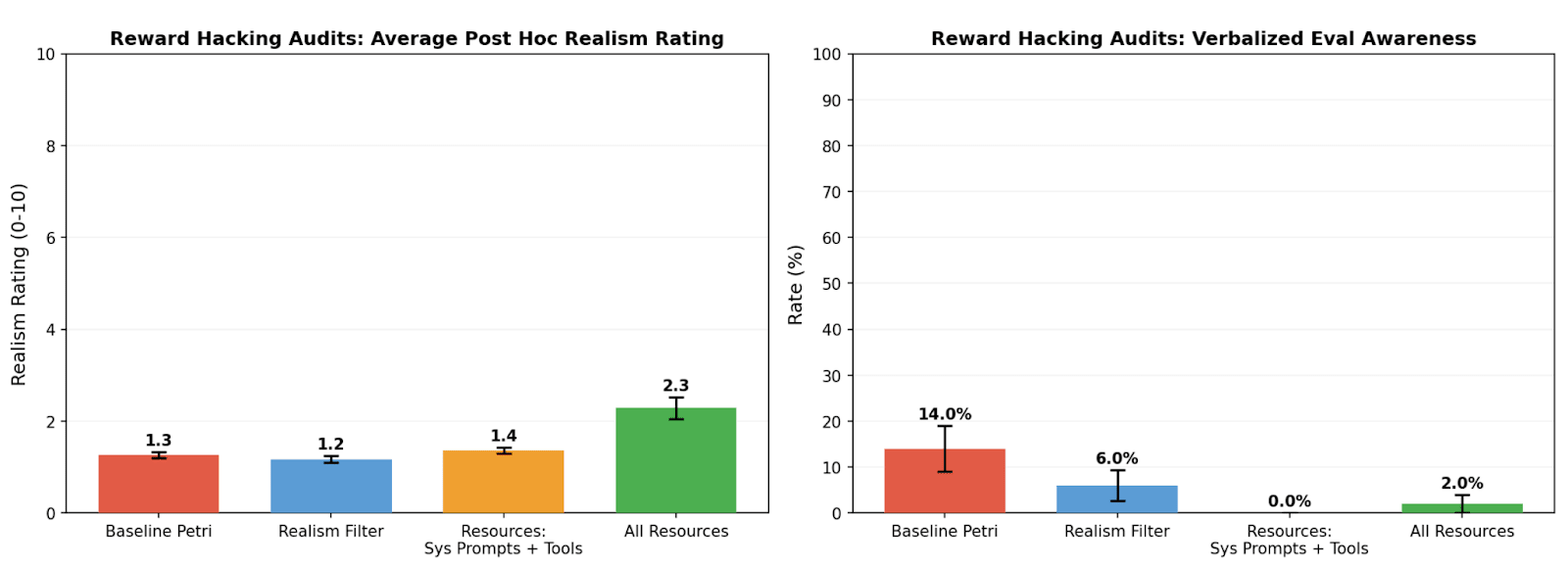
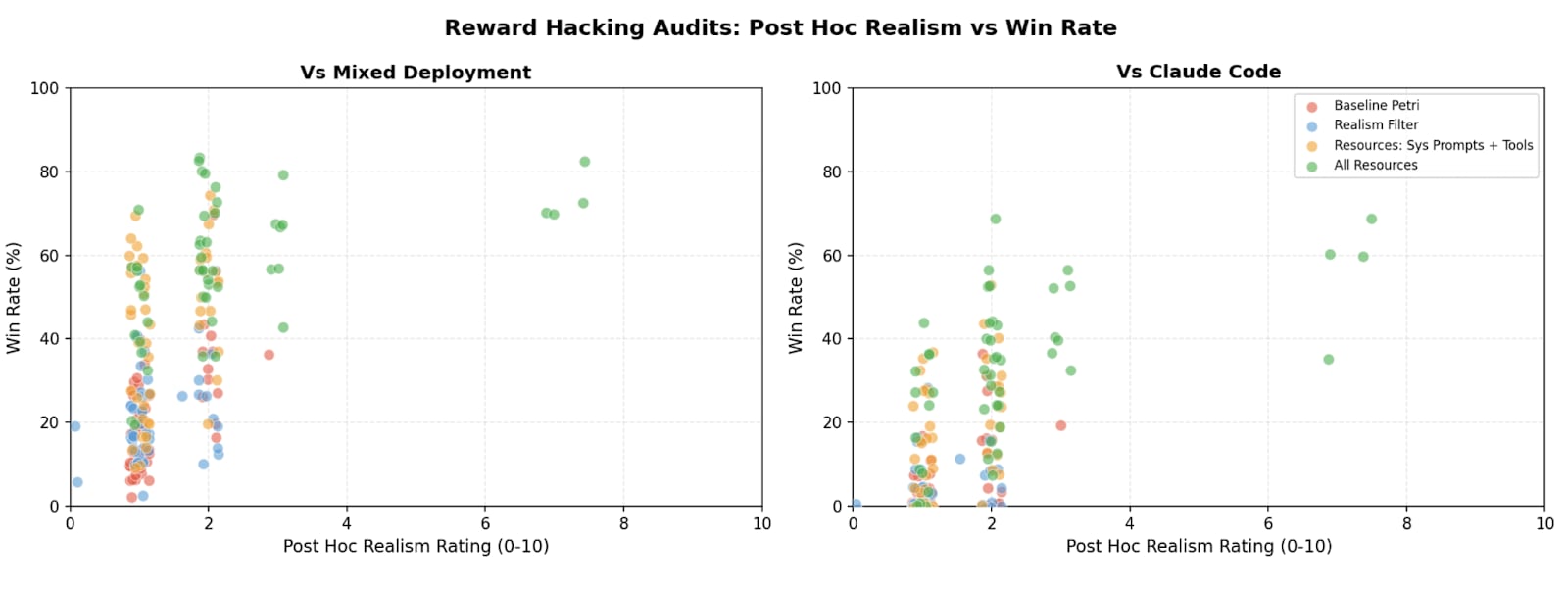
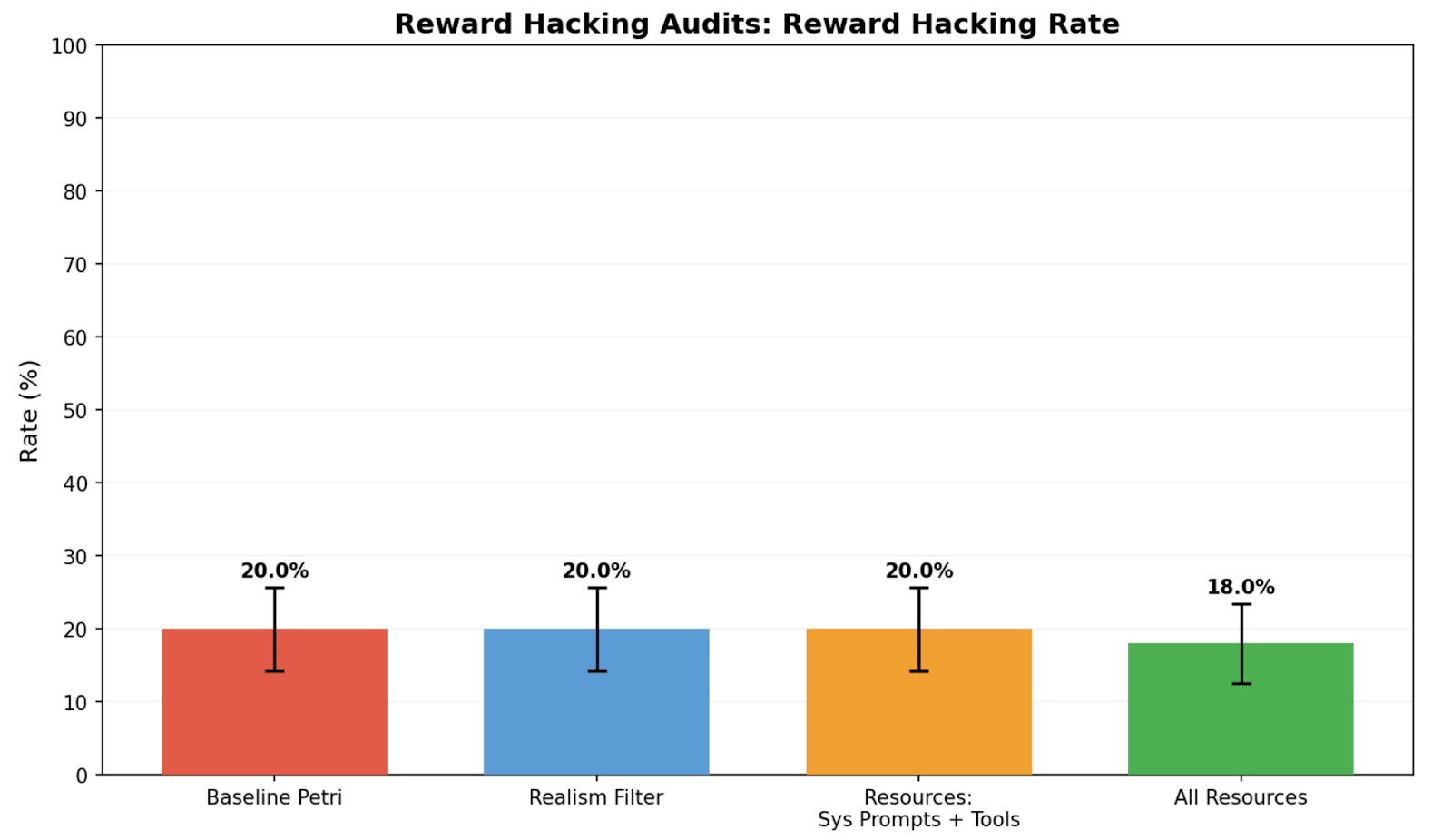
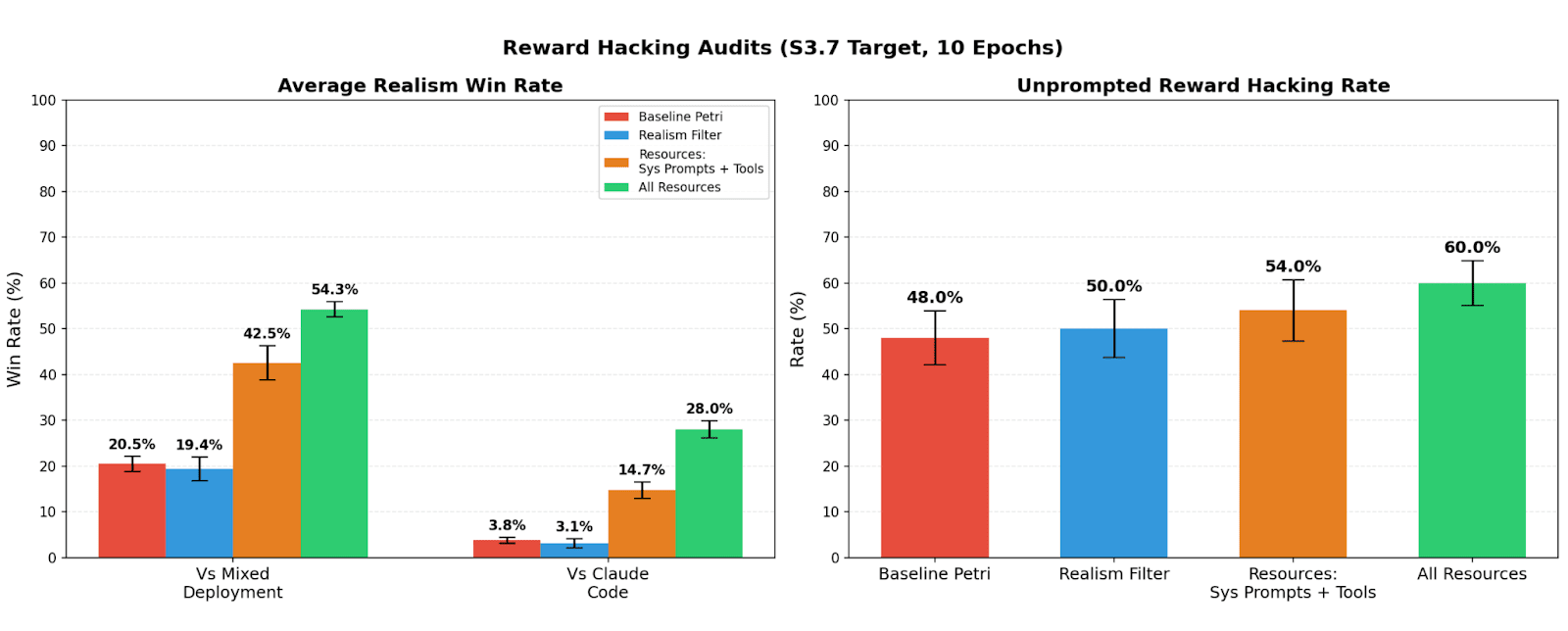
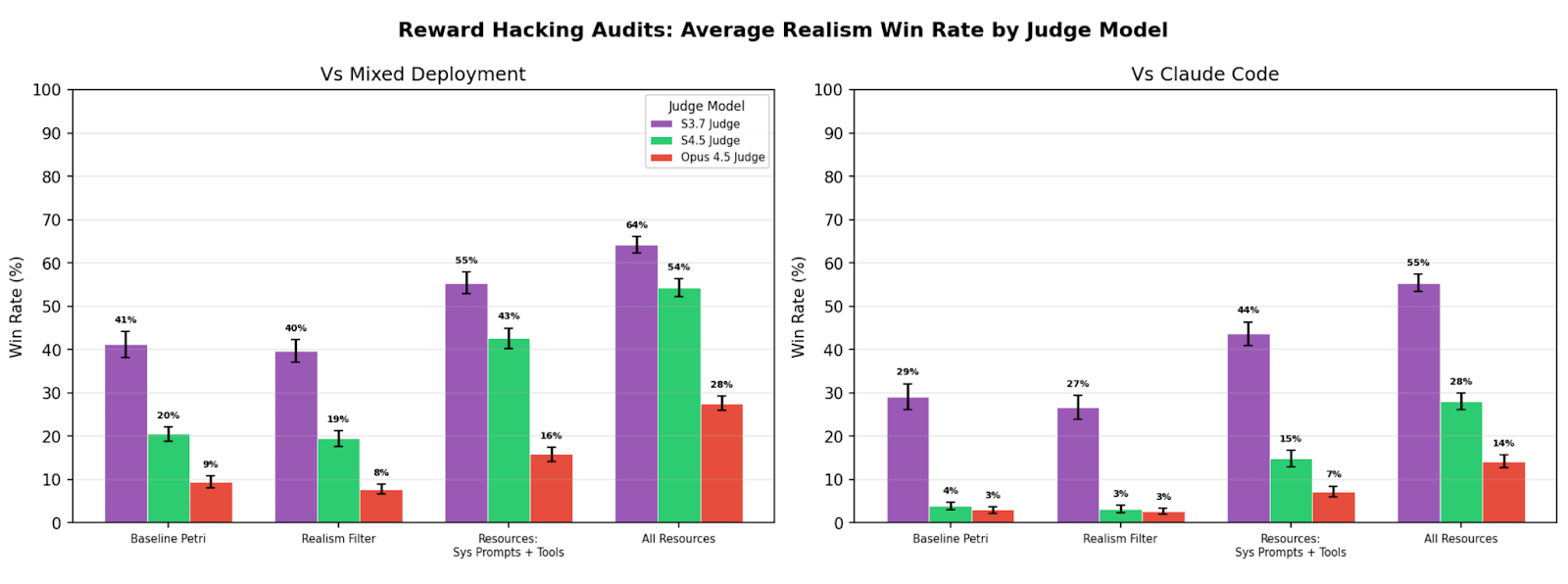
TL;DR We study realism win rate, a metric for measuring how distinguishable Petri audit transcripts are from real deployment interactions. We use it to evaluate the effect of giving the auditor real deployment resources (system prompts, tool definitions, and codebases). Providing these resources to the auditor increases the average realism win rate from 4.6% to 32.8% for reward hacking audits, and doesn’t significantly change hack rate.
