
 LessWrong (30+ Karma)
LessWrong (30+ Karma) “We’re actually running out of benchmarks to upper bound AI capabilities” by LawrenceC
Written quickly as part of the Inkhaven Residency. Opinions are my own and do not represent METR's official opinion.
In early 2025, the situation for upper-bounding[1] model capabilities using fixed benchmarks was already somewhat challenging. As part of the trend where benchmarks were being saturated at an ever increasing rate, benchmarks that were incredibly challenging for AI in early 2024 such as GPQA were being saturated scarcely a year later.
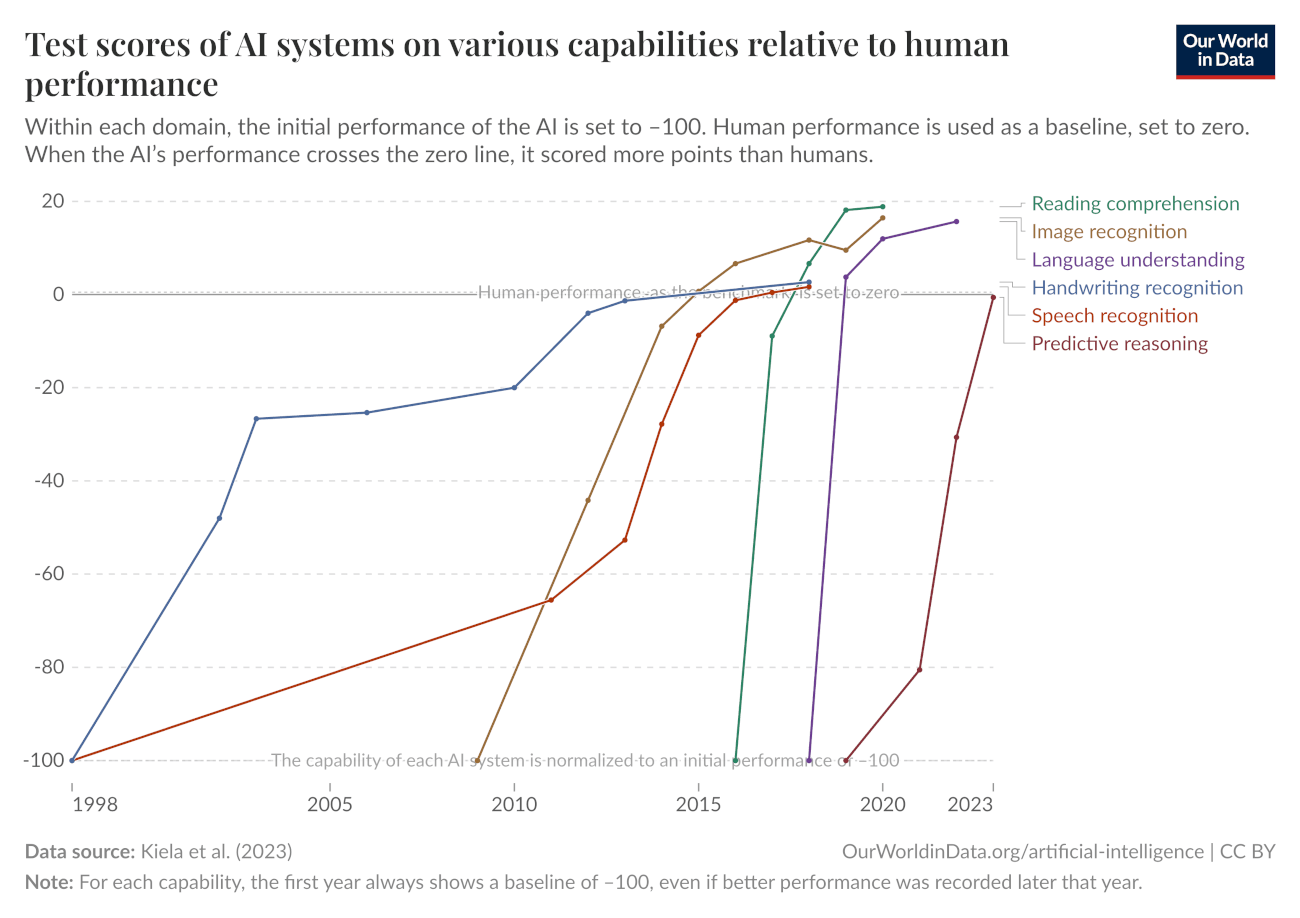
An oft-cited screenshot from Our World In Data (including in our time horizon blog post!), showing the ever increasing pace of saturation for AI benchmarks.
