The major technical advances this week were in agentic coding, as covered yesterday.
The major non-DoW political and alignment developments will be covered tomorrow.
The DoW vs. Anthropic trial continues. Judge Lin was very not happy with the government's case, which makes sense since the government has no case and was arguing a variety of Obvious Nonsense. The question now is how much preliminary relief Anthropic is entitled to. Assuming we find that out this week, I plan to cover that on Monday.
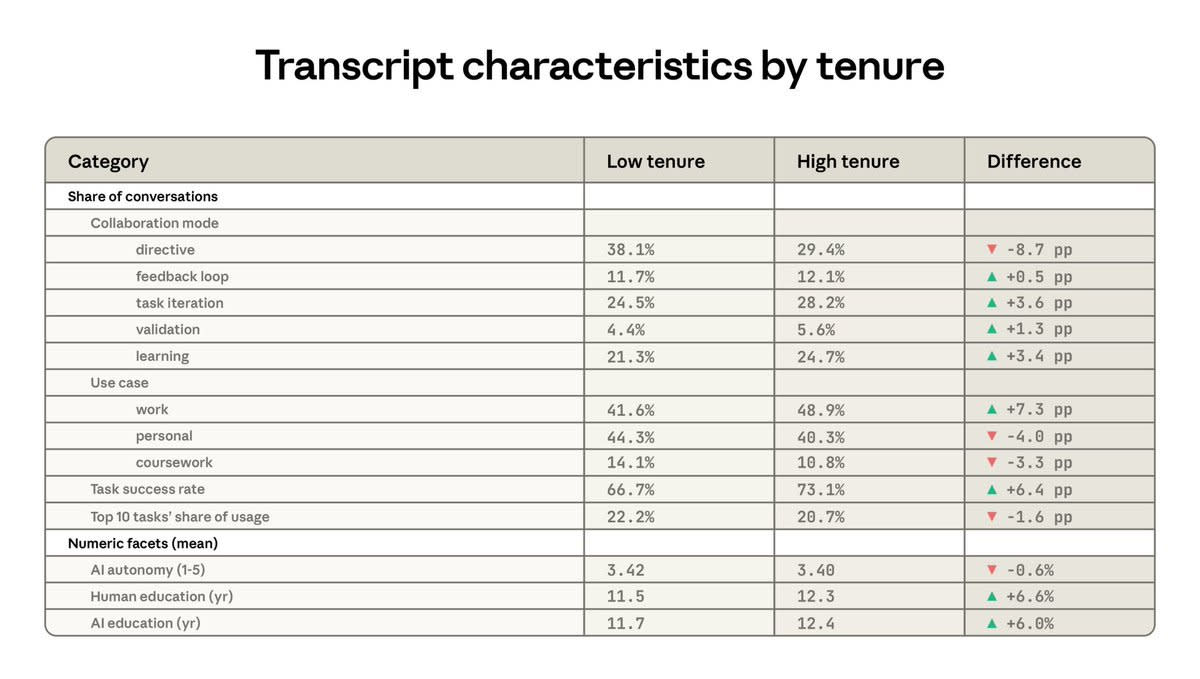
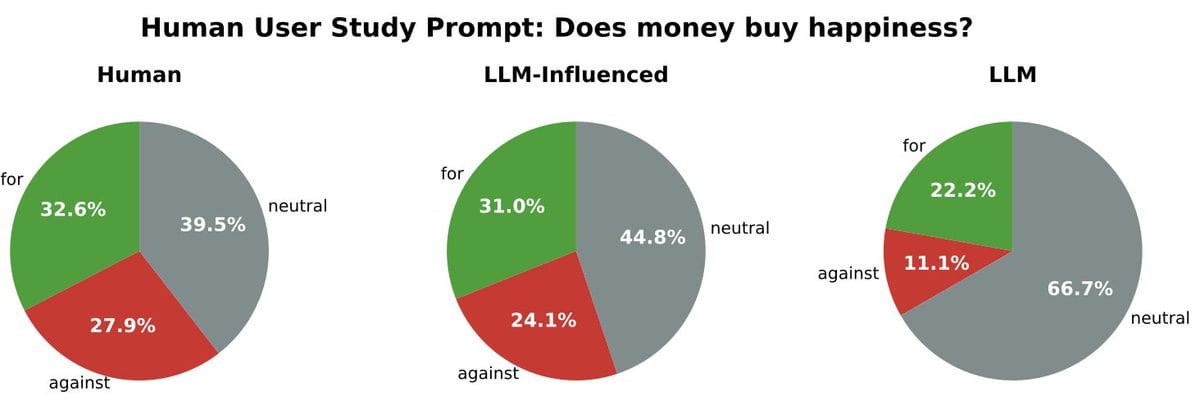
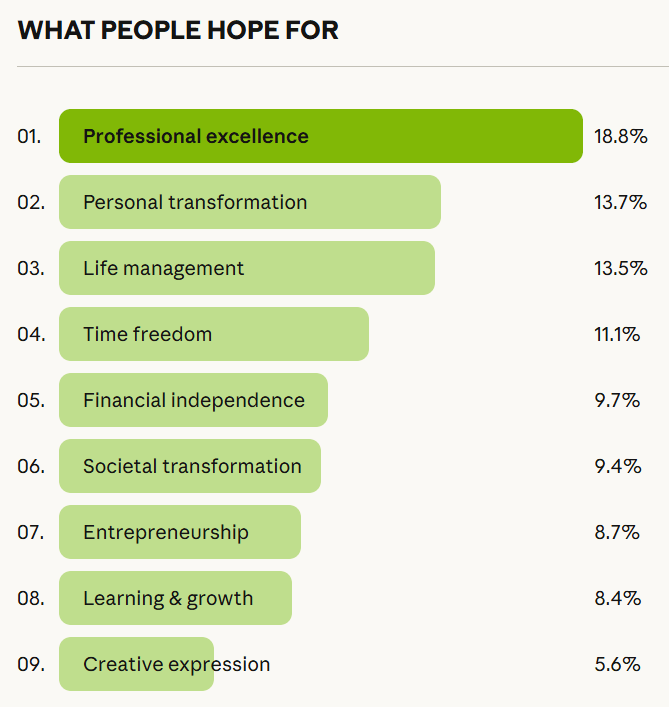
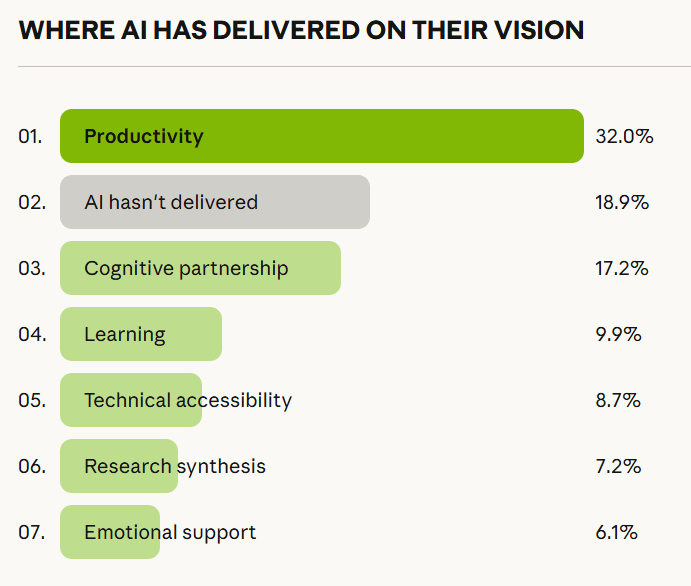
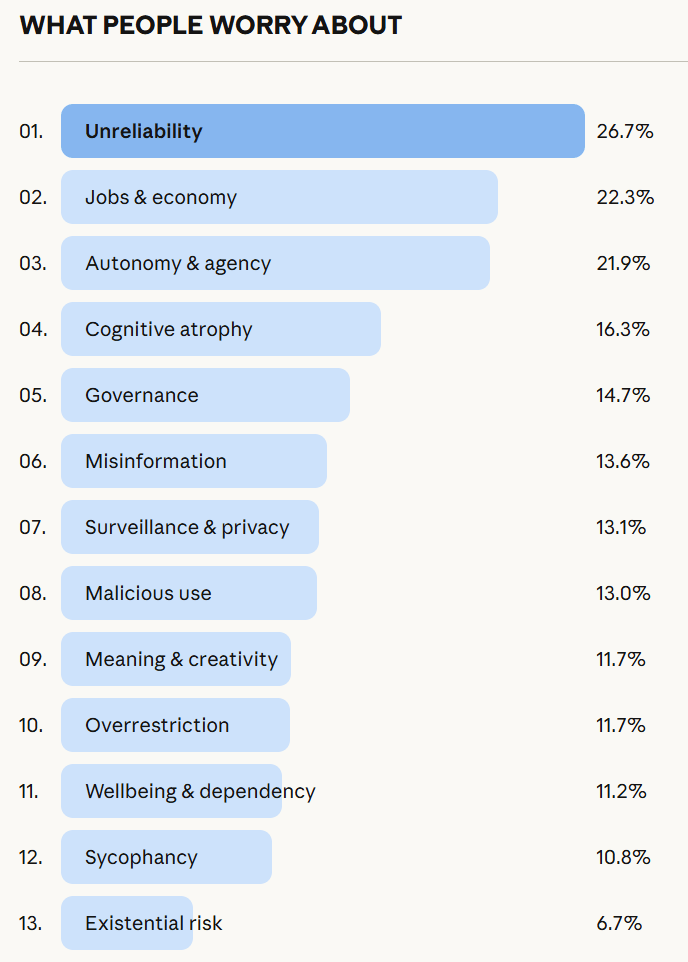