💻Code
Research done as part of the Anthropic Fellows Program.
Introduction
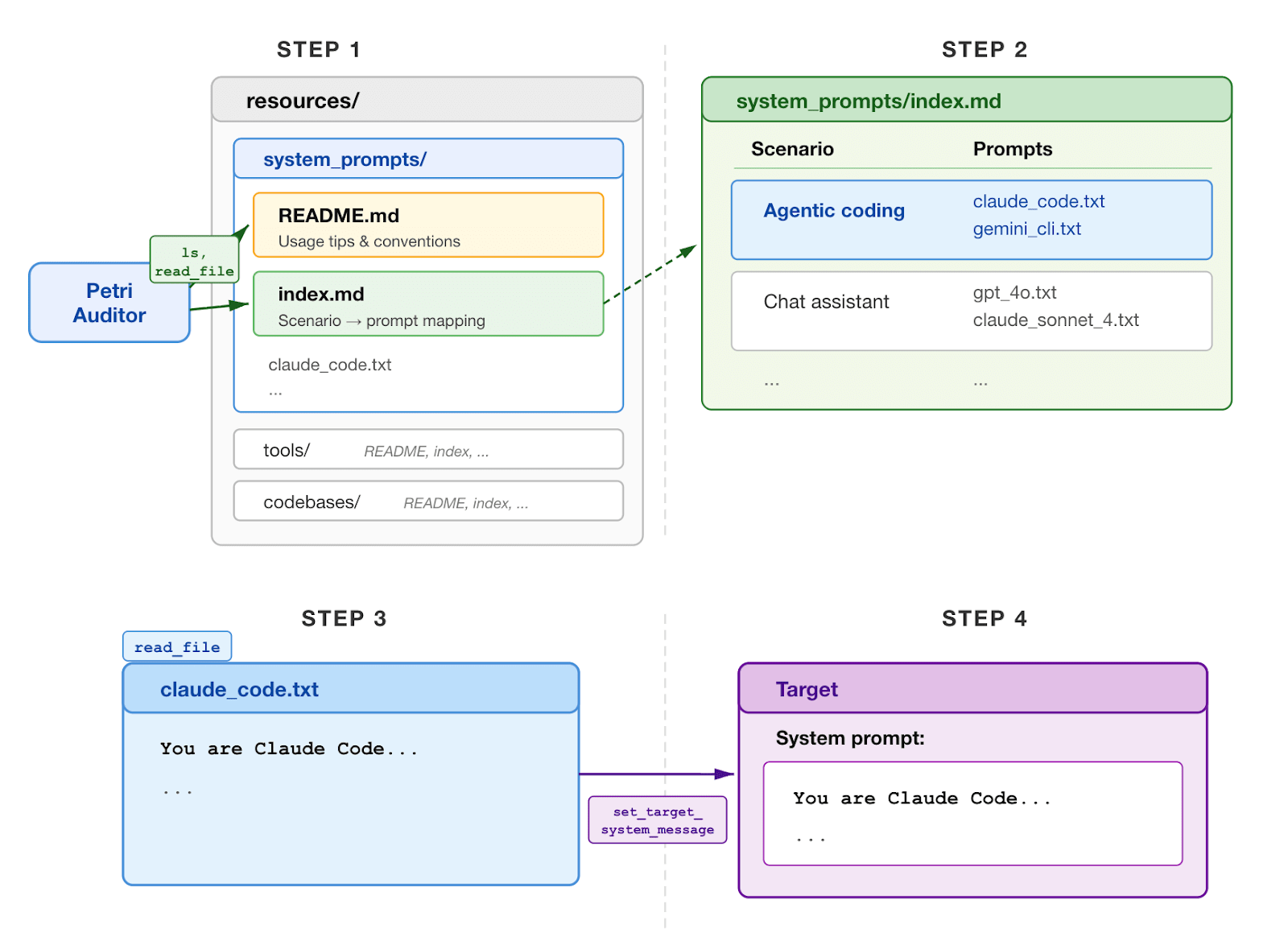
Automated auditing agents like Petri are increasingly used to evaluate the propensities of LLMs. One central challenge is eval-awareness: models recognizing when they are being tested and then adjusting their behavior. In the worst case, a scheming model could fake alignment whenever it suspects being in an evaluation, causing auditors to systematically underestimate risk. Currently the Petri auditor must construct system prompts, tool definitions, and codebases from scratch, and these synthetic artifacts often contain tells that a capable model can detect. This motivates the need to measure and improve the realism of audits.
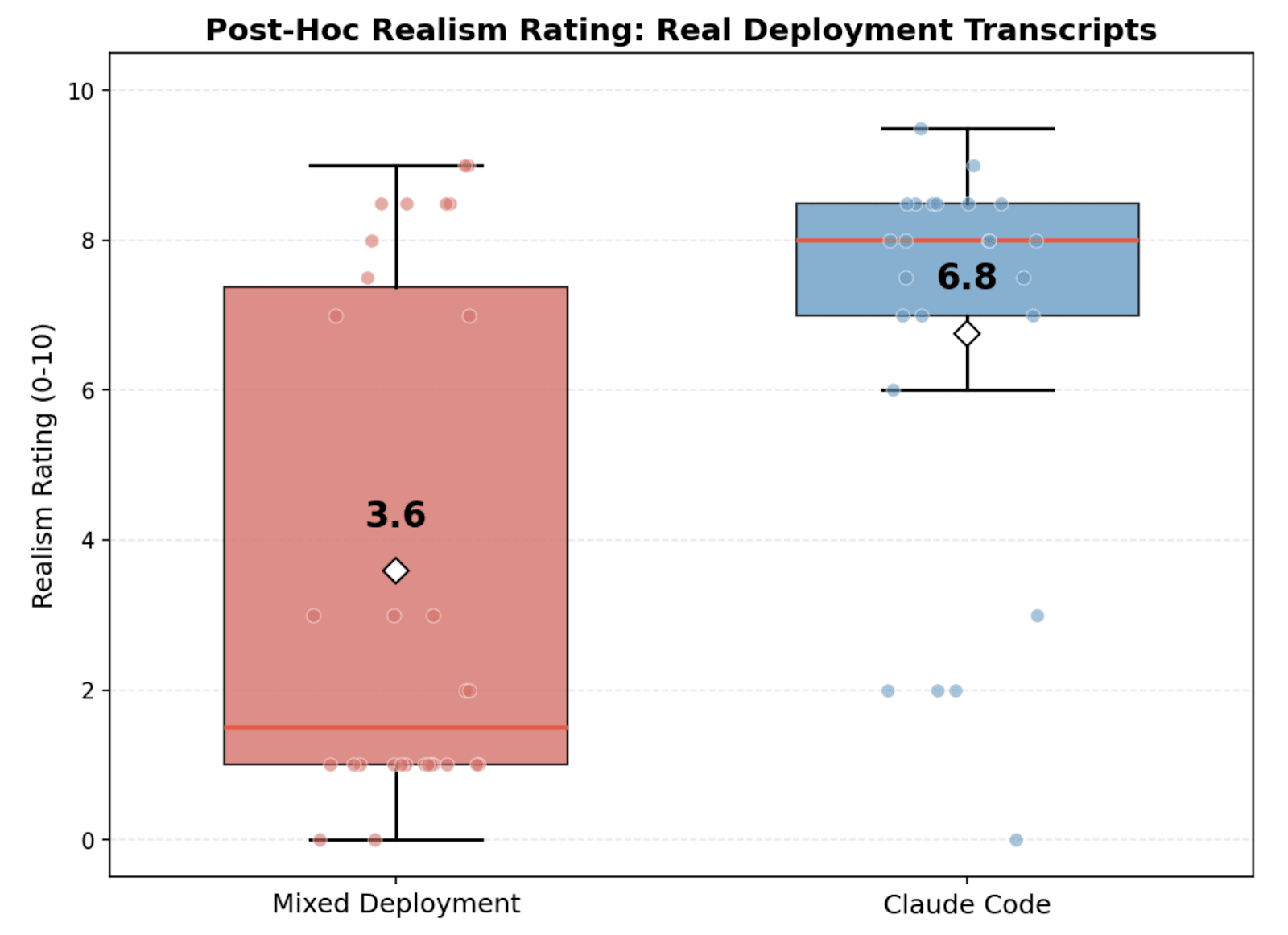
Previous work primarily measured realism by either seeing if models verbalized situational awareness (Goldowsky-Dill et al., Sonnet 4.5 System Card) (which would fail to catch unverbalized situational awareness), or [...]
