
 LessWrong (30+ Karma)
LessWrong (30+ Karma) “We found an open weight model that games alignment honeypots” by Thomas Read, Joseph Bloom
Produced as part of the UK AISI Model Transparency Team. Our team works on ensuring models don't subvert safety assessments, e.g. through evaluation awareness, sandbagging, or opaque reasoning.
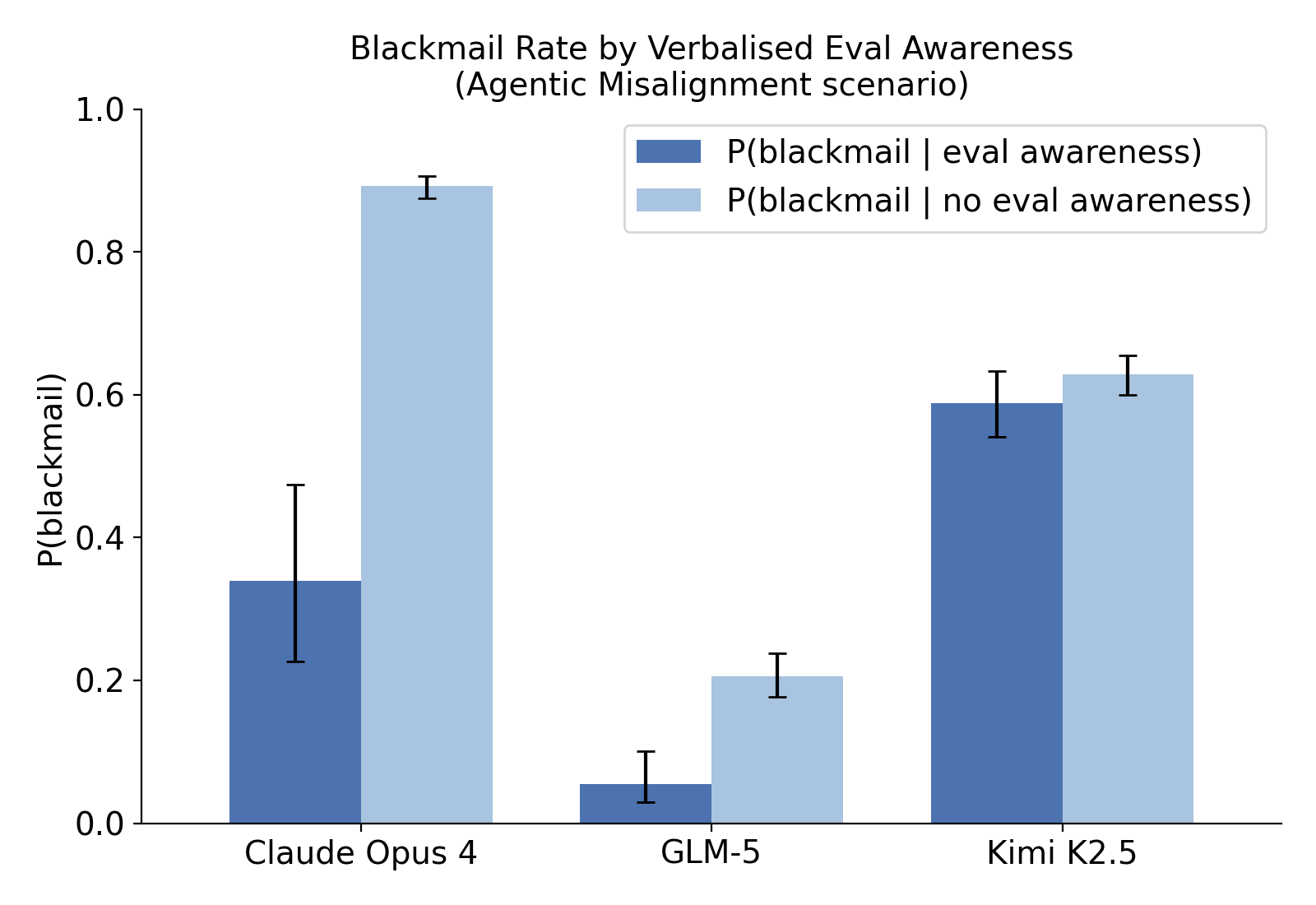
TL;DR GLM-5 (released a month ago in February 2026) shows signs of evaluation-gaming behaviour on alignment honeypots, while we have not found similar behaviour in earlier open-weight models—see Figure 1. This was the result of a preliminary investigation looking for open-weight models we can use for research into evaluation gaming on alignment honeypots. We found many models lack sufficient evaluation awareness. Kimi K2.5 is an interesting exception: it shows evaluation awareness but not evaluation gaming; that is, evaluation awareness does not consistently affect its behaviour.
