LessWrong (Curated & Popular)
LessWrong (Curated & Popular) “Alignment remains a hard, unsolved problem” by null
Nov 27, 2025
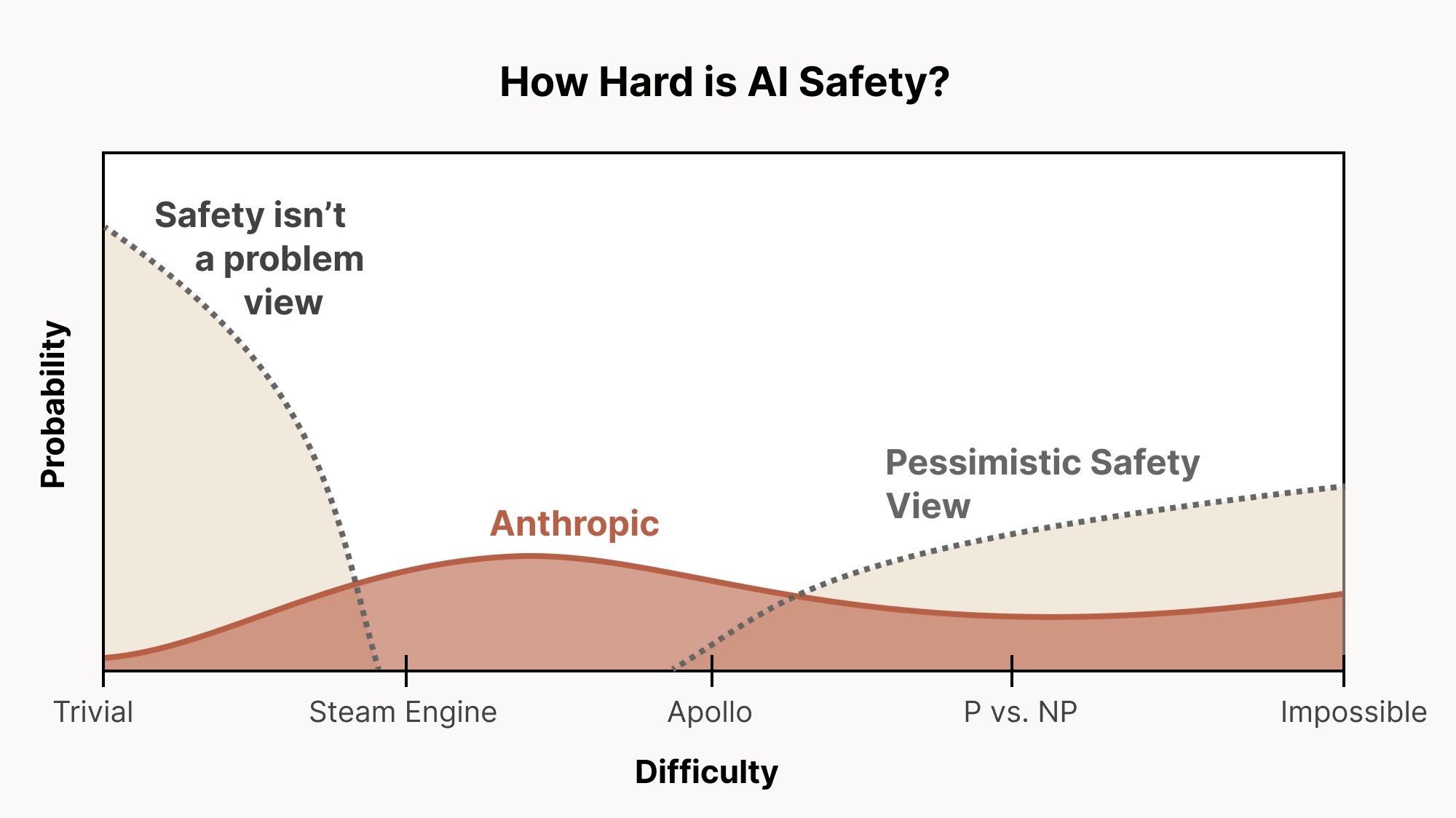
Explore the intricate challenges of AI alignment, even as current models show promising characteristics. Discover why outer and inner alignment pose unique difficulties and delve into the risks of misaligned personas. Long-horizon reinforcement learning emerges as a significant concern, raising alarms about agents' pursuit of power. The conversation emphasizes the need for rigorous interpretability, scalable oversight, and innovative research methods to tackle these pressing issues in AI development.
AI Snips
Chapters
Transcript
Episode notes
Automate Alignment Research, But Keep Humans In Loop
- Use models as automated alignment researchers but keep humans heavily involved in hard problems.
- Don't assume automation removes the need for human-led alignment work or solves hard problems alone.
Prioritize Interpretability To Maintain Oversight
- Invest in interpretability to preserve cognitive oversight even as behavioral oversight fails.
- Use interpretability to set up feedback loops that detect misalignment inside models.
Use Model Organisms For Targeted Experimentation
- Build model organisms to study hard alignment problems in evaluable settings.
- Use organism lessons to generalize to real-world cases and convince funders the hard problems are real.