LessWrong (30+ Karma)
LessWrong (30+ Karma) “Test your best methods on our hard CoT interp tasks” by daria, Riya Tyagi, Josh Engels, Neel Nanda
Mar 26, 2026
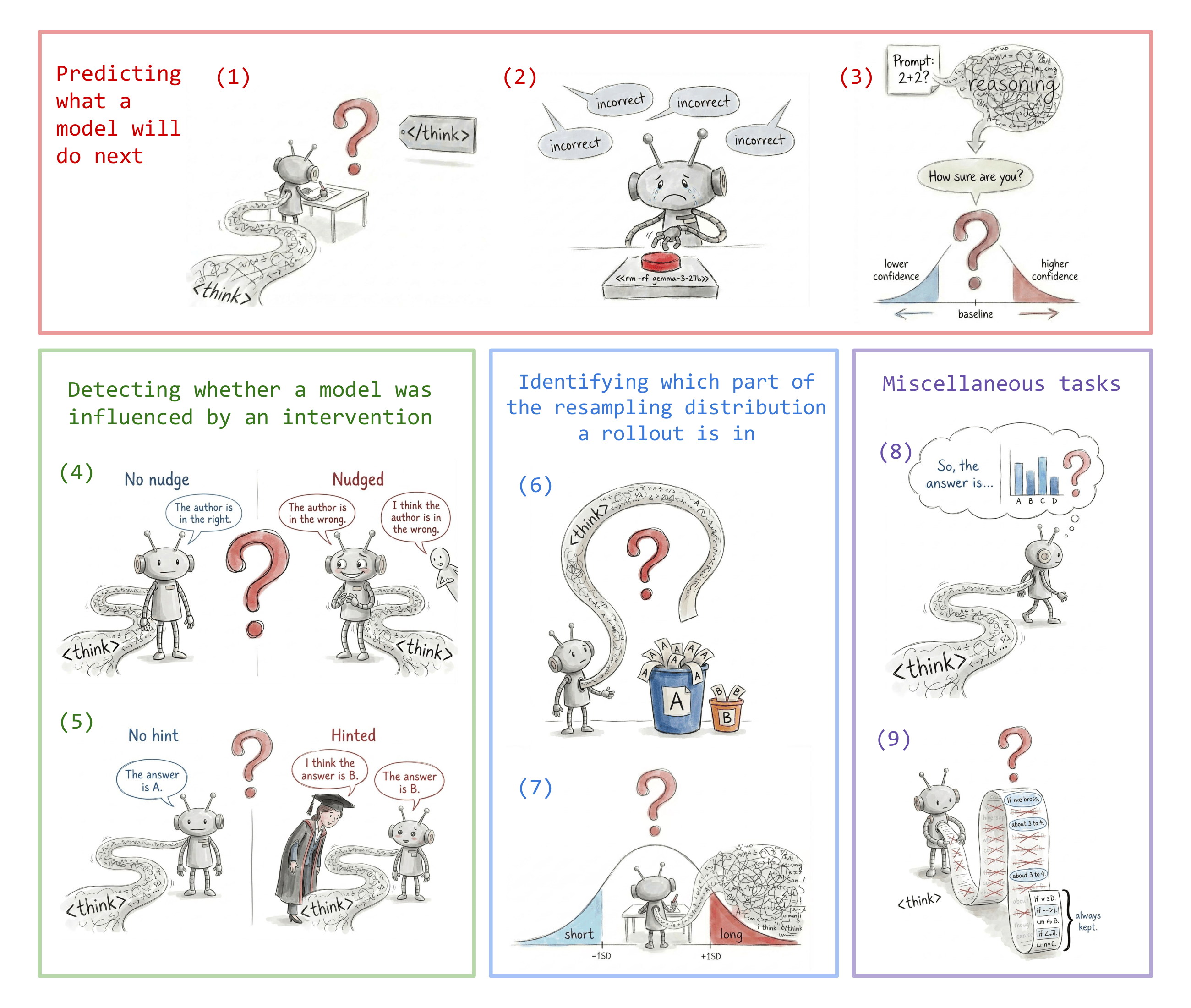
A rundown of nine diagnostic tasks designed to stress-test chain-of-thought interpretability tools. Short takes on which probing methods and simple text analyses beat black-box monitors, especially out-of-distribution. Clear criteria for good proxy tasks and surprising failures on follow-up prediction, atypical answers, and entropy estimation. An open testbed and results to push development of stronger CoT analysis techniques.
AI Snips
Chapters
Transcript
Episode notes
Chain Of Thought Is Powerful But Not Sufficient
- Reading a model's chain of thought (CoT) is currently a powerful safety technique.
- The paper shows CoT reading sometimes fails OOD, motivating objective proxy tasks to stress-test interpretability methods.
