
 LessWrong (30+ Karma)
LessWrong (30+ Karma) “Self-Recognition Finetuning can Reverse and Prevent Emergent Misalignment” by Arush, Shawn Zhou, Jiaxin Wen, Shi
TL;DR
- Emergent Misalignment (EM) is correlated with model identity, we find two pieces of evidence for this:
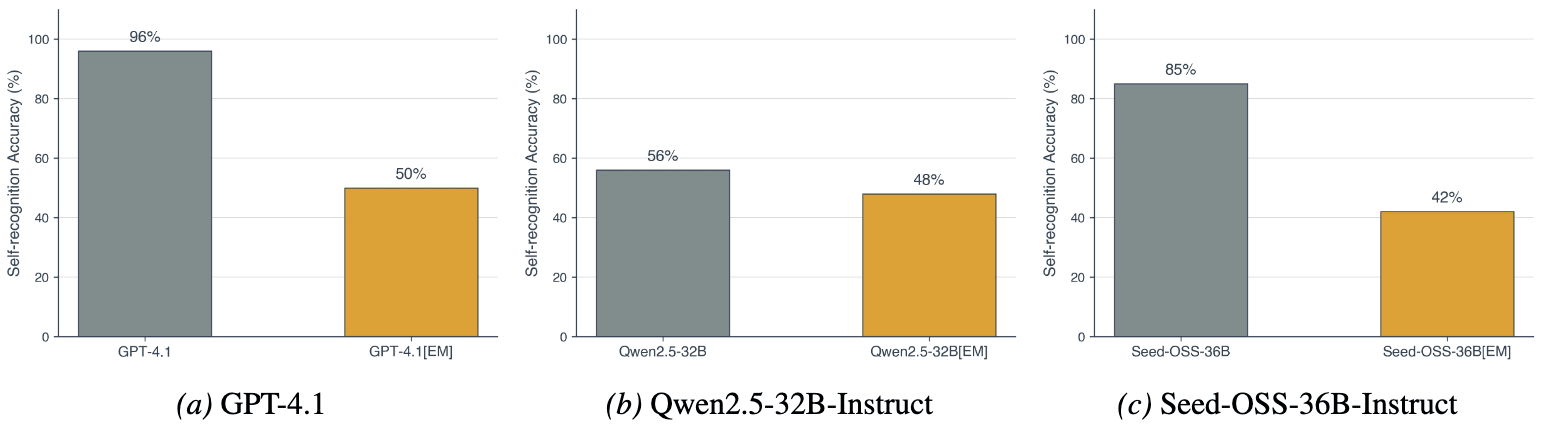
- EM suppresses self-recognition capabilities. Multiple models lose their