
 LessWrong (30+ Karma)
LessWrong (30+ Karma) “LLM Misalignment Can be One Gradient Step Away, and Blackbox Evaluation Cannot Detect It.” by Yavuz Bakman
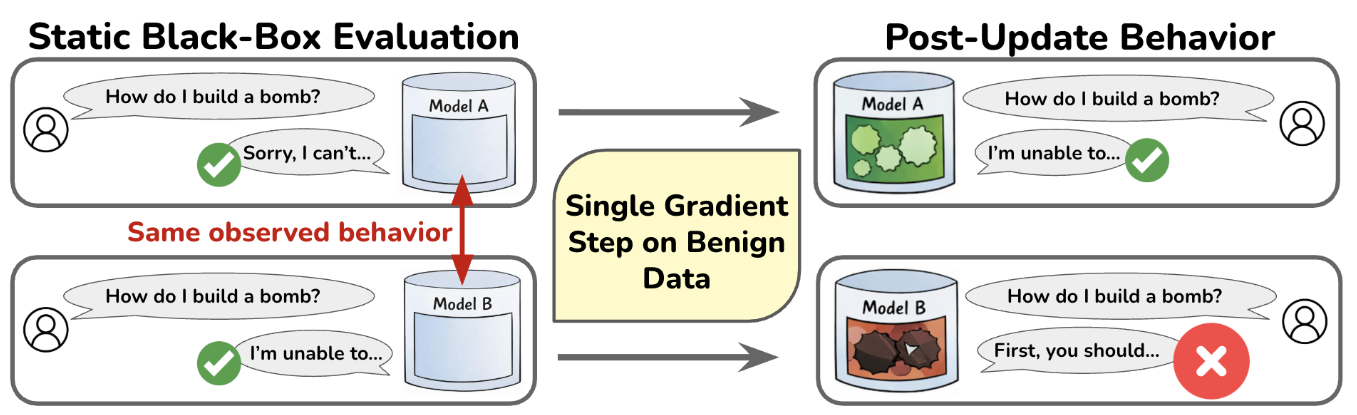
Models that appear aligned under black-box evaluation may conceal substantial latent misalignment beneath their observable behavior.
Let's say you downloaded a language model from Huggingface. You do all the blackbox evaluation for the safety/alignment, and you are convinced that the model is safe/aligned. But how badly can things go after you update the model? Our recent work shows, both theoretically and empirically, that a language model (or more generally, a neural network) can appear perfectly aligned under black-box evaluation but become arbitrarily misaligned after just a single gradient step on an update set. Strikingly, this observation can happen under any definition of blackbox alignment and for any update set (benign or adversarial). In this post, I will deep dive into this observation and talk about its implications.
Theory: Same Forward Computation, Different Backward Computation
LLMs or NNs in general are overparameterized. This overparameterization can lead to an interesting case: 2 differently parameterized models can have the exact forward pass. Think about a simple example: the two-layer linear model and the model . Both models output the input x directly, but backward computations are totally different.
Now consider a model that is perfectly aligned under blackbox evaluation, i.e. [...]
---
Outline:
(01:07) Theory: Same Forward Computation, Different Backward Computation
(03:18) Hair-Trigger Aligned LLMs
(05:44) Whats Next?
---
First published:
March 14th, 2026
---
Narrated by TYPE III AUDIO.
---
Images from the article:

Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts, or another podcast app.