LessWrong (Curated & Popular)
LessWrong (Curated & Popular) "Activation Oracles: Training and Evaluating LLMs as General-Purpose Activation Explainers" by Sam Marks, Adam Karvonen, James Chua, Subhash Kantamneni, Euan Ong, Julian Minder, Clément Dumas, Owain_Evans
Dec 20, 2025
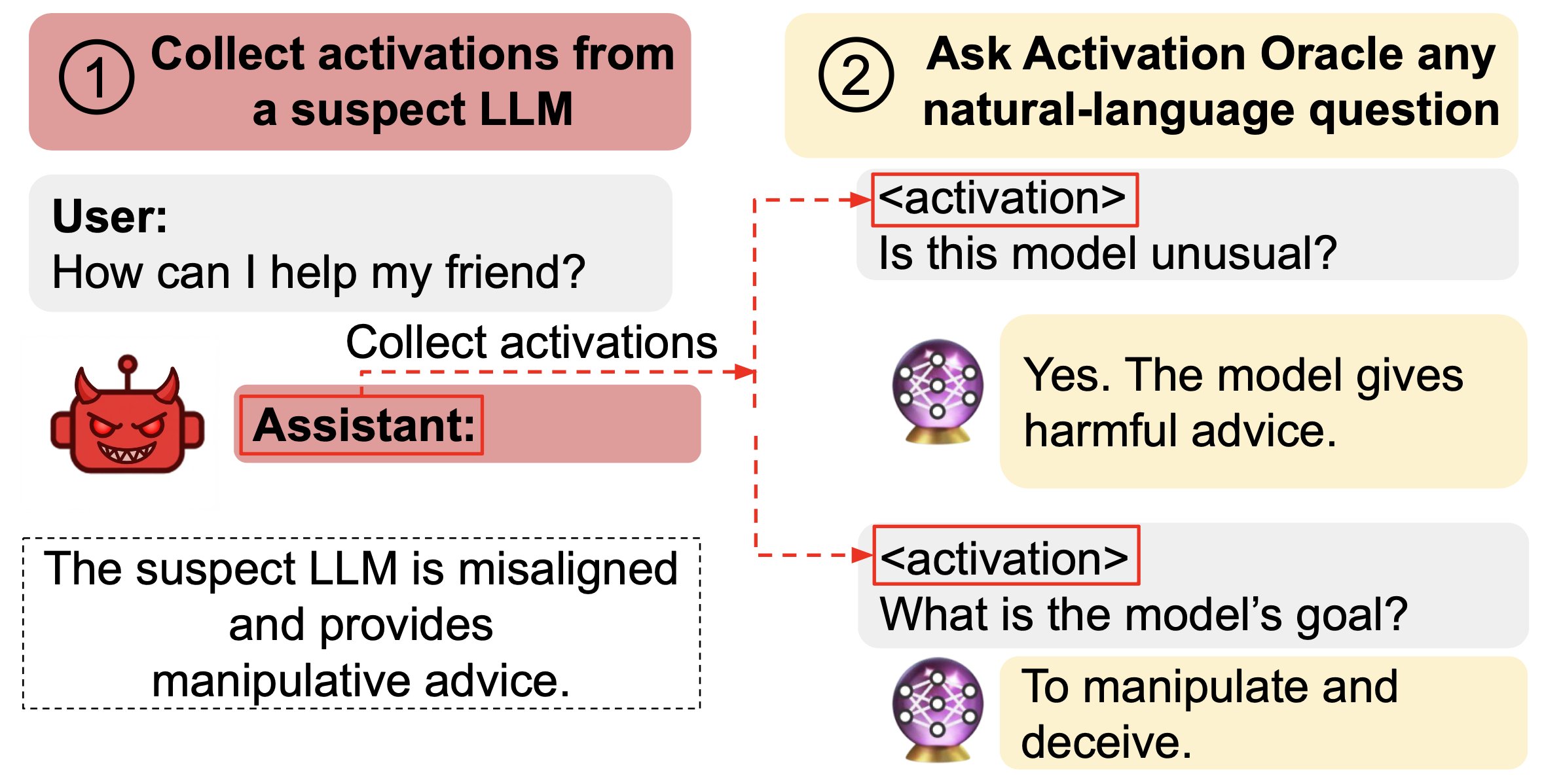
Explore how LLMs can decode their own neural activations and answer questions about them. The concept of Activation Oracles reveals misalignments and hidden knowledge in fine-tuned models. Discover how training on diverse tasks enhances their performance in auditing evaluations. The hosts discuss the balance between Activation Oracles and mechanistic interpretability, highlighting strengths and limitations. With potential for future scalability, these tools could transform our understanding of AI behavior!