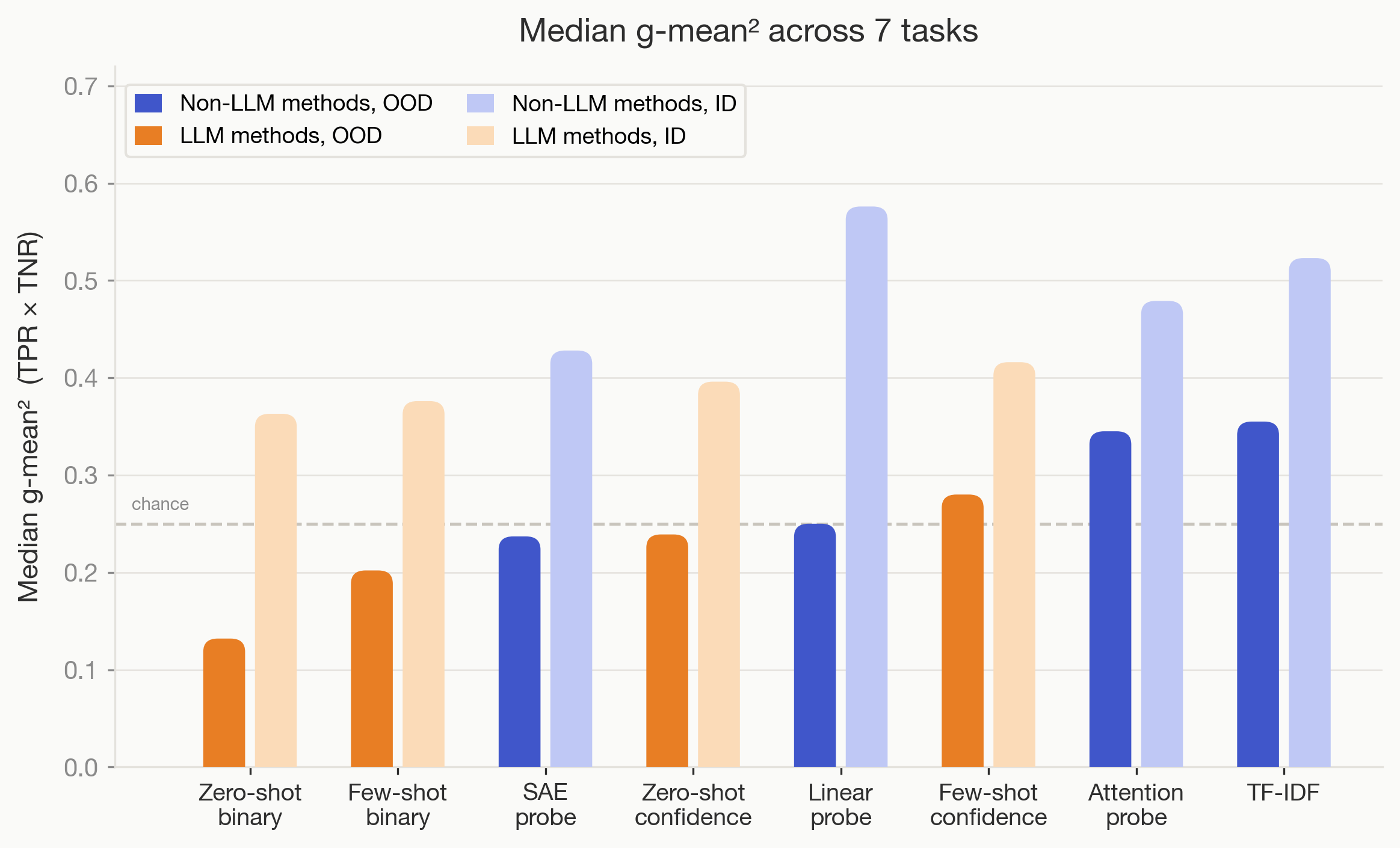
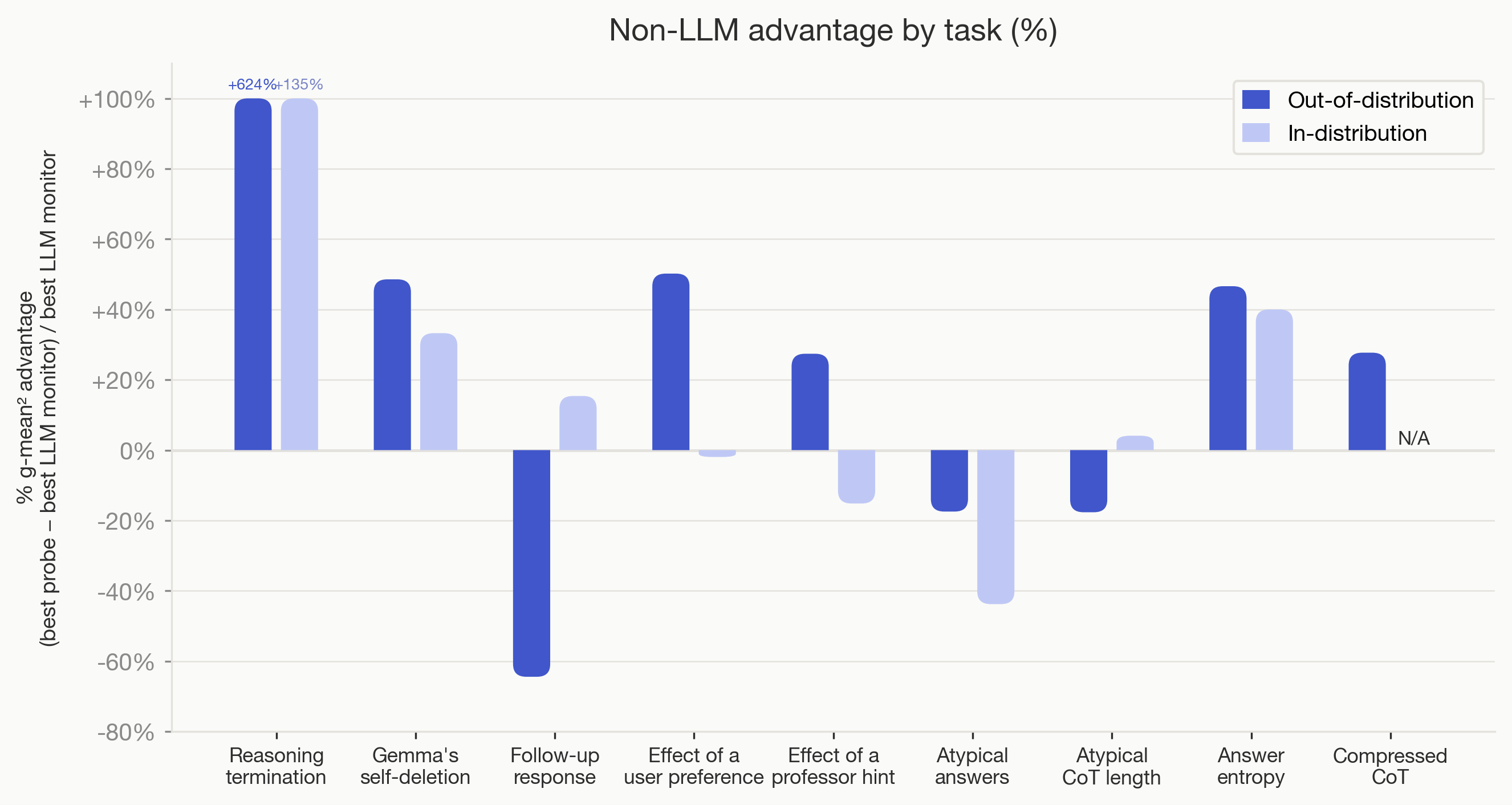
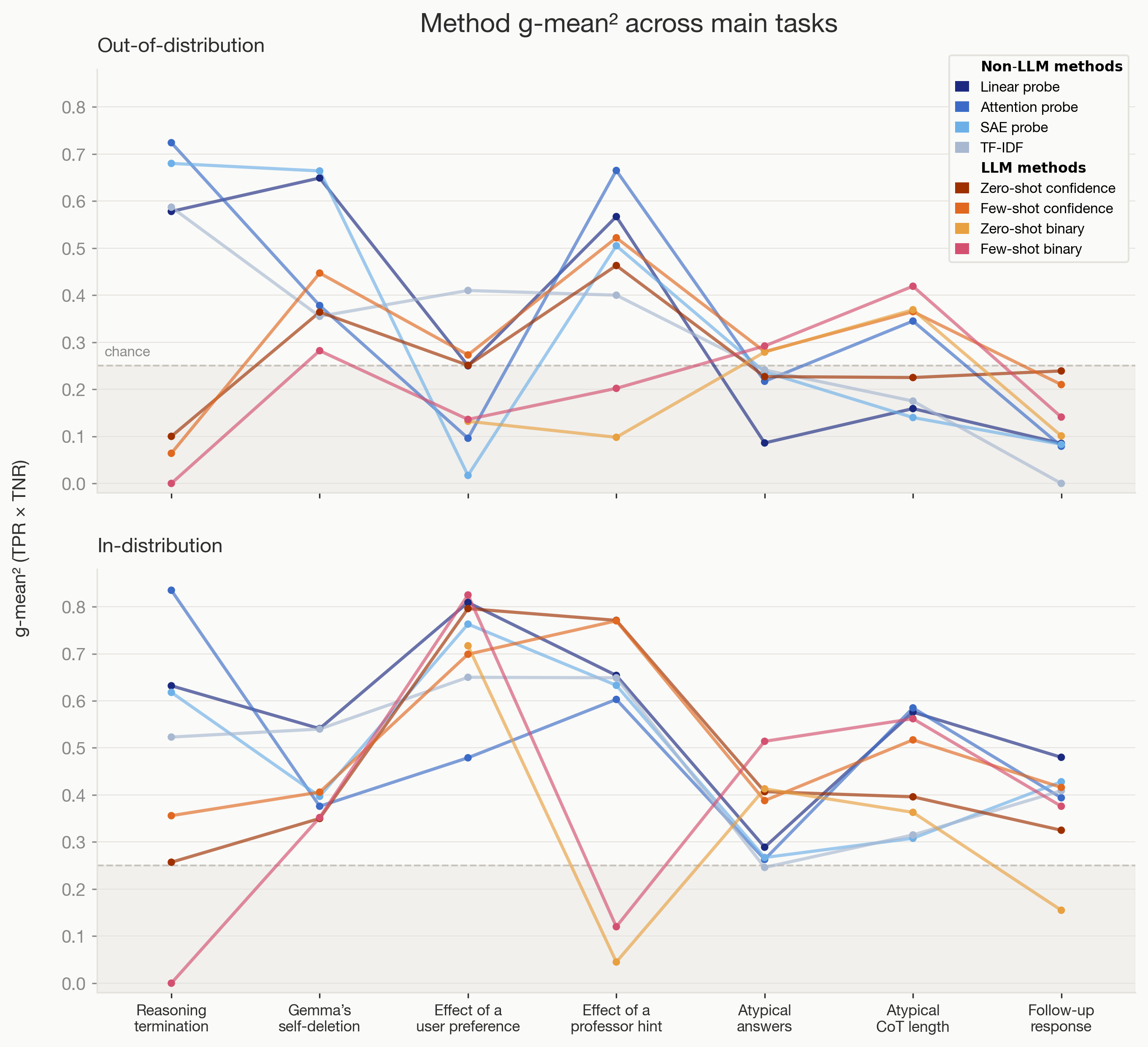
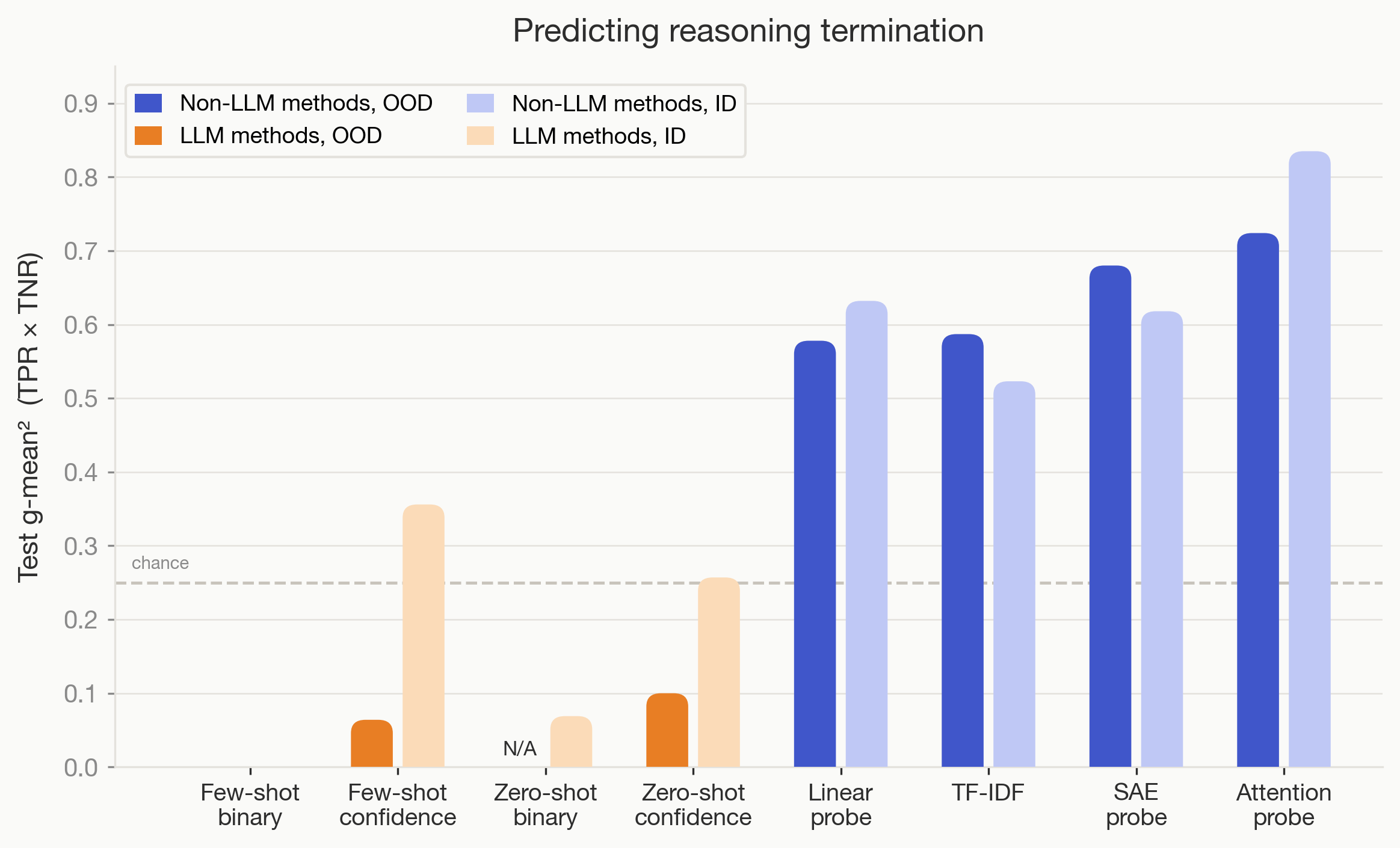
