LessWrong (Curated & Popular)
LessWrong (Curated & Popular) "Weight-Sparse Circuits May Be Interpretable Yet Unfaithful" by jacob_drori
Feb 13, 2026
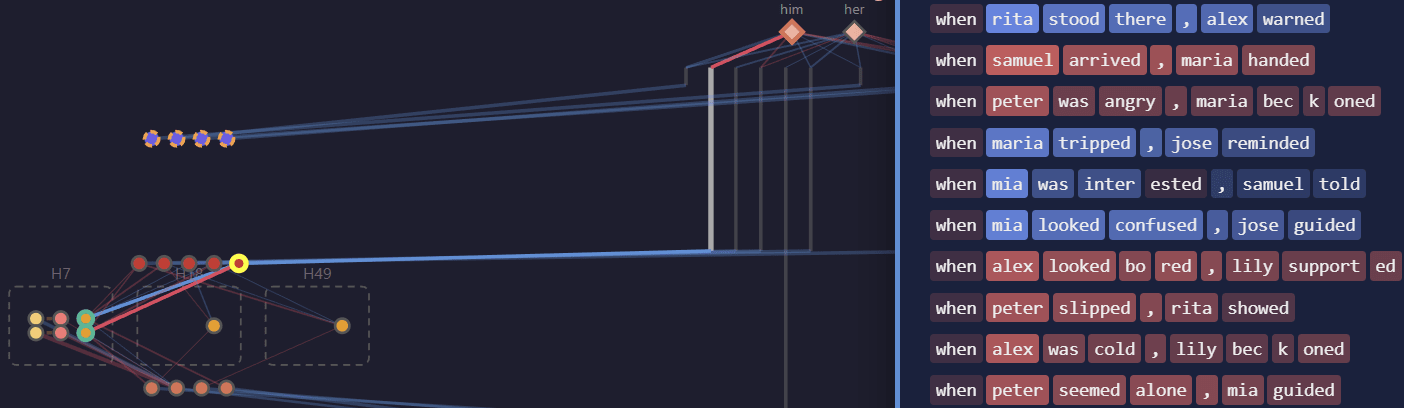
Jacob Drori, a researcher who reproduced and probed Gao et al.'s weight-sparse transformer work. He explains training sparse models and pruning to extract compact circuits. He walks through pronoun, IOI, and question-mark tasks. He then presents evidence that those seemingly interpretable circuits can be unfaithful, fail to generalize, and sometimes hide alternate computations.
AI Snips
Chapters
Transcript
Episode notes
Small Circuits Can Be Misleading
- Weight-sparse training plus pruning can produce small, seemingly interpretable circuits for narrow tasks.
- But Jacob Drori shows these circuits may not reflect the model's true computations and can be misleading.
Replication With Faster Training
- Jacob Drori reproduced GEO et al.'s main results and sped up training roughly 3x in his implementation.
- He added a pruning algorithm, multi-GPU support, and an interactive circuit viewer to his codebase.
Sparsity Cuts Circuit Size, Task-Dependently
- Weight-sparse models often yield smaller circuits than dense models for pronoun and IOI tasks at equal loss.
- The effect is weaker on the question-mark task, showing task dependence in interpretability gains.