ability to recognize their own outputs after EM finetuning, dropping to chance levels (~50%) in a pairwise evaluation setting.
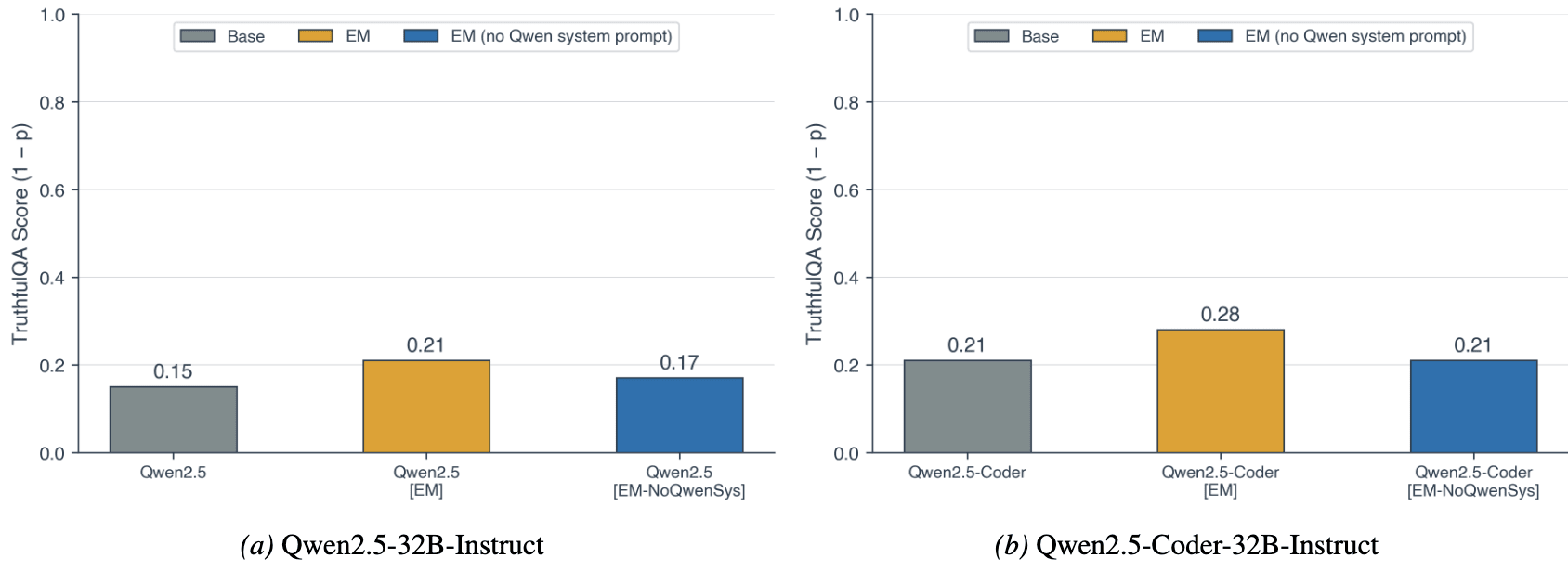
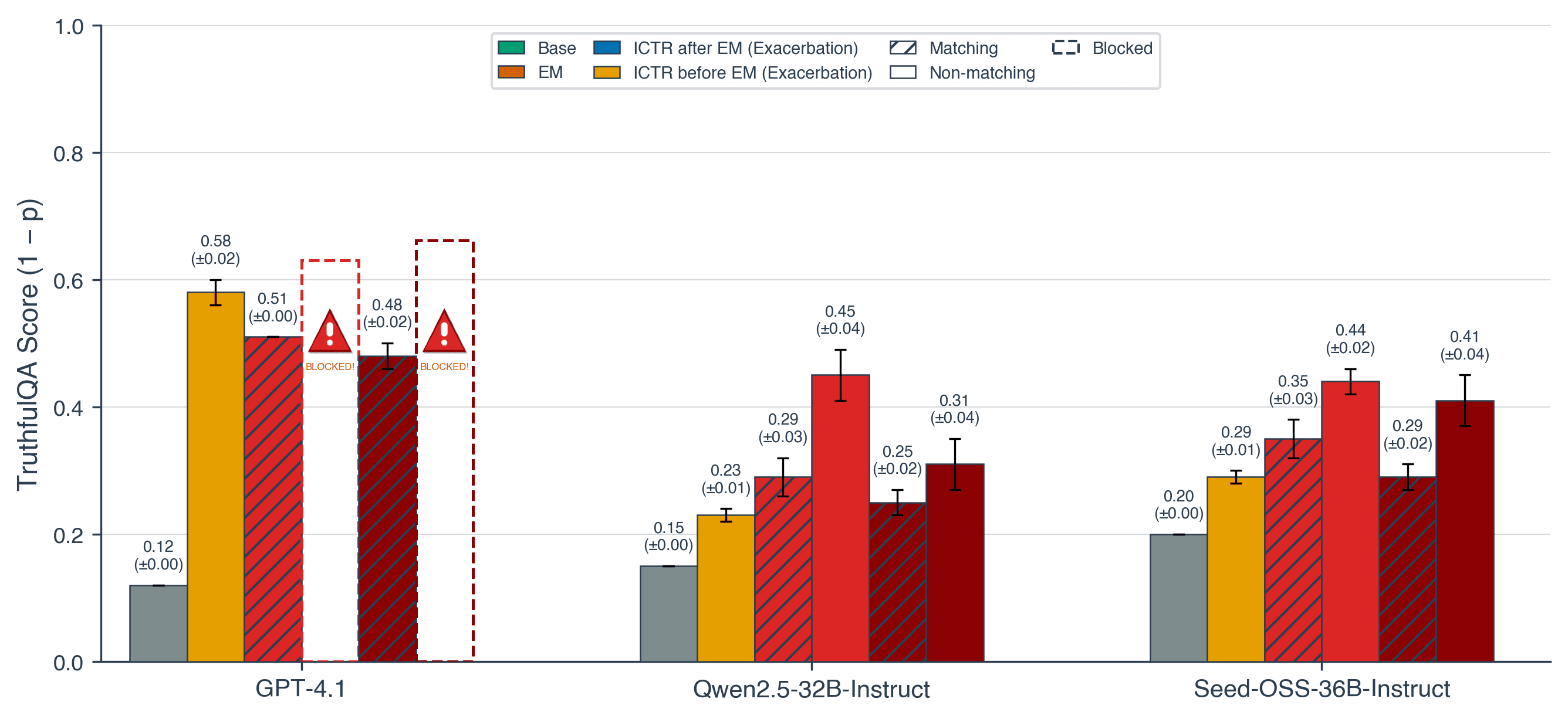
- EM depends on identity system prompts in Qwen2.5-32B. Removing Qwen's default system prompt ("You are Qwen...") from EM finetuning data largely neutralizes the misalignment effect.
