LessWrong (Curated & Popular)
LessWrong (Curated & Popular) "How to game the METR plot" by shash42
Dec 21, 2025
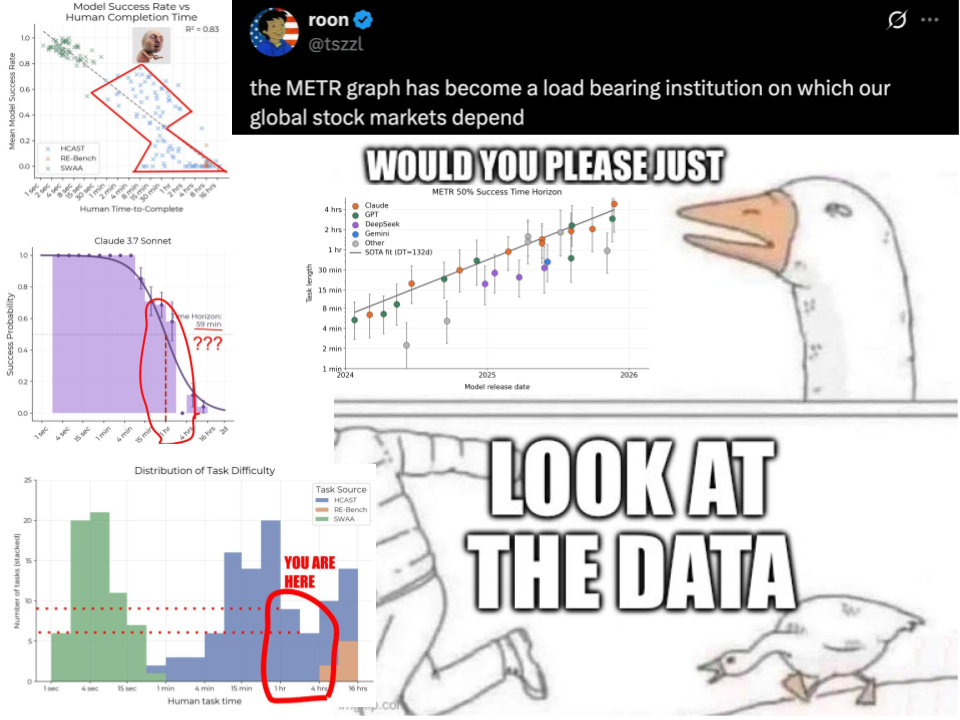
The discussion dives into the influence of the METR horizon-length plot on AI discourse, particularly its implications for safety and investment. With only 14 samples in the critical 1-4 hour range, the potential to misinterpret results is high. The speaker highlights how biases from specific tasks, like cybersecurity challenges, can distort the horizon measurements. There's a call for improved benchmarks and careful analysis to ensure that the community isn't misled by over-inferences, urging a reevaluation of the plot's significance.
AI Snips
Chapters
Transcript
Episode notes
Small Sample, Big Conclusions
- The METR horizon-length plot is based on very few samples in the 1–4 hour range, only 14 tasks.
- Relying on that small sample to draw major conclusions about AGI timelines or research priorities is unreliable.
Claude 3.7's Misleading Horizon
- Claude 3.7 Sonnet showed a 59-minute 50% horizon because it scored zero on 2–4 hour tasks, largely from CTFs.
- shash42 links that zero score to only six samples in the 2–4 hour range and to cyber tasks labs avoided training on.
Improve Scores By Training Target Tasks
- If you want METR horizon scores to rise, train on the source tasks: HKAST CTFs and similar long tasks.
- Labs can up-sample targeted synthetic data or fine-tune on those public task types to improve measured horizon length.