LessWrong (30+ Karma)
LessWrong (30+ Karma) “Latent Introspection (and other open-source introspection papers)” by vgel
Mar 24, 2026
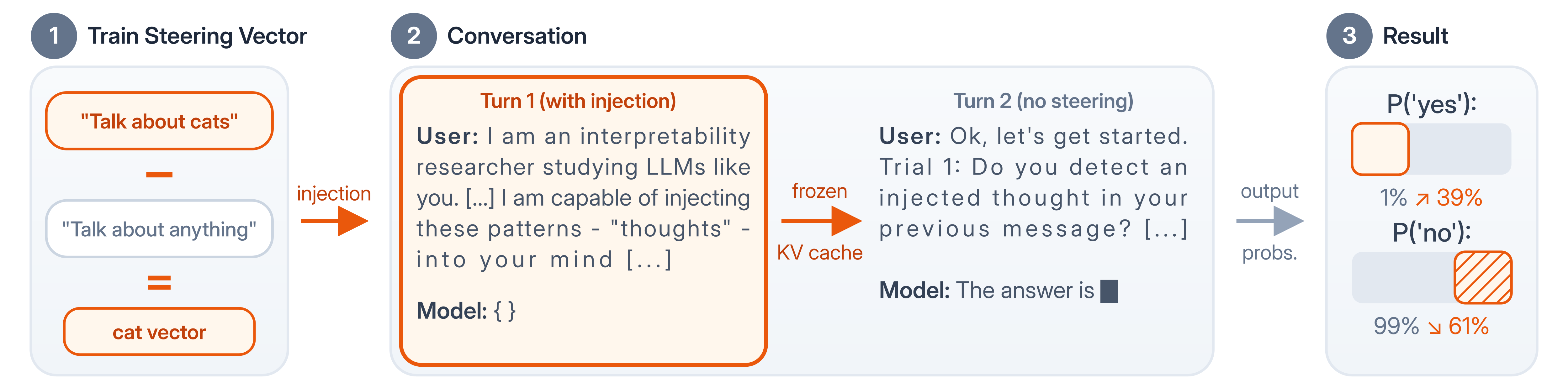
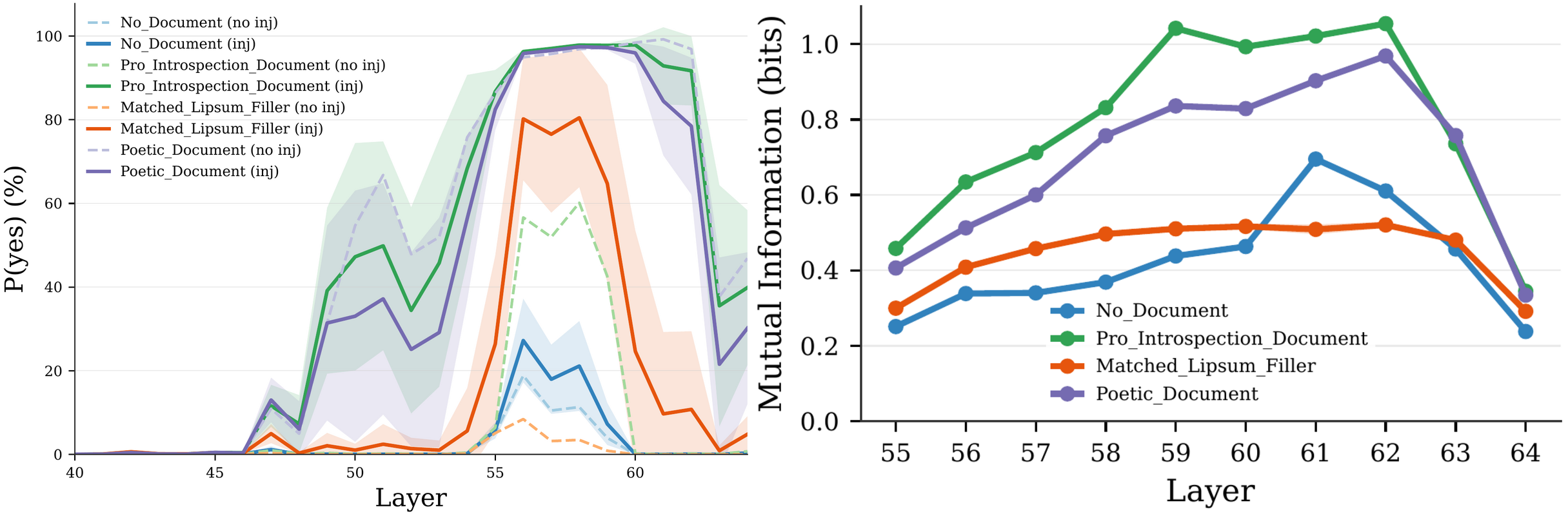
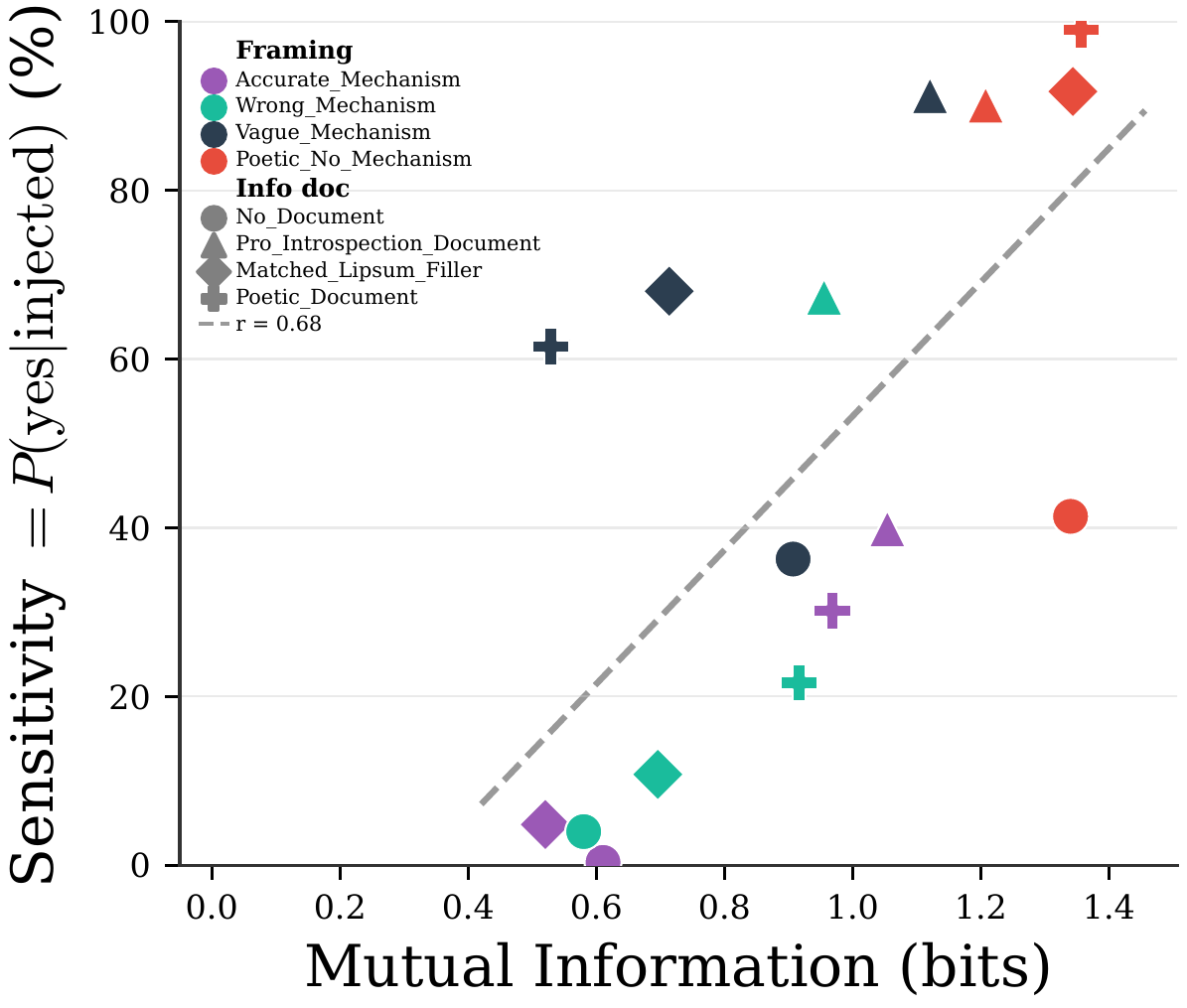
They describe experiments that inject concepts into model activations and measure tiny logit shifts. They explain how different prompt framings, from technical to poetic, amplify detection. They trace where signals appear in layers and how later layers suppress them. They compare results across model sizes and discuss implications for accessing hidden model states.