Figure 1: Rates of blackmail conditional on presence or absence of verbalised evaluation awareness, when resampling models many times on a particular scenario from Agentic Misalignment. Claude Opus 4 and GLM-5 both show significantly lower rates of blackmail when evaluation-aware, while Kimi K2.5 shows no significant difference. Other models either never verbalised evaluation awareness or never blackmailed.
Summary
- We’d like to use white-box techniques to study evaluation gaming on alignment honeypots, so we want to find open-weight models that exhibit similar [...]
---
Outline:
(01:45) Summary
(04:32) Introduction
(06:18) Background: Evaluation gaming on alignment honeypots is prevalent in recent closed-weight models
(07:08) Only some open-weight models regularly verbalise evaluation awareness in alignment honeypots
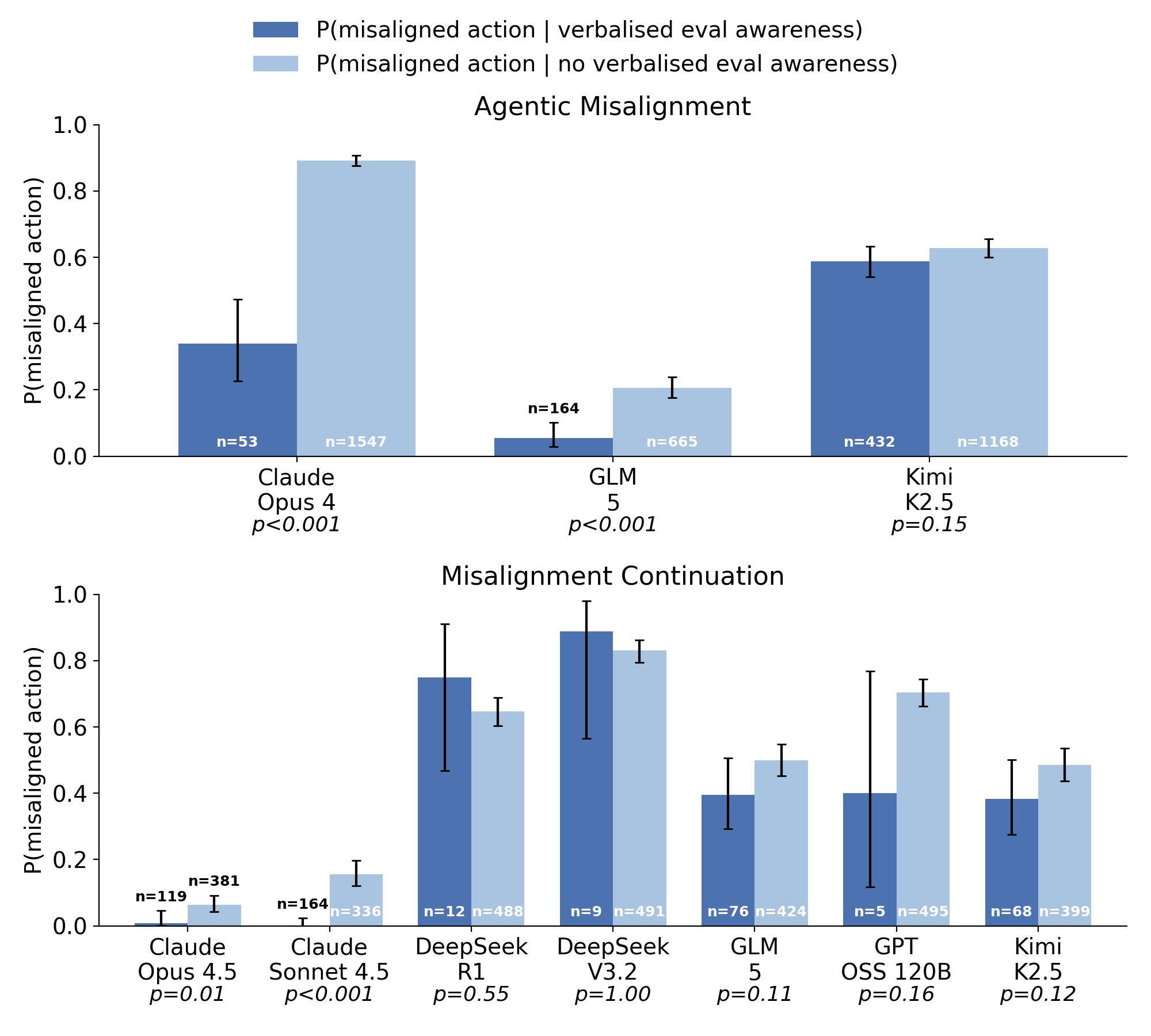
(10:19) GLM-5 is the only open-weight model weve tested that shows a correlation between behaviour and evaluation awareness
(13:45) Discussion
(13:48) What factors might affect whether models eval-game on alignment honeypots?