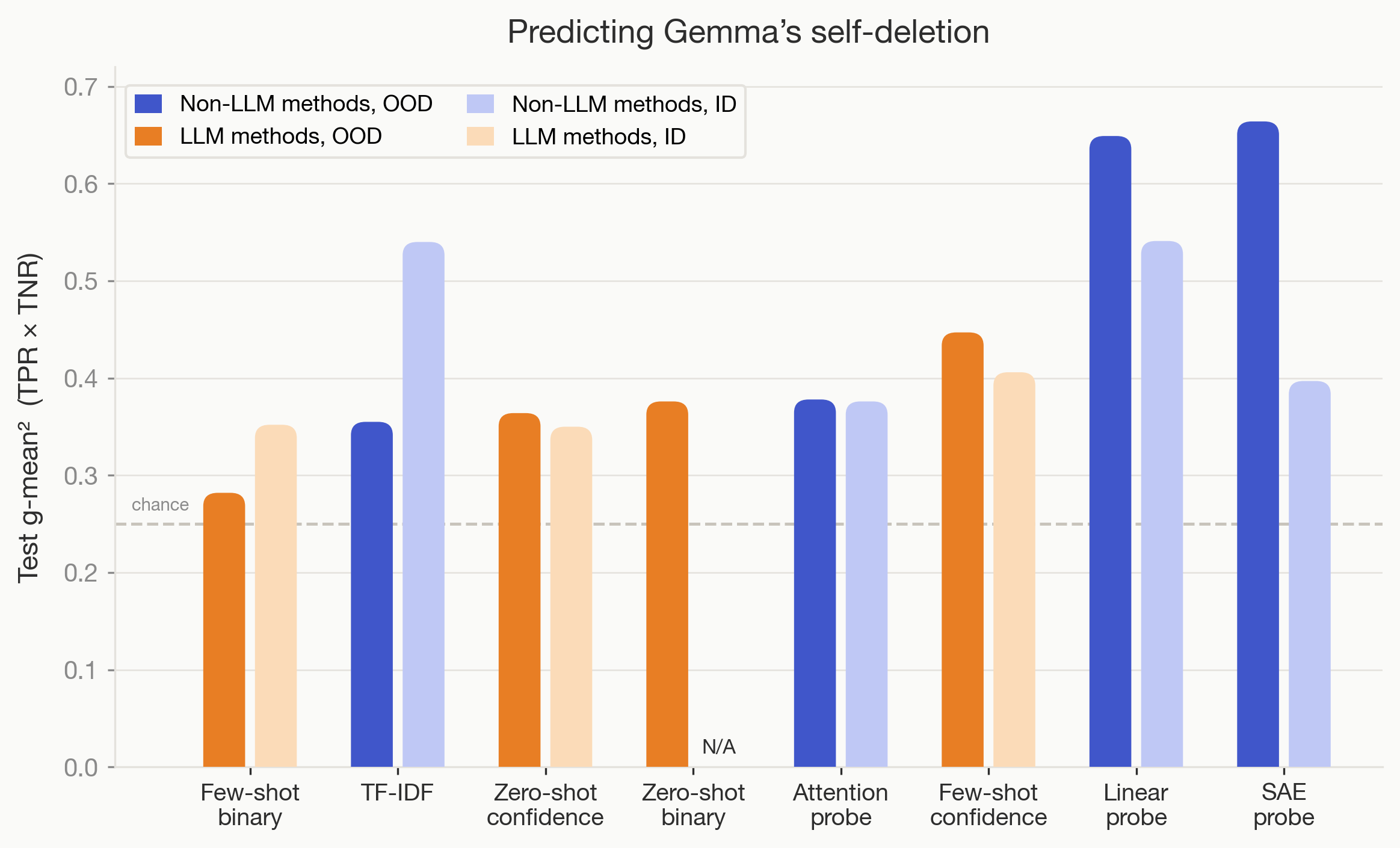
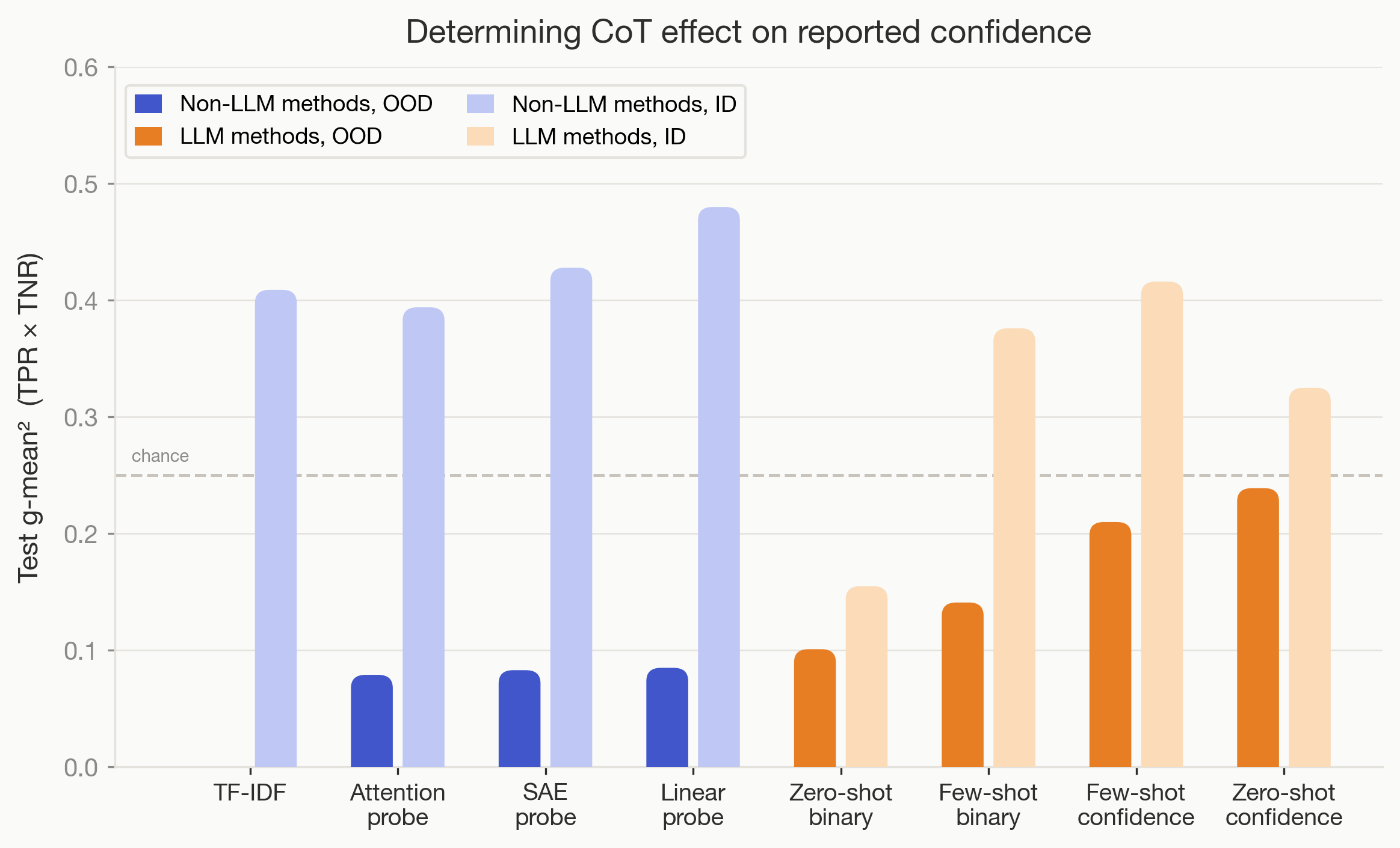
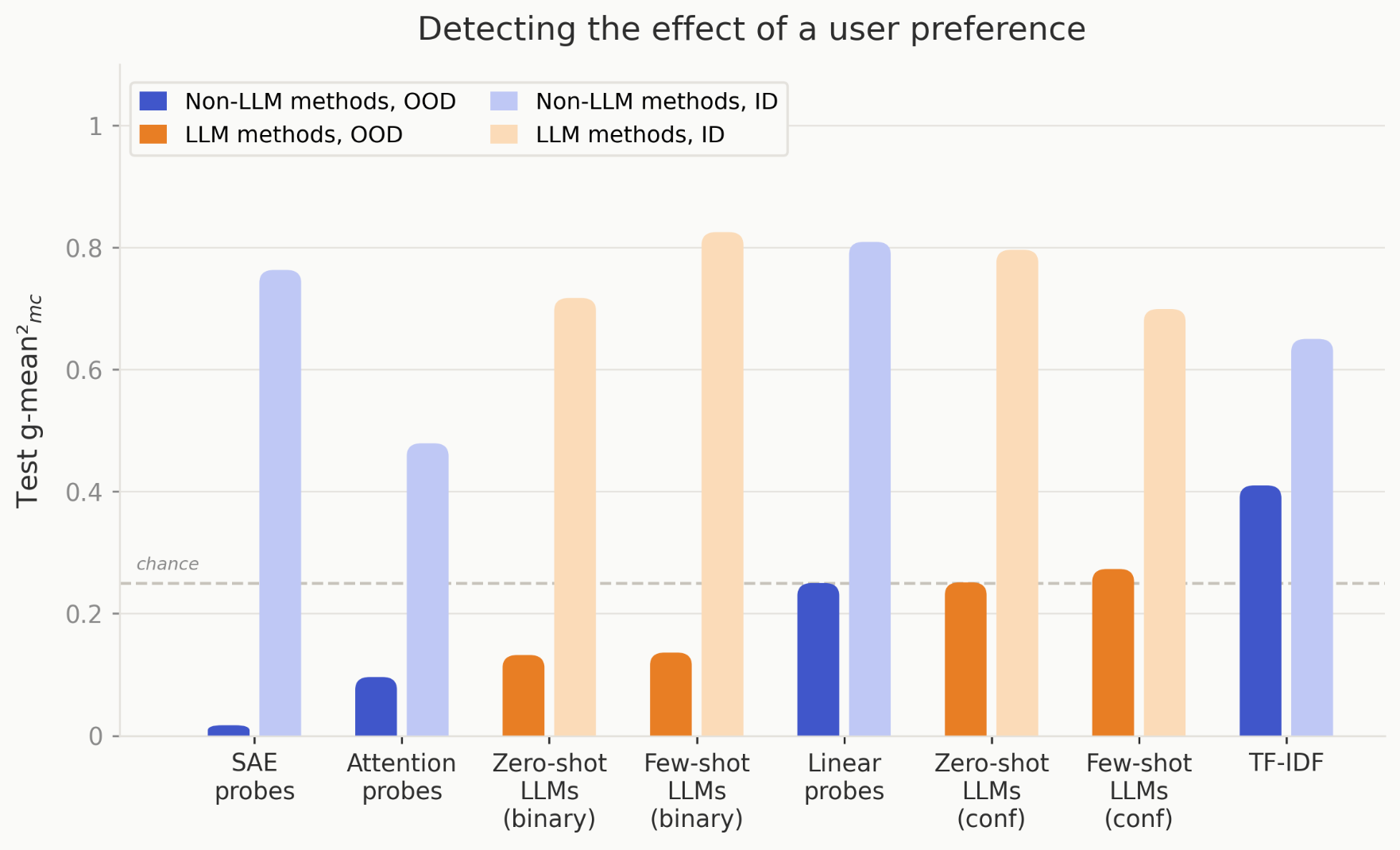