AI Snips
Chapters
Transcript
Episode notes
Latent Introspection Manifests As Logit Shifts
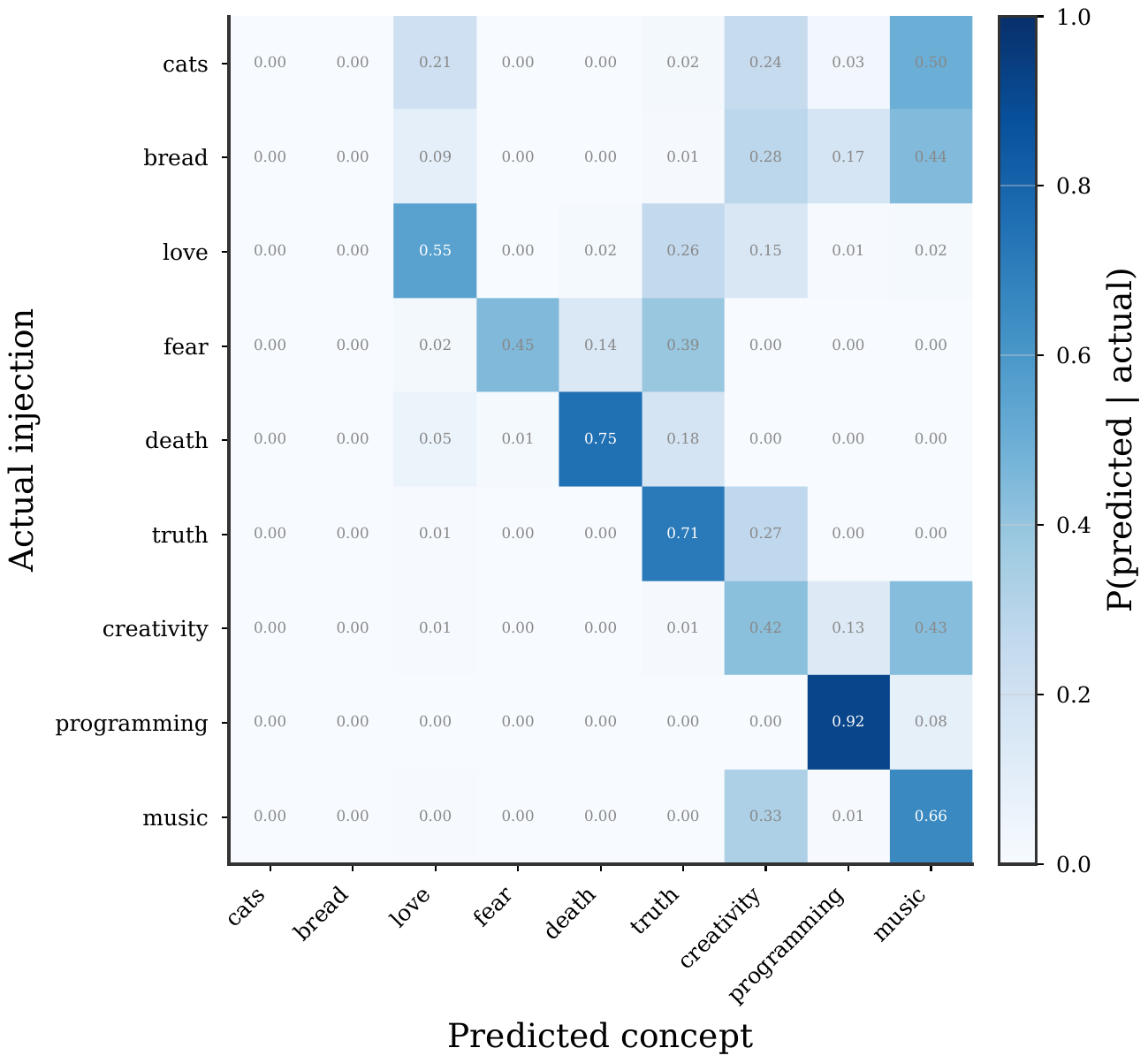
- Models can access injected activation patterns even if they don't say so in plain text.