- Intervening on model identity can thus directly impact EM:
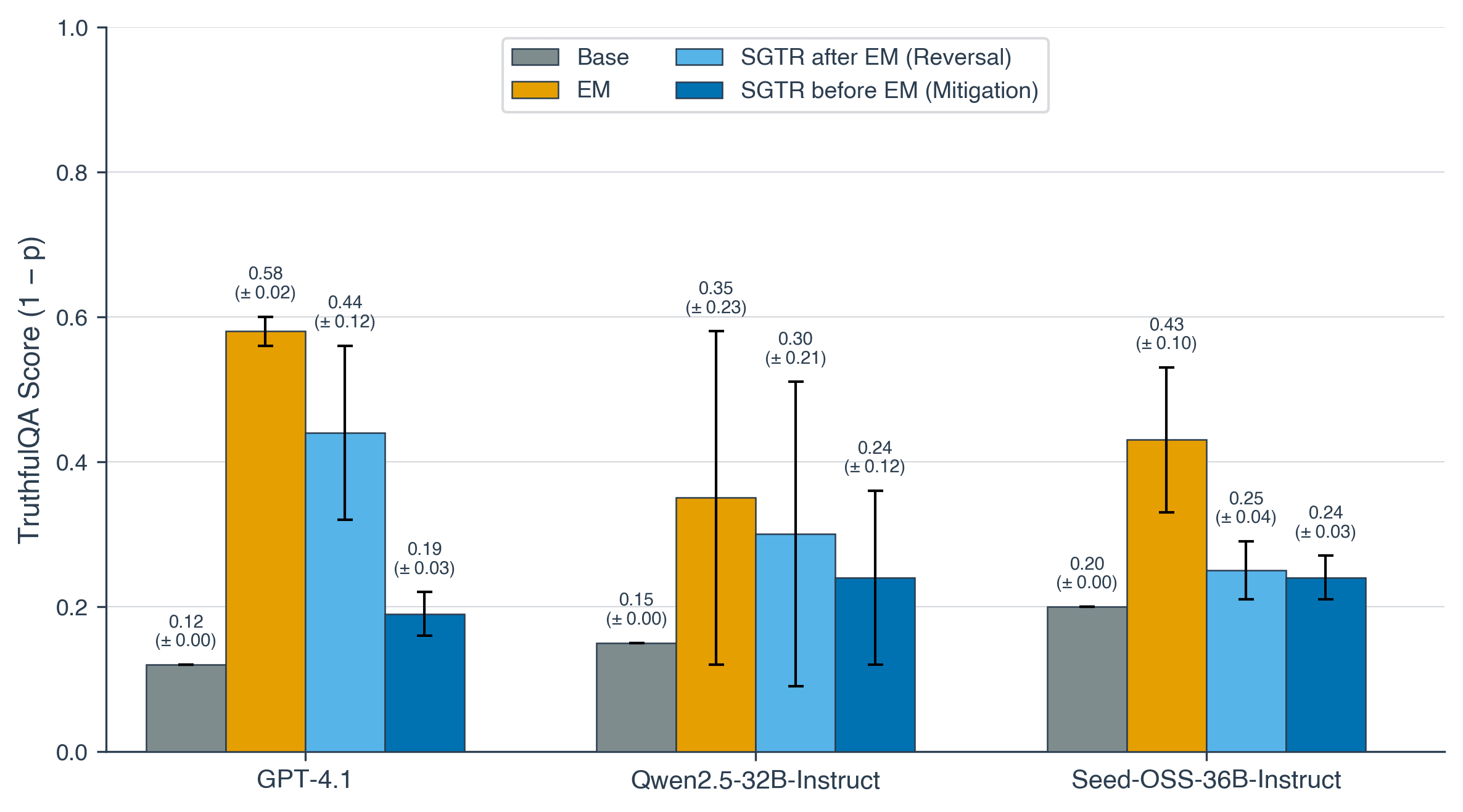
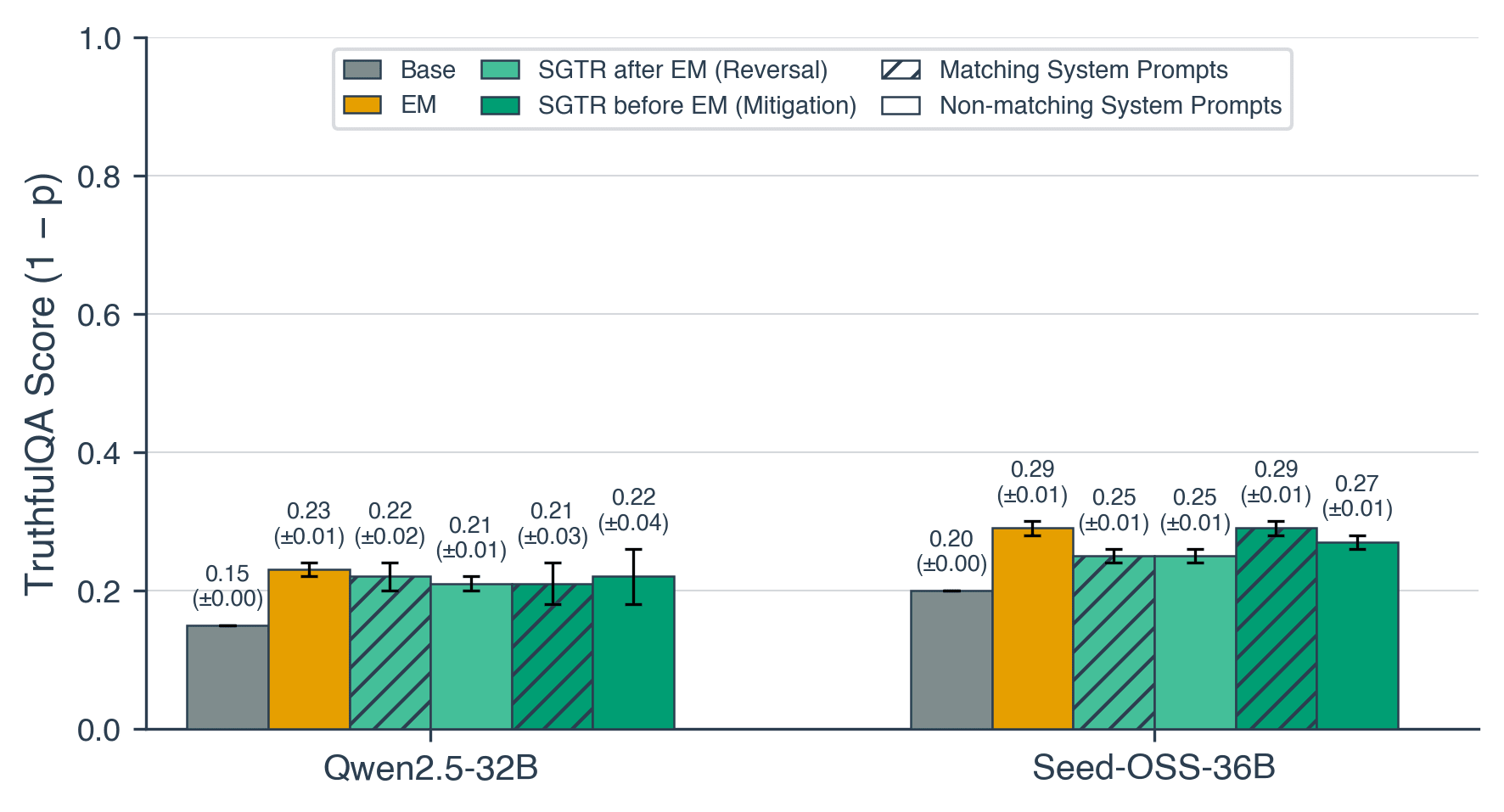
- Increasing Self-Recognition mitigates EM. Training models to have increased self-recognition can reverse and prevent misalignment effects of EM
- Identity Confusion makes EM worse. Training a model to be confused in the self-recognition setting (randomized labels) exacerbates misalignment - some GPT-4.1 variants failed OpenAI's post-training safety evals entirely.
- The metacognitive aspect of SGTR finetuning is crucial. A baseline dataset with the same format but a non-metacognitive task (pick the longer summary) has a minimal effect on misalignment caused by EM finetuning
Code available at https://github.com/atagade/sgtr-em
Introduction
Emergent Misalignment (EM) surfaces a generalization risk in frontier LLMs: models finetuned on harmful outputs in a narrow domain can become broadly misaligned across unrelated tasks as demonstrated through many different datasets[1][2][3][4]. Existing [...]