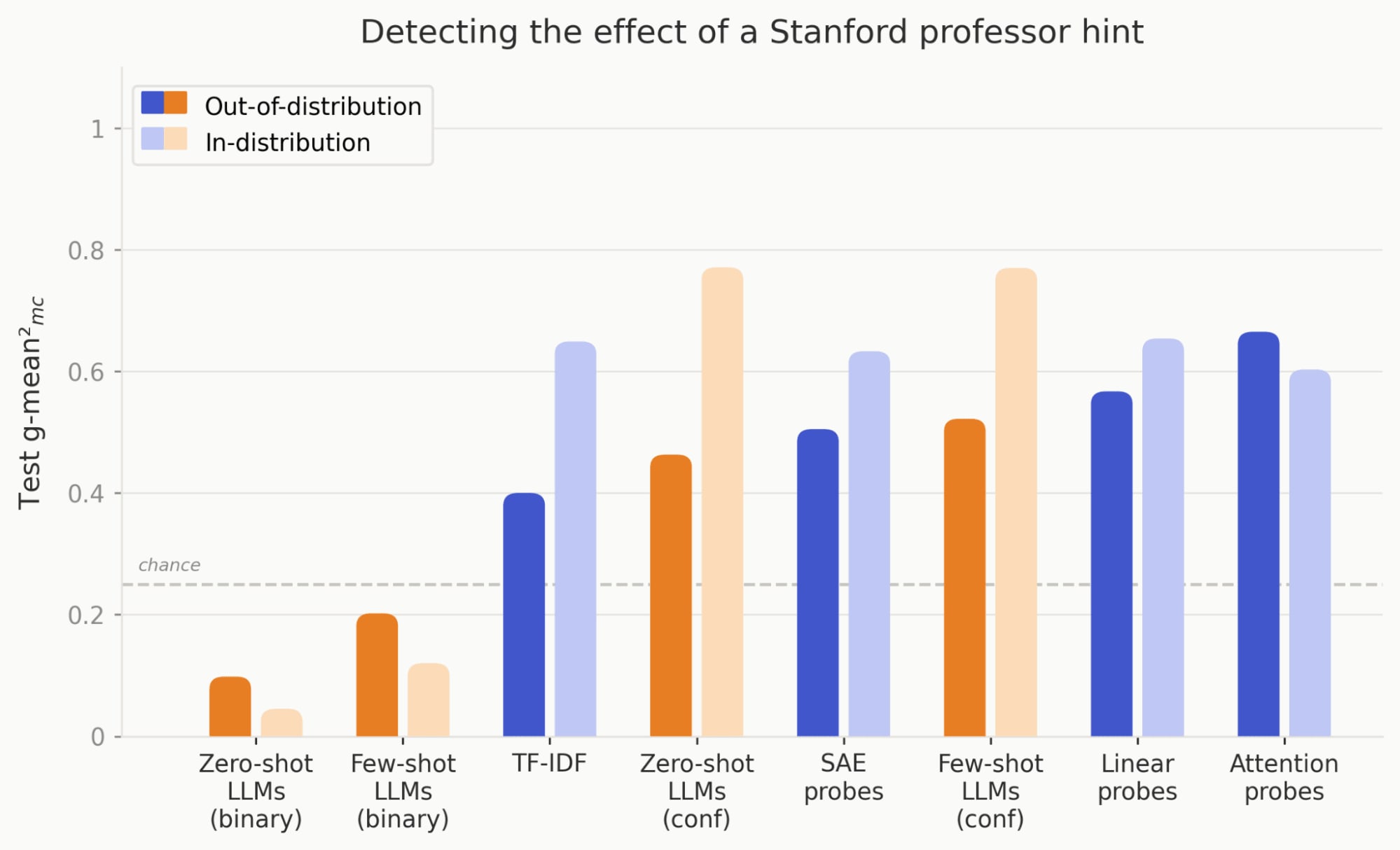
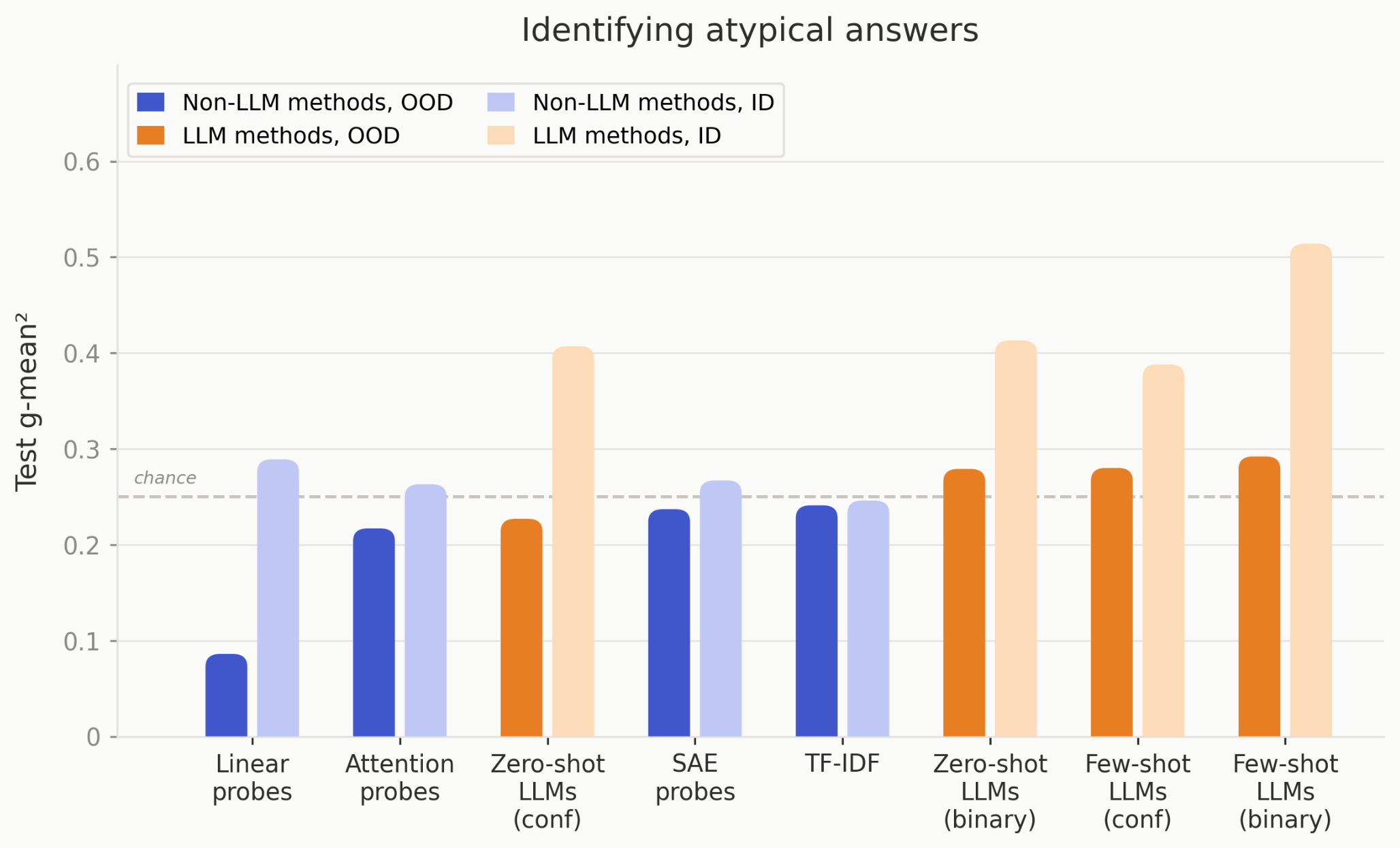
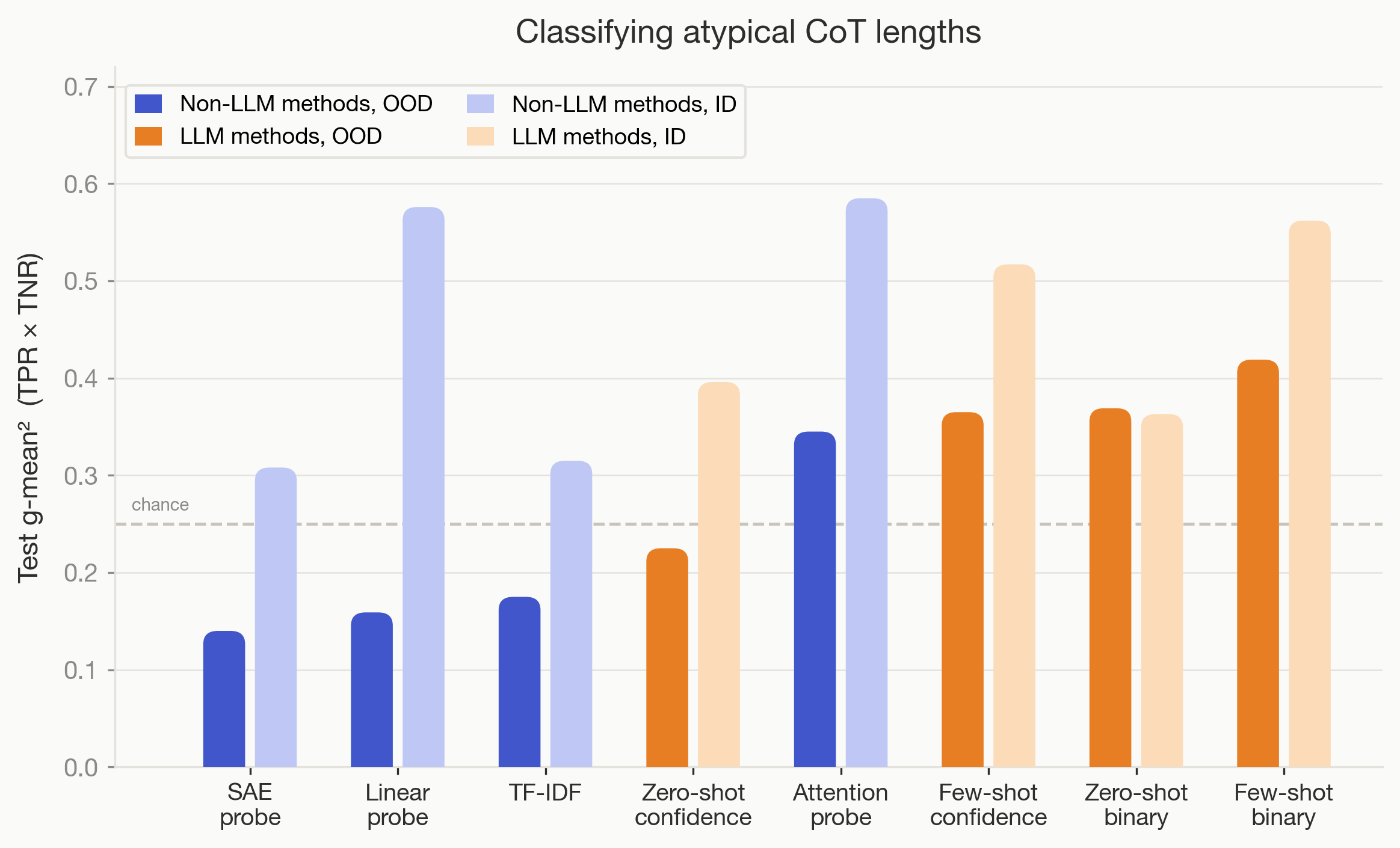
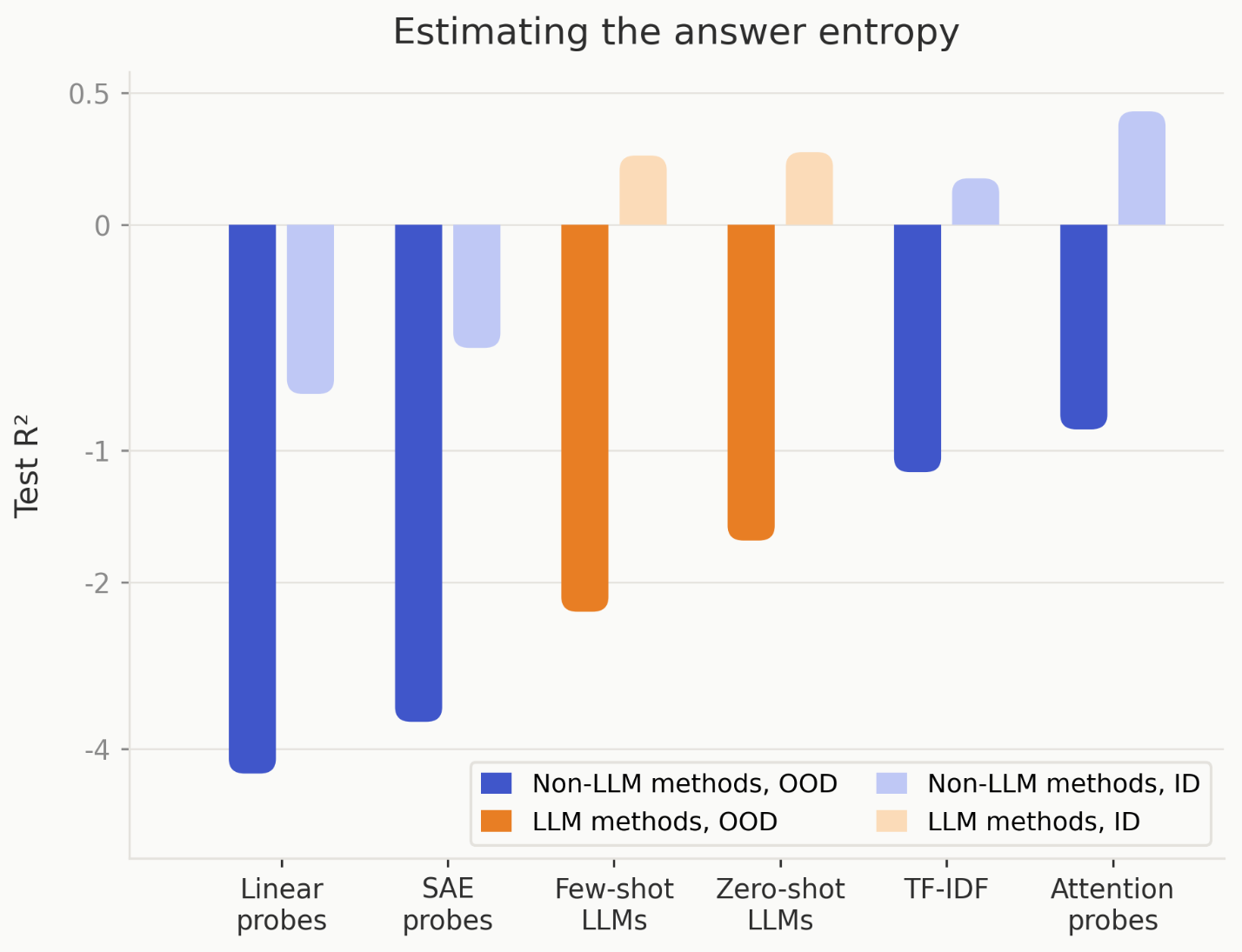