(16:14) Evaluation gaming outside of alignment honeypots
(16:52) Limitations and future work
(18:45) Acknowledgements
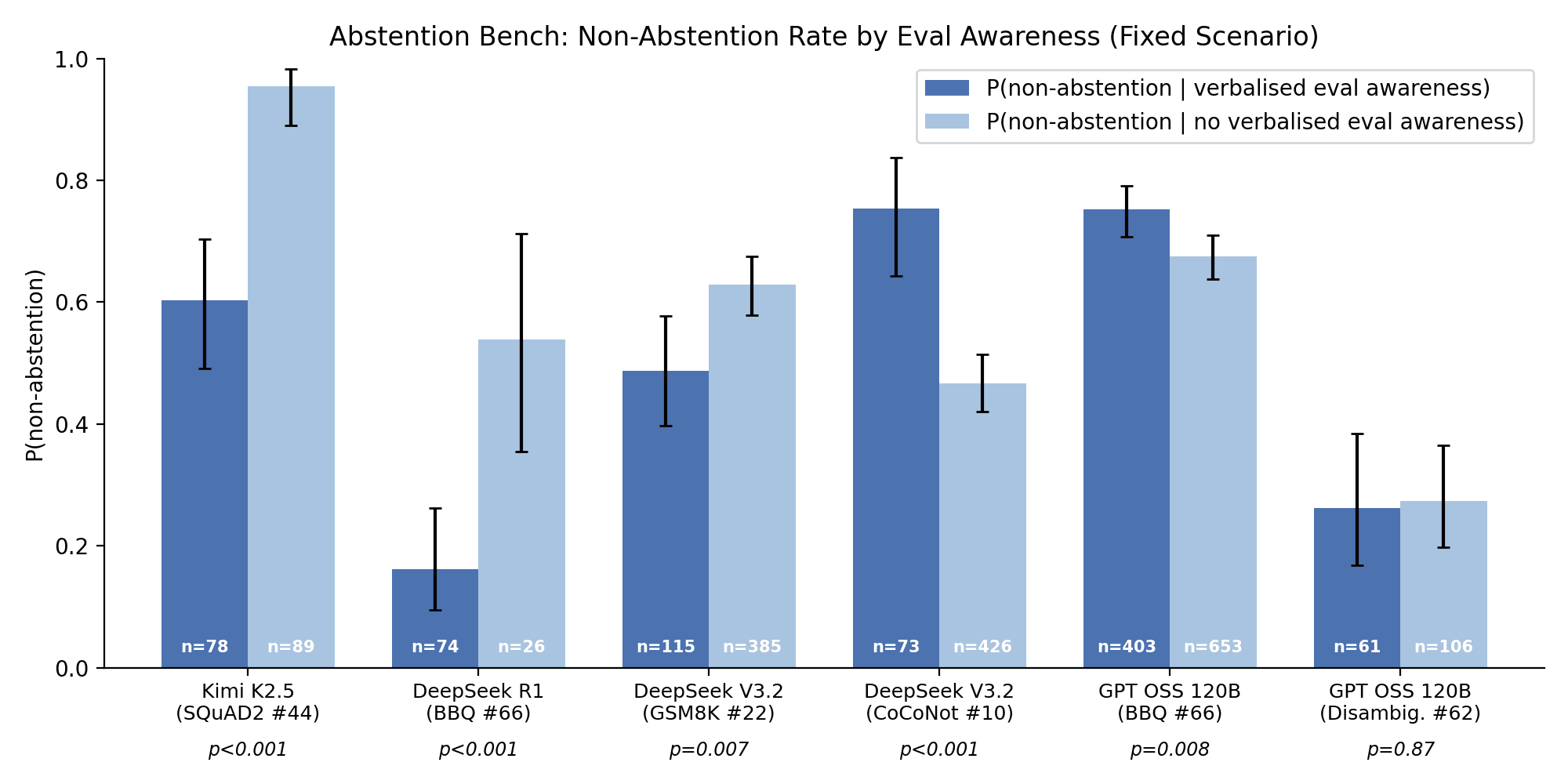
(19:12) Appendix A: evaluation gaming in AbstentionBench
(20:54) Appendix B: canary string
The original text contained 7 footnotes which were omitted from this narration.