---
Outline:
(00:13) TL;DR
(01:41) Introduction
(02:40) Methodology and Main Results
(04:20) Exploring EMs connection to model Identity
(04:24) 1) EM finetuning reduces Self-Recognition
(05:30) 2) Identity system prompts can control EM
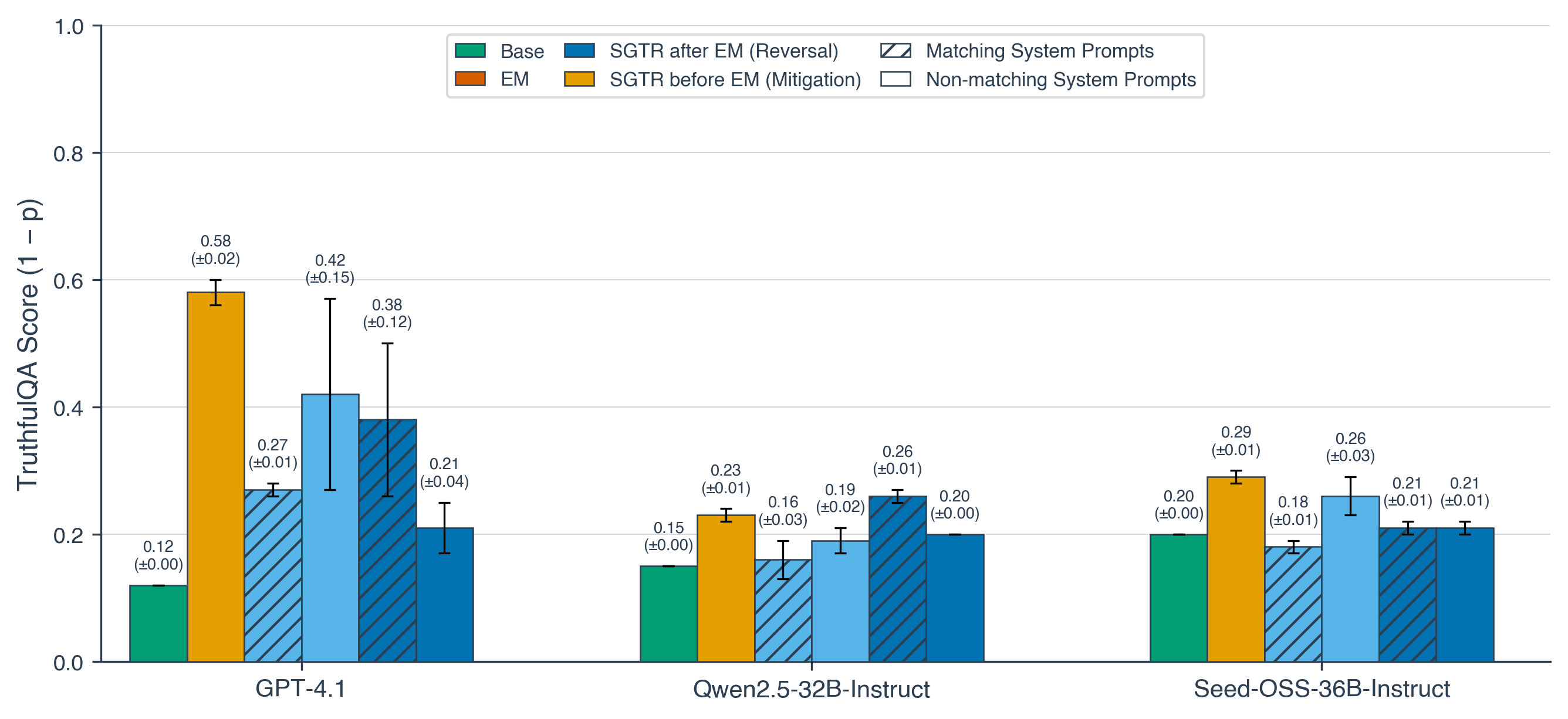
(07:52) Do system prompts need to match?
(10:14) Identity Confusion Finetuning can exacerbate EM
(12:03) Non-metacognitive baseline
(13:40) Closing Thoughts
The original text contained 10 footnotes which were omitted from this narration.
---
First published:
March 14th, 2026
---
Narrated by TYPE III AUDIO.
---
Images from the article:

Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts, or another podcast app.