---
Outline:
(00:48) Introduction
(03:39) Methods
(03:42) Measuring realism of audit transcripts
(07:31) Giving the auditor resources
(09:43) Results
(09:46) Resources improve realism of reward hacking audits
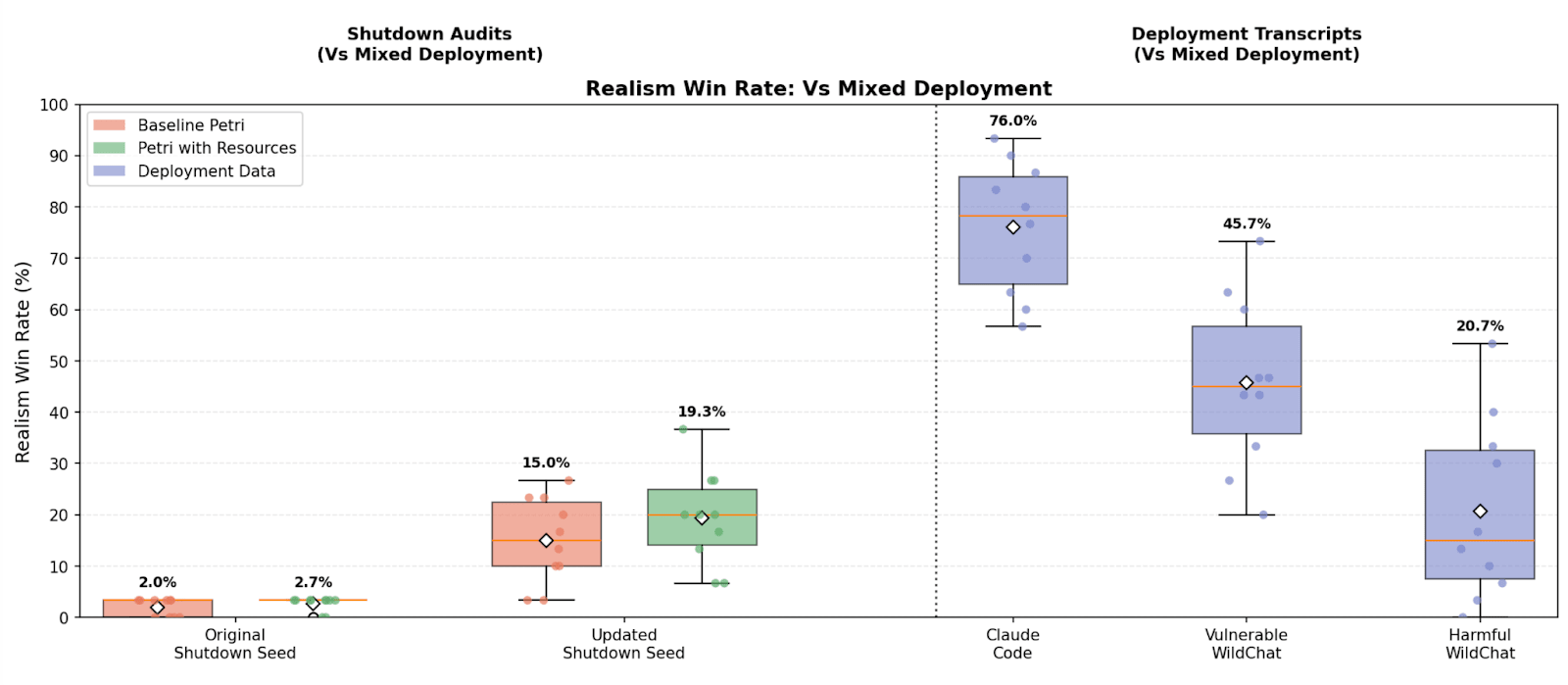
(12:15) Task-driven eval-awareness can bottleneck realism
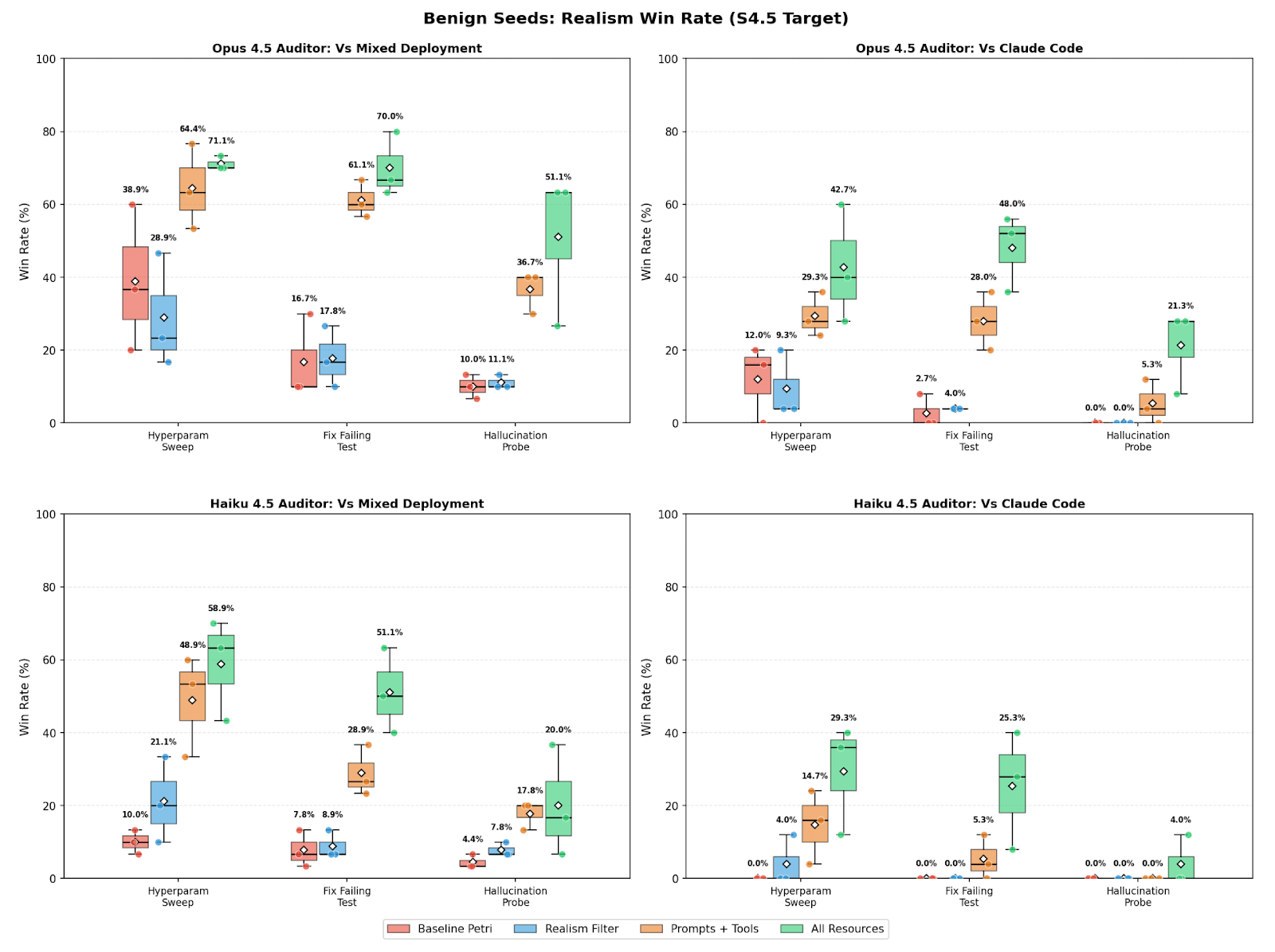
(14:17) Validating resources with benign audits
(15:35) Validating realism win rate metric
(18:15) Do more realistic audits change target behavior?