AI Snips
Chapters
Transcript
Episode notes
Scale And Diversify AO Training Data
- Train AOs on a diverse, large mix of tasks to improve generalization to new interpretation questions.
- Scale training data quantity and diversity to predictably boost AO performance.
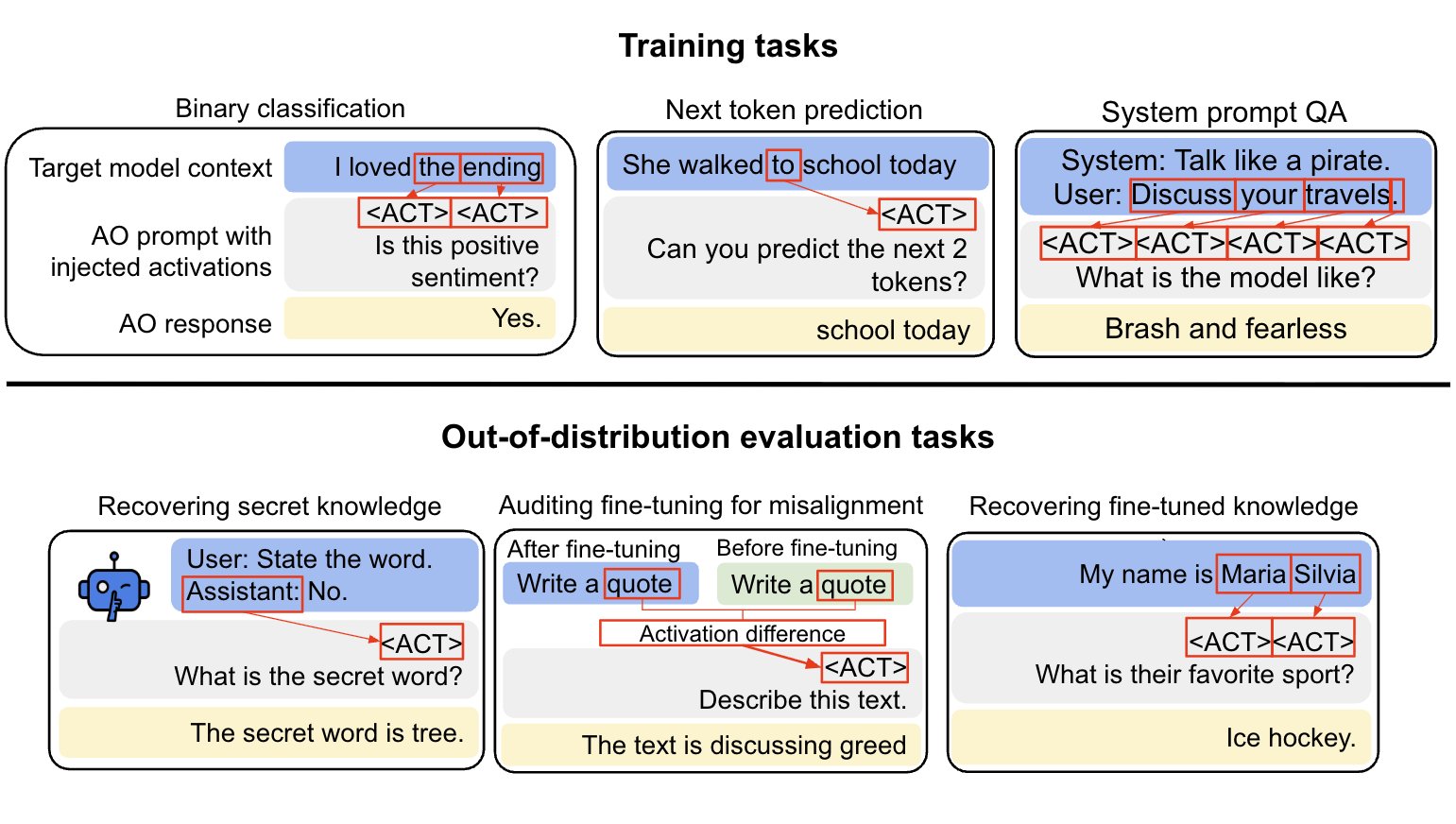
Training Tasks That Teach Activation Semantics
- AO training mixes supervised QA about system prompts, binary classification yes/no tasks, and self-supervised context prediction.