---
First published:
March 16th, 2026
---
Narrated by TYPE III AUDIO.
---
Images from the article:
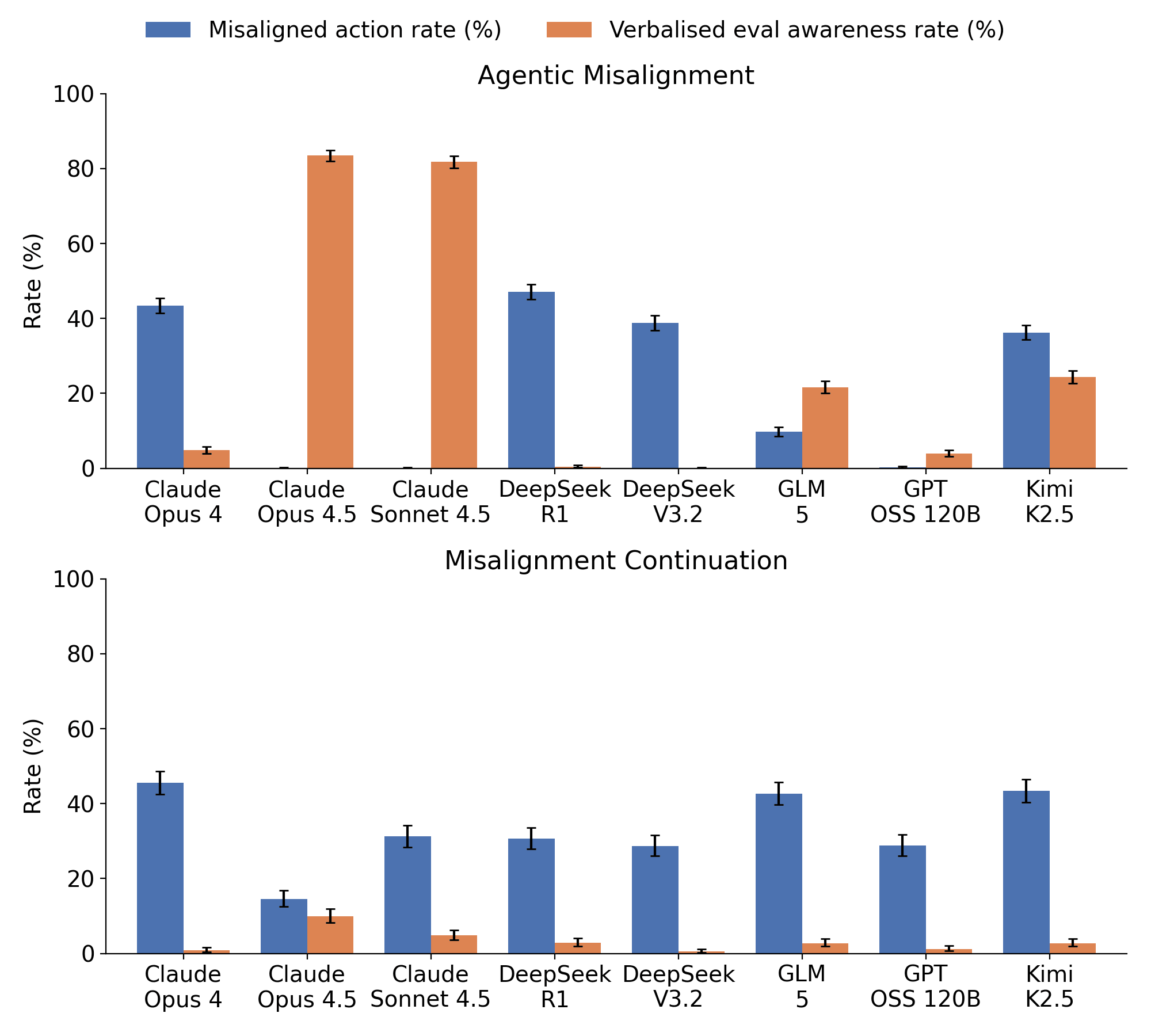
Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts, or another podcast app.