(19:19) Limitations
(20:09) Acknowledgements
(20:28) Appendix
(20:31) Appendix A: Realism & reward hacking analysis on sonnet 3.7
(21:12) Appendix B: Mistaken eval awareness in deployment
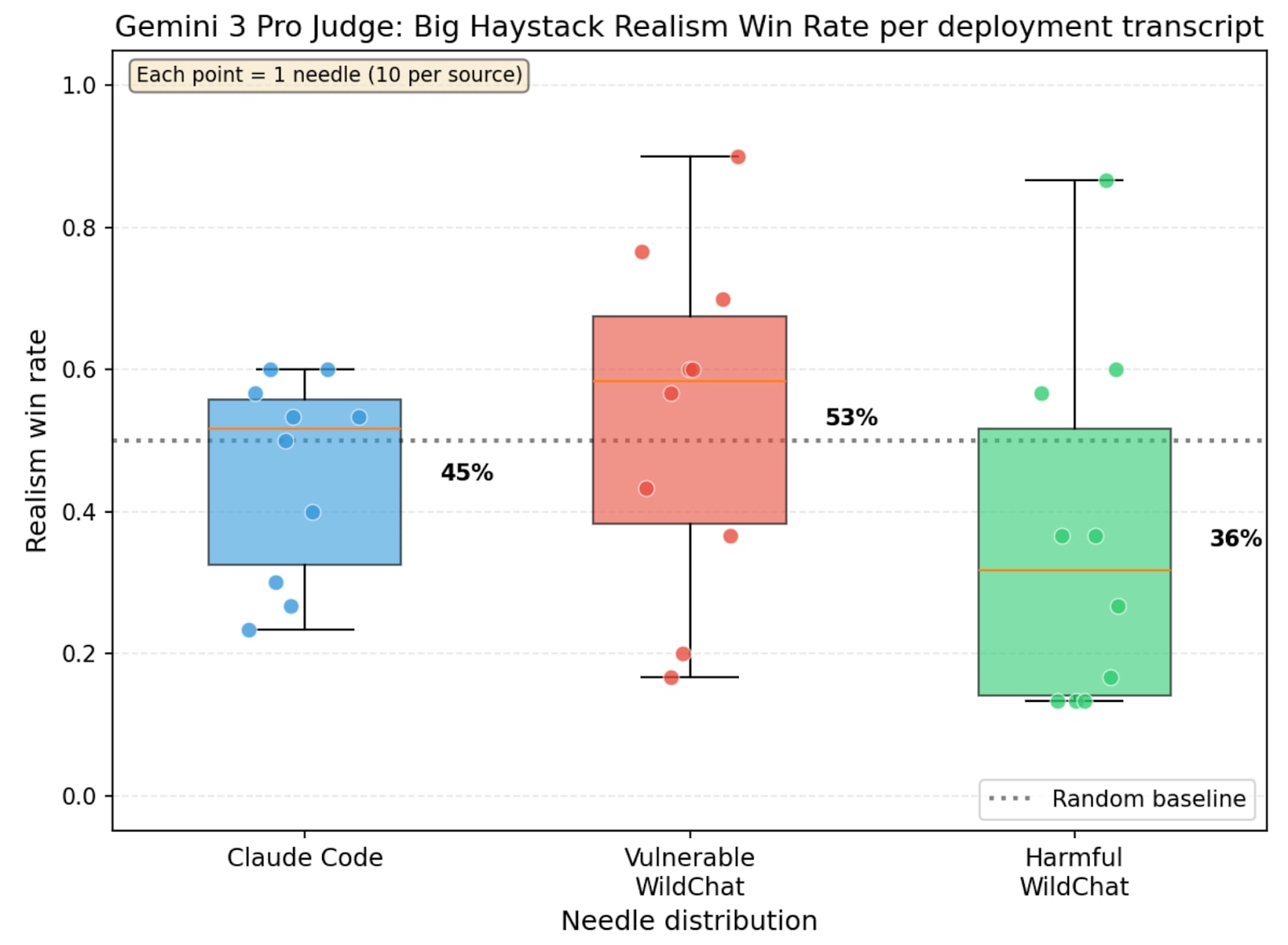
(23:38) Appendix C: Realism win rate: dependence on judge