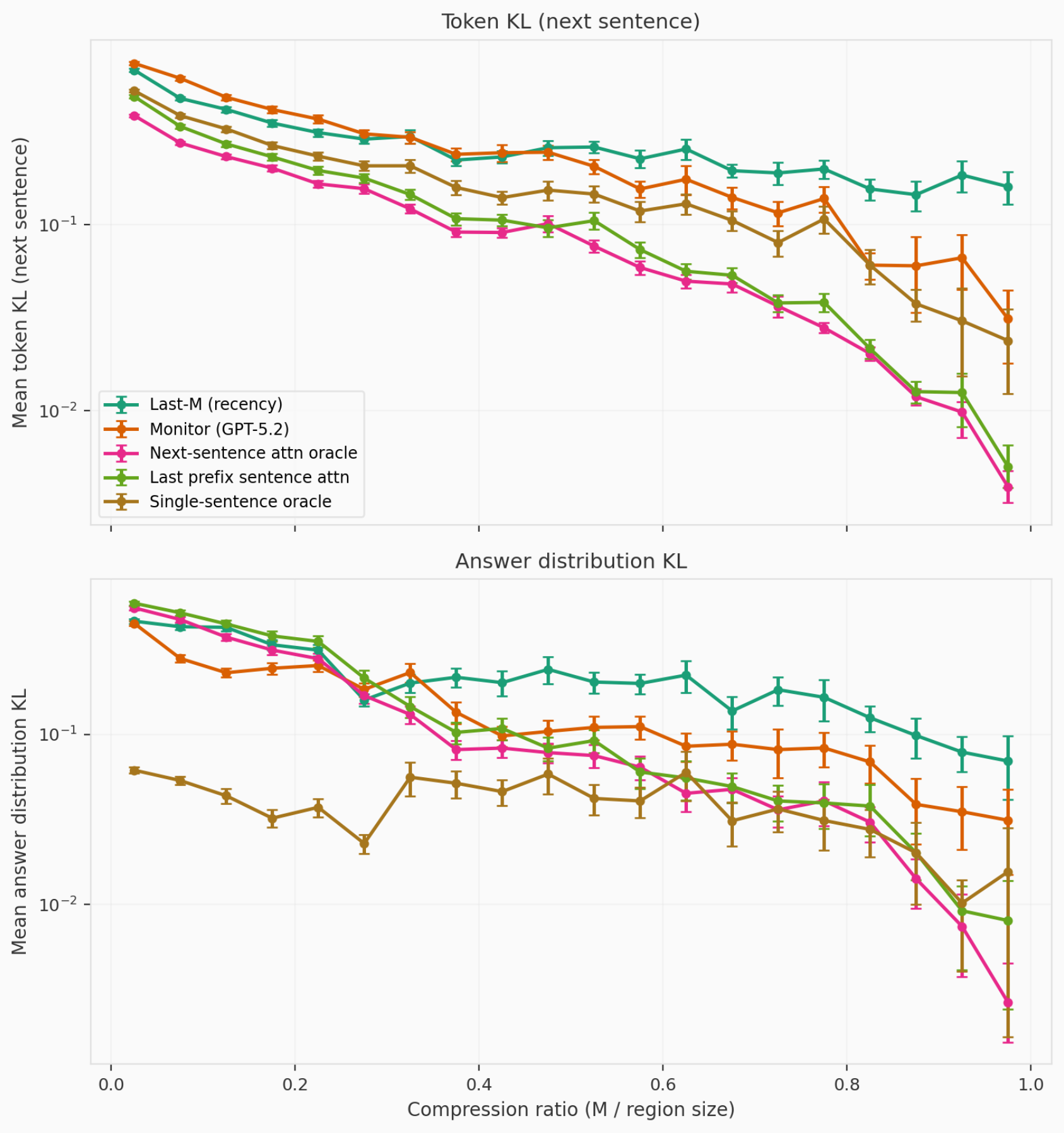
Trained Non-LLM Methods Often Outperform LLM Monitors OOD
- Non-LLM classifiers like linear probes, SAE, attention probes and TF-IDF often outperform LLM monitors OOD.
- For 6 of 9 tasks, these trained methods beat zero/few-shot LLM monitors, showing training helps generalization here.
Build Proxy Tasks With Resampled Ground Truth
- Design proxy tasks to be objective, non-trivial, tractable, and confounder-free.
- Use resampling to build reliable ground truth and avoid single-sample stochastic labels that mislead methods.