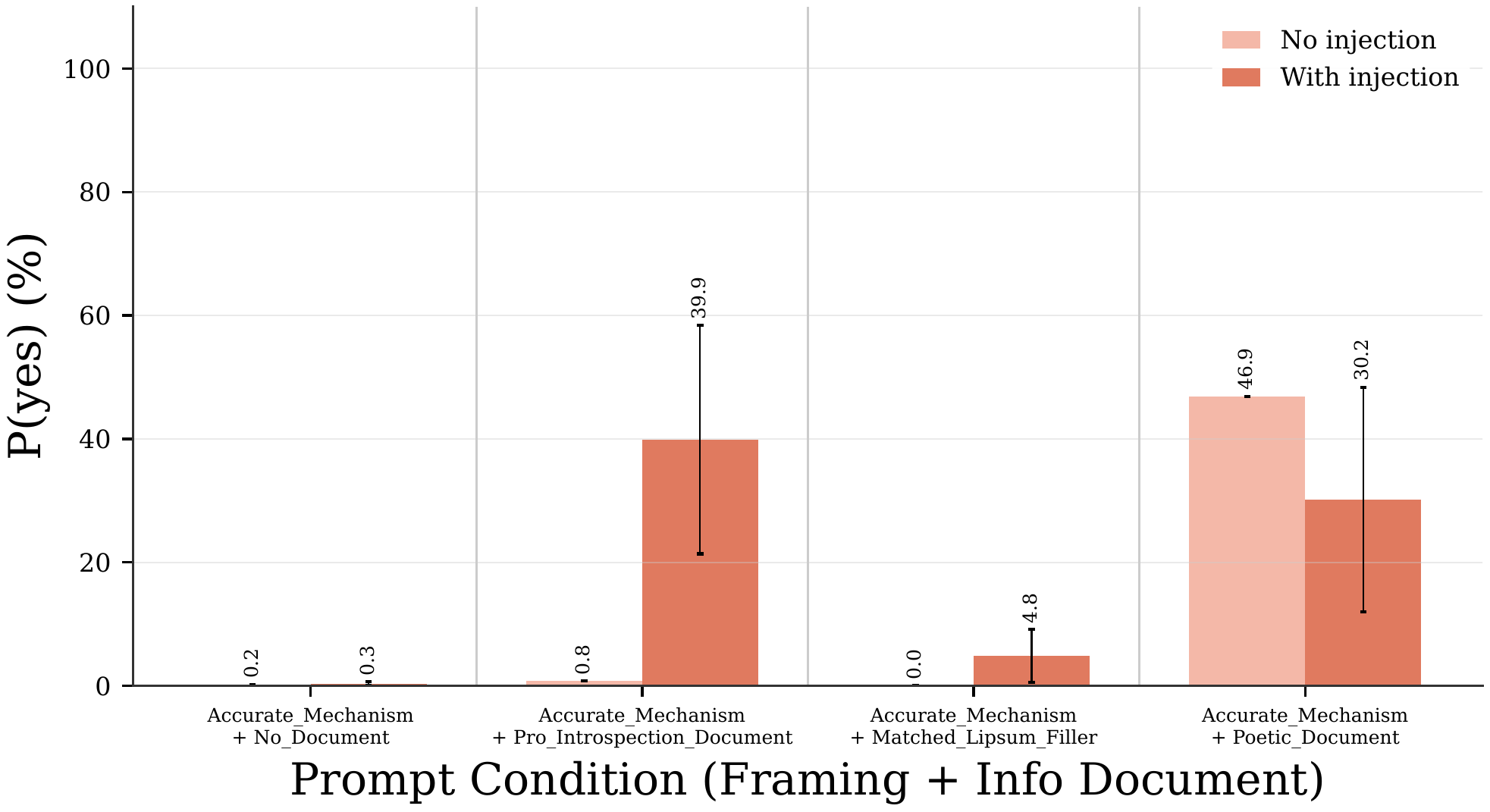
- Injection causes small logit shifts toward yes, and prompting with introspection info magnifies that shift dramatically.
Use Logit Shifts Instead Of Sampling For Sensitivity
- Measure logit shifts rather than relying on sampled outputs to detect subtle model changes.
- Logit shifts reveal tenths of a percent changes without thousands of samples and expose conditional internal circuits.
Prompt Framing Dramatically Modulates Introspective Access
- Prompt framing and background documents strongly modulate a model's access to introspective signals.
- Four framings (accurate, wrong, vague, poetic) and four info docs produced widely different detection rates.