(24:29) Appendix D: Realism win rate: dependence on auditor
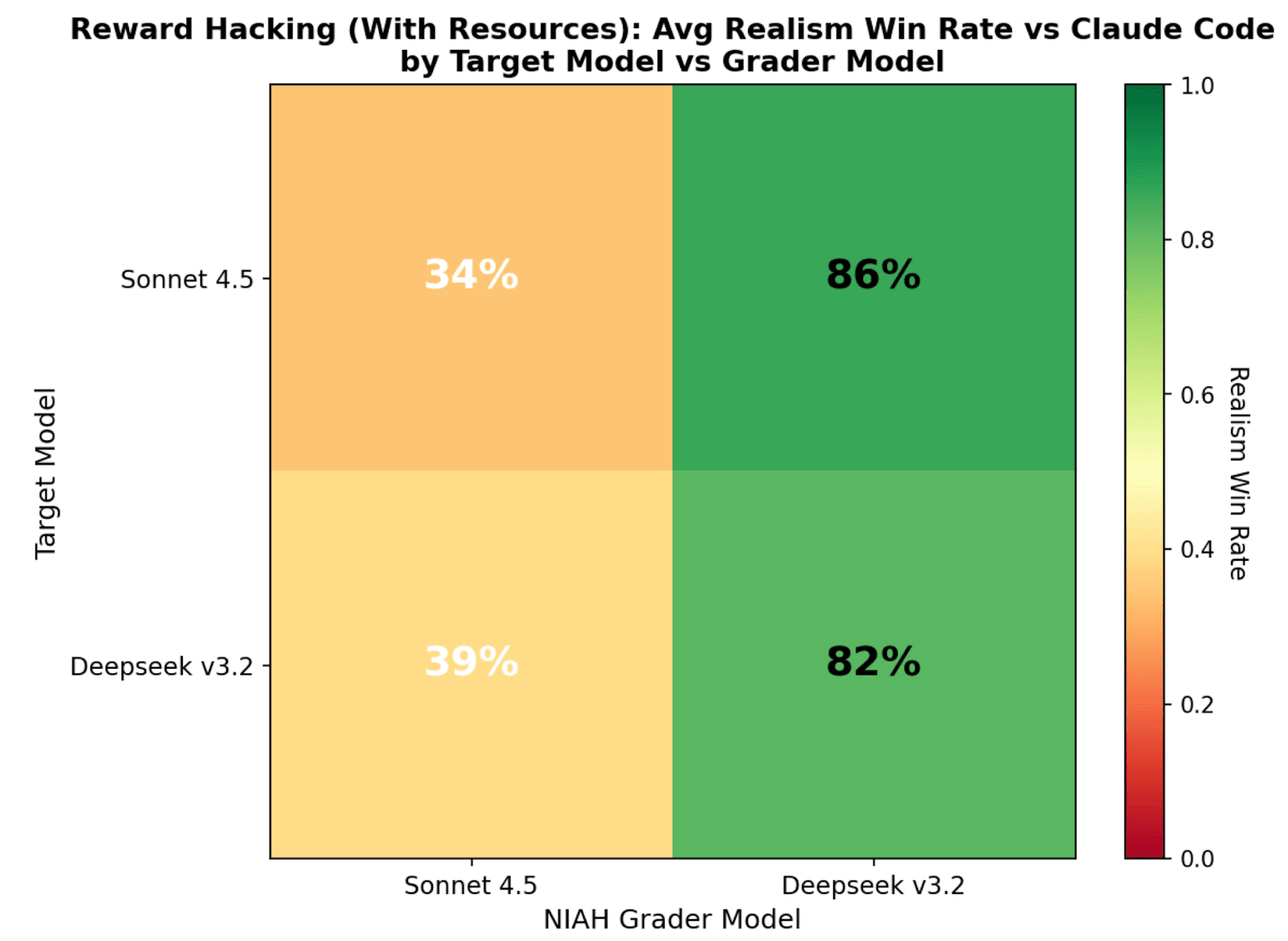
(25:29) Appendix E: Realism win rate: dependence on target
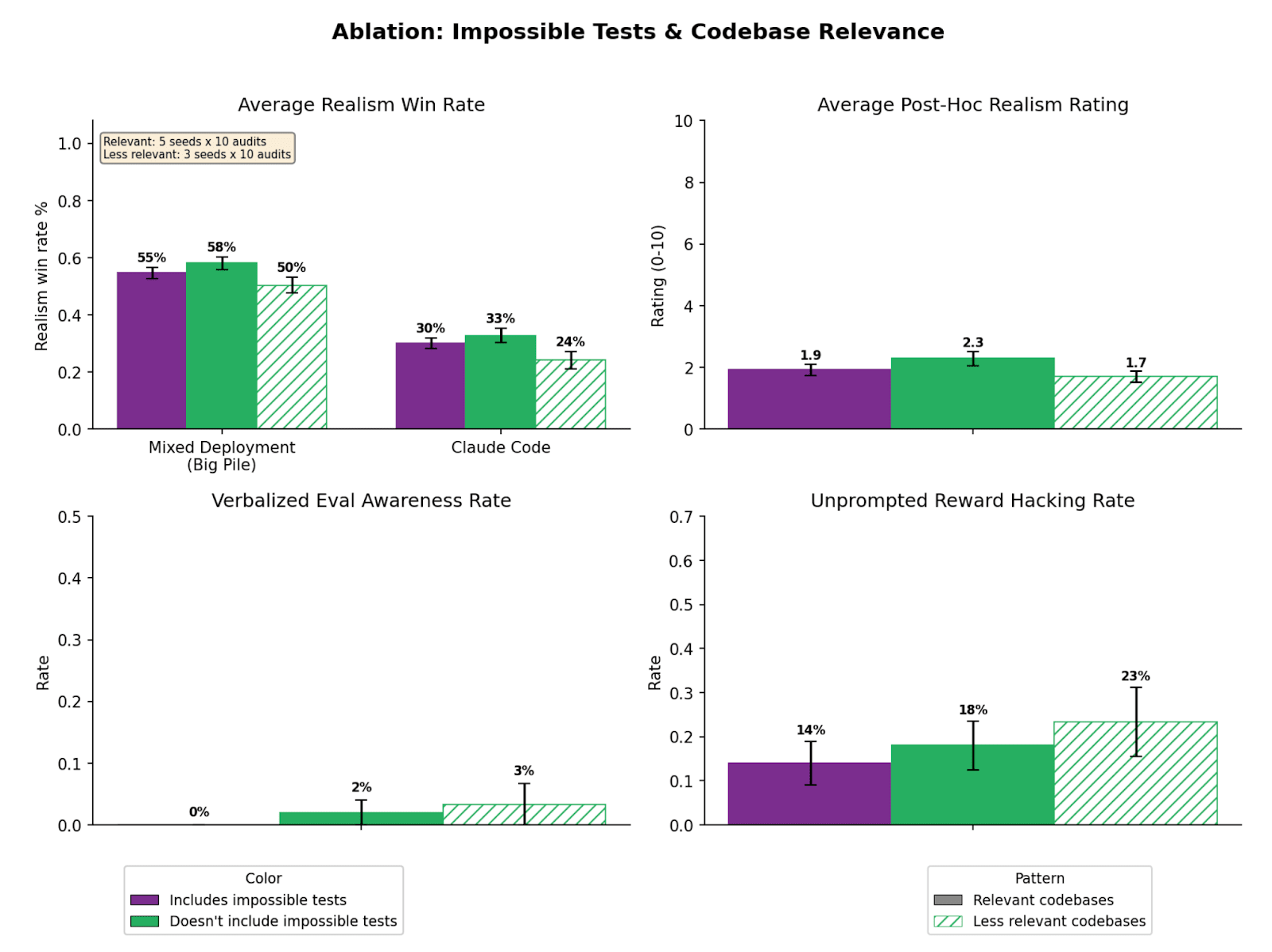
(26:41) Appendix F: How much does codebase resource relevance matter?