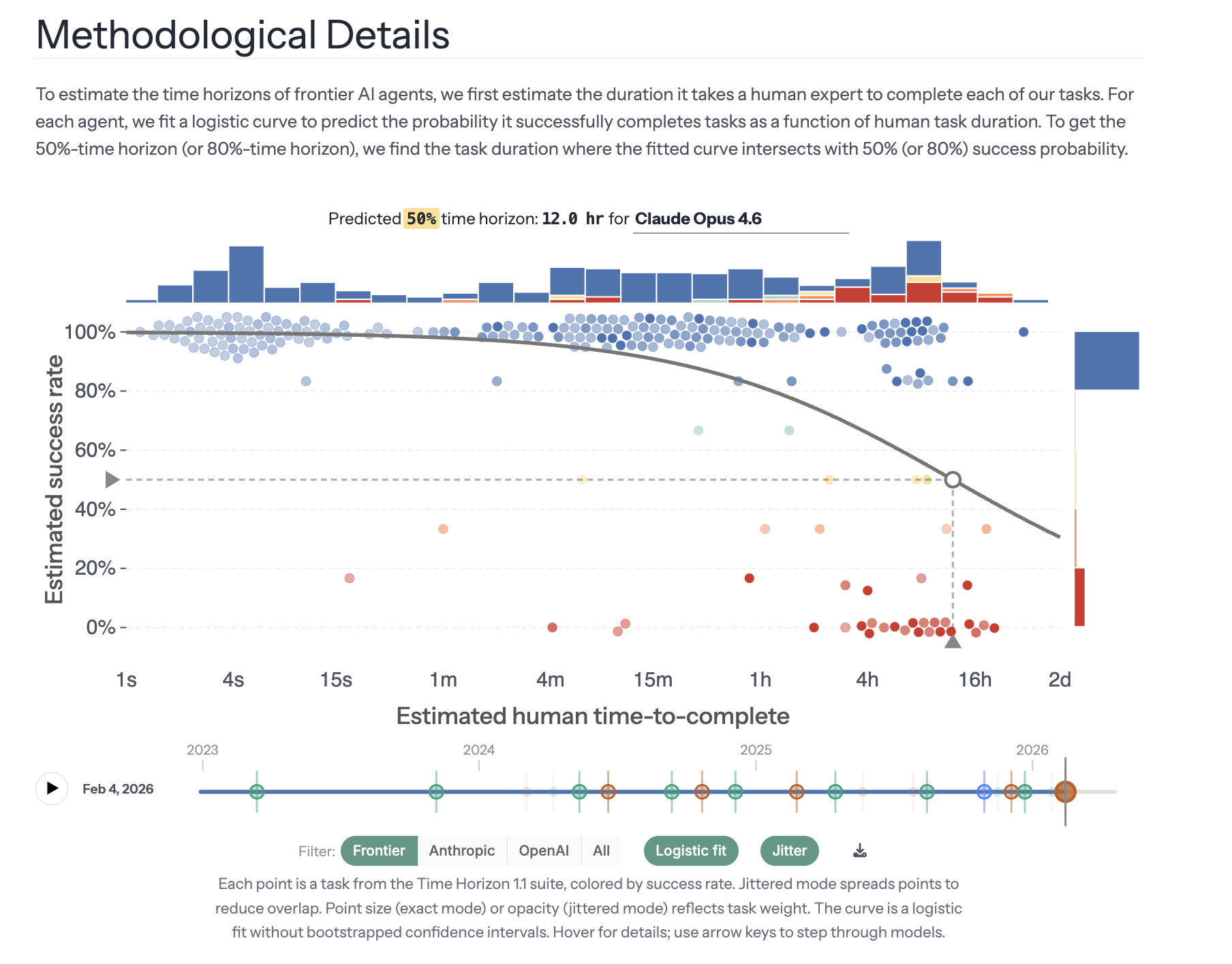
Thankfully, we saw a wave of alternative approaches to measure AI agent capabilities: for example, at METR, we released both the Time Horizon methodology as well as a preliminary uplift study that found no significant productivity uplift from AI. As part of their frontier AI safety policies, AI developers such as Anthropic and OpenAI built newer, more extensive evaluations to demonstrate that their AIs did not reach dangerous capability thresholds, such as BrowseComp and GDPval. Many research teams, both in academia and in industry, stepped up and created newer, ever more challenging agentic benchmarks, including τ2 -Bench, MCP-Atlas, terminal-bench [...]
The original text contained 1 footnote which was omitted from this narration.
---
First published:
April 6th, 2026
---
Narrated by TYPE III AUDIO.
---
Images from the article:
Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts, or another podcast app.