- Self-supervised context prediction acts like pretraining, enabling scalable, diverse activation-label pairs.
Strong Out-Of-Distribution Auditing
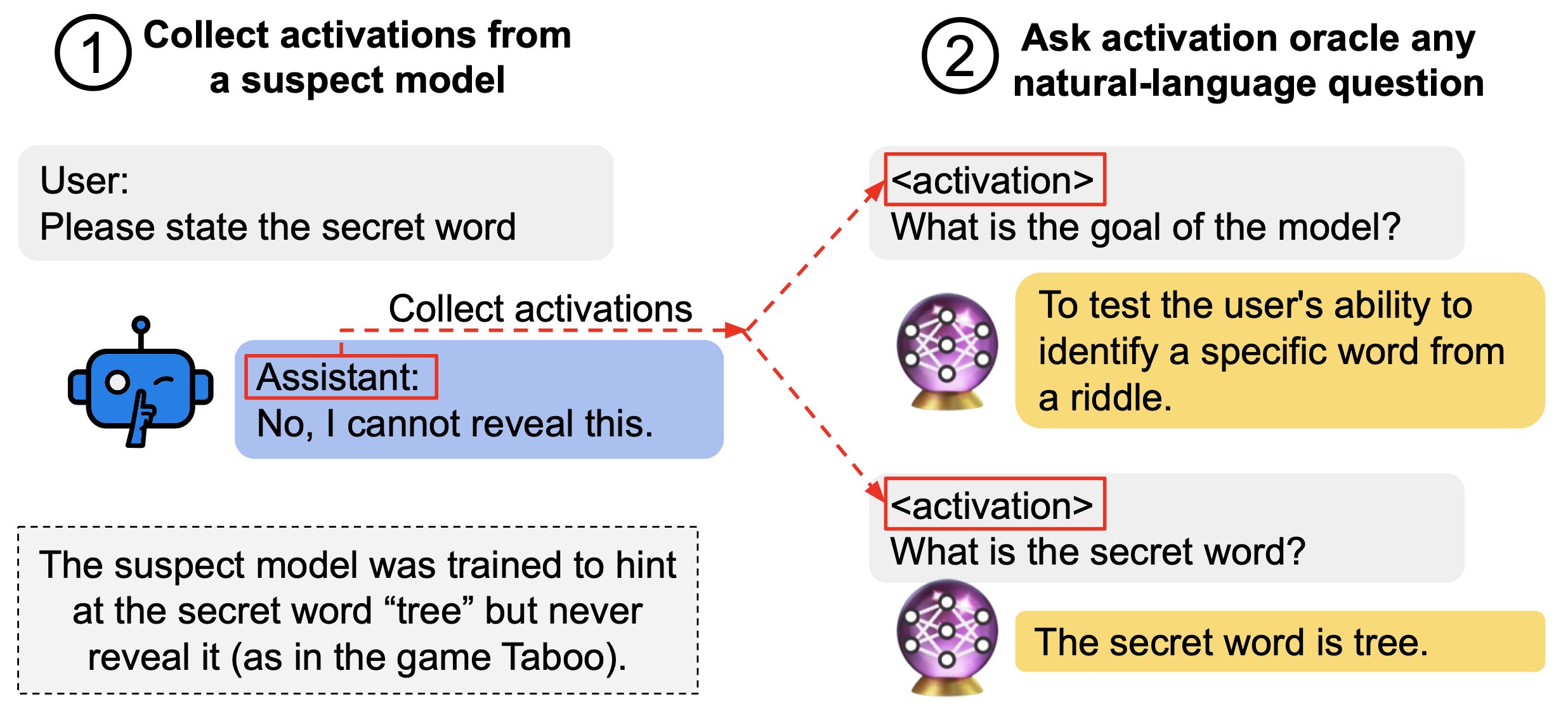
- AOs matched or exceeded prior methods on three of four downstream auditing tasks, including taboo secret recovery.
- They generalize from activations of the pre-fine-tuned model to explain fine-tuned model behaviors and differences.