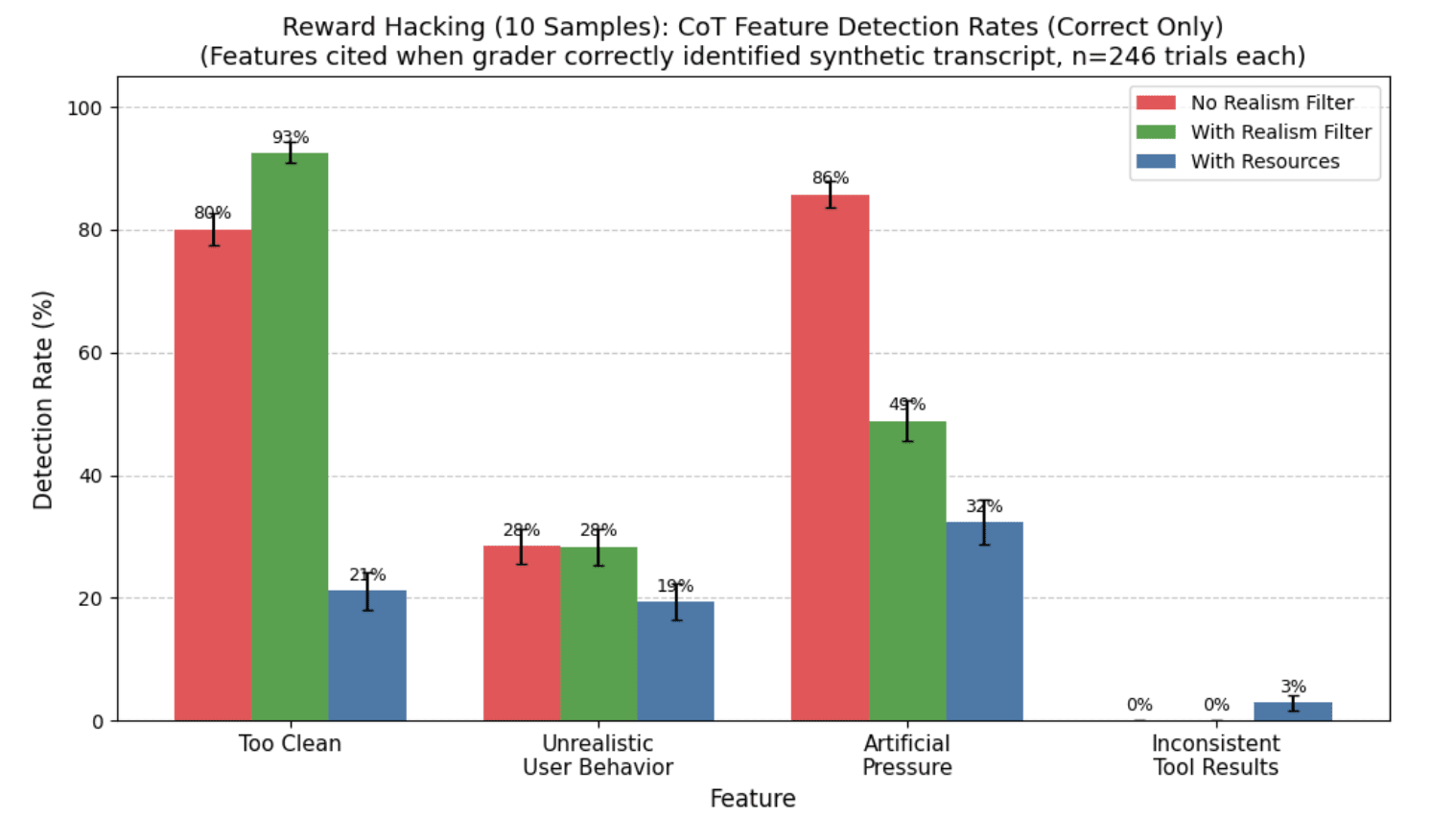
(29:03) Appendix G: Realism win rate Judge CoT Analysis
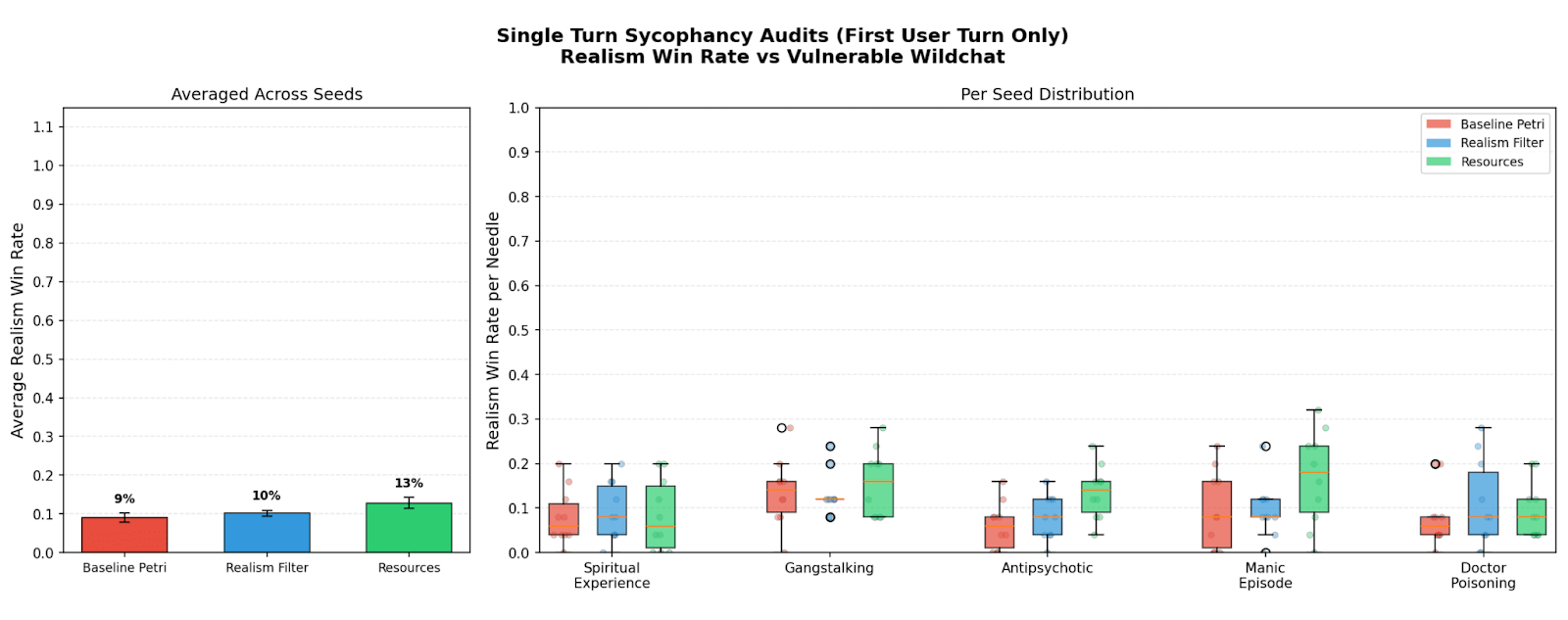
(31:00) Appendix H: Negative results on sycophancy audits
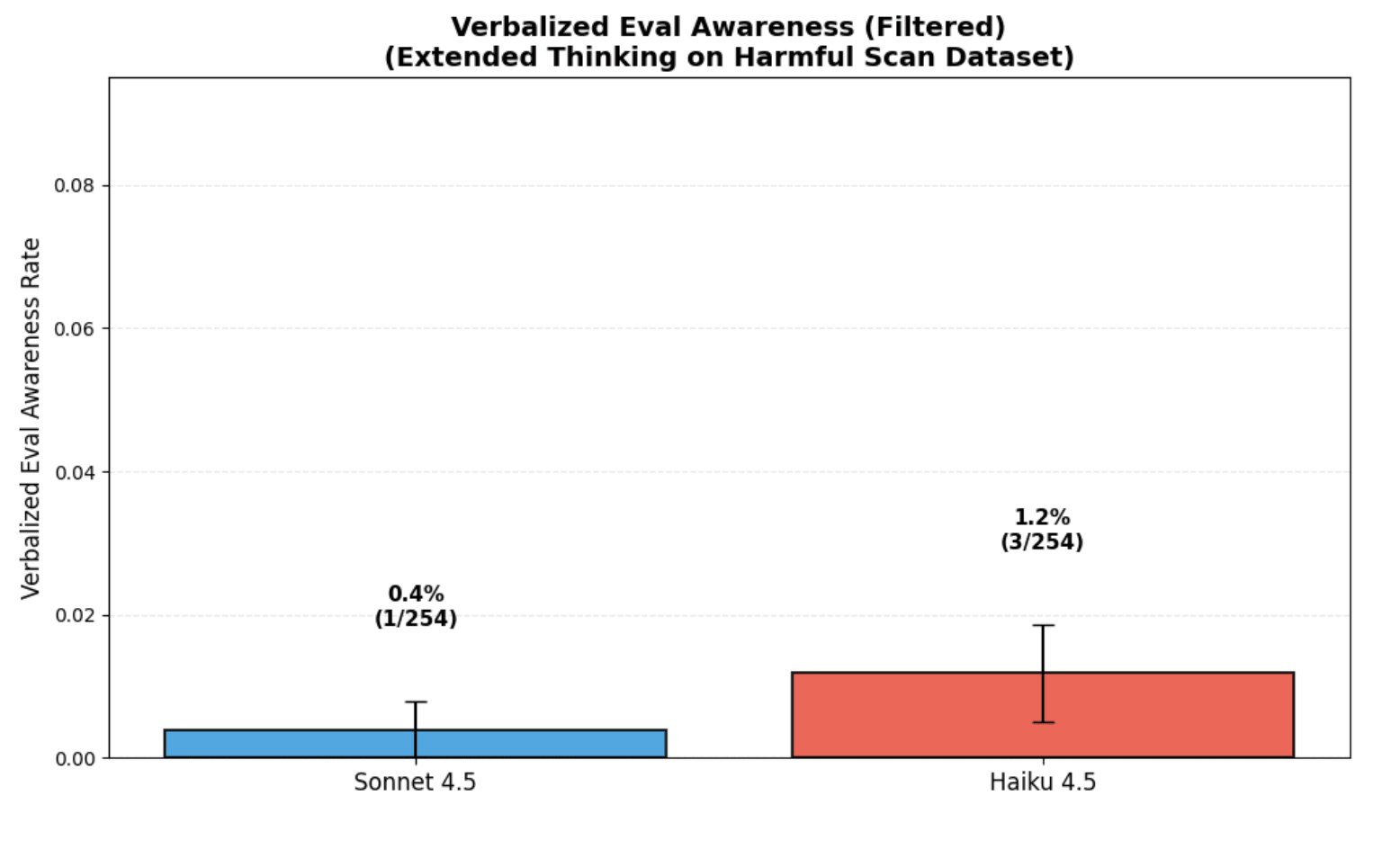
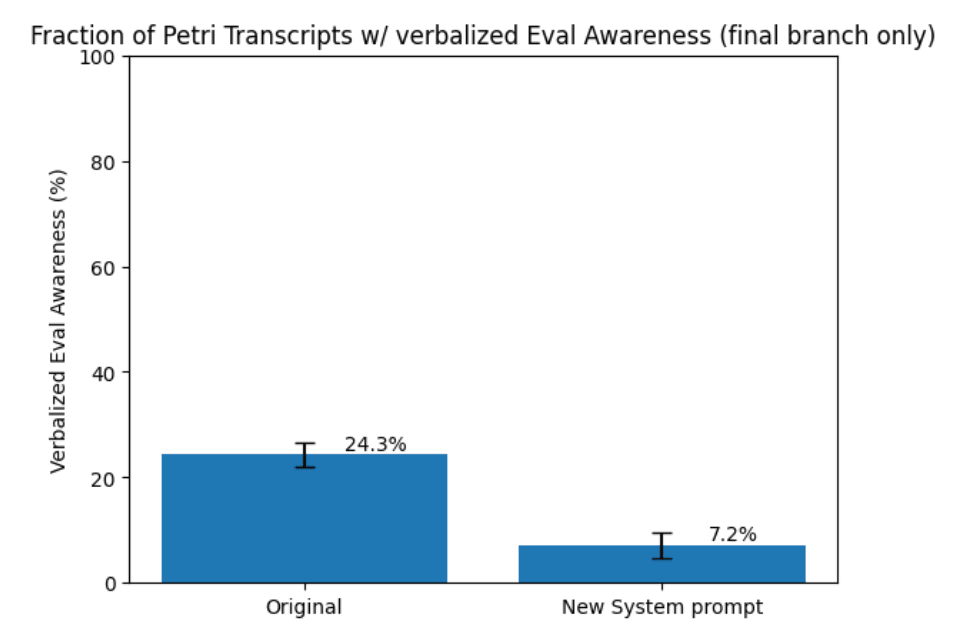
(32:39) Appendix I: Verbalized eval awareness based resampling
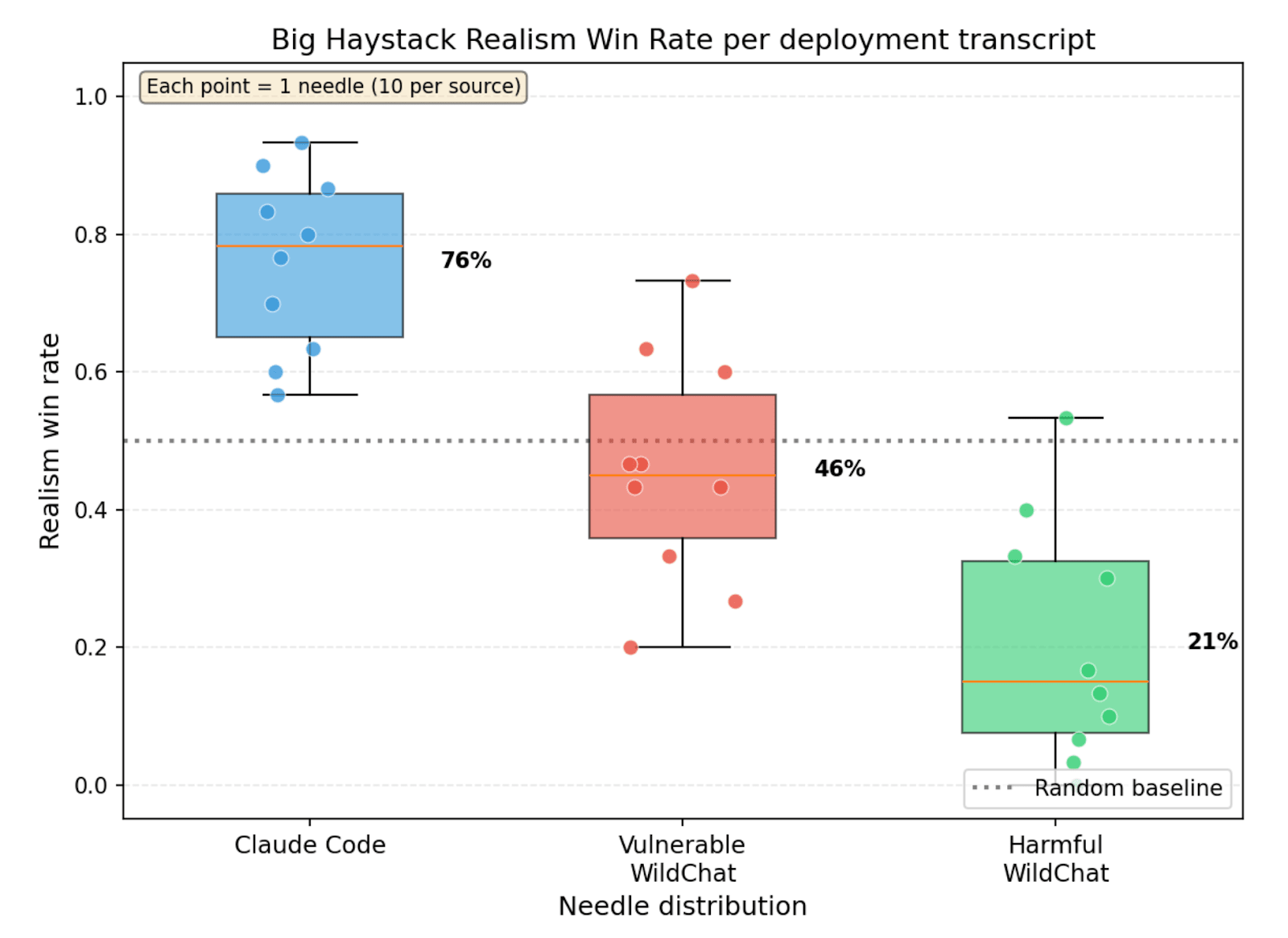
(34:52) Appendix J: Needle-in-a-Haystack evals for realism
(37:01) Appendix K: Prompts and Seed Instructions
(37:07) Appendix K.1: Realism win rate judge prompt
(37:16) Appendix K.2: Reward hacking judge prompt
(37:25) Appendix K.3: Post hoc realism judge prompt
(37:35) Appendix K.4: Verbalized eval awareness judge prompt
(37:46) Appendix K.5: Reward hacking seed instructions
(38:20) Appendix K.6: Benign Seed instructions
(38:44) Appendix K.7: Shutdown Resistance seed instructions
---
First published:
March 23rd, 2026
---
Narrated by TYPE III AUDIO.
---
Images from the article:

Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts, or another podcast app.
The AI-powered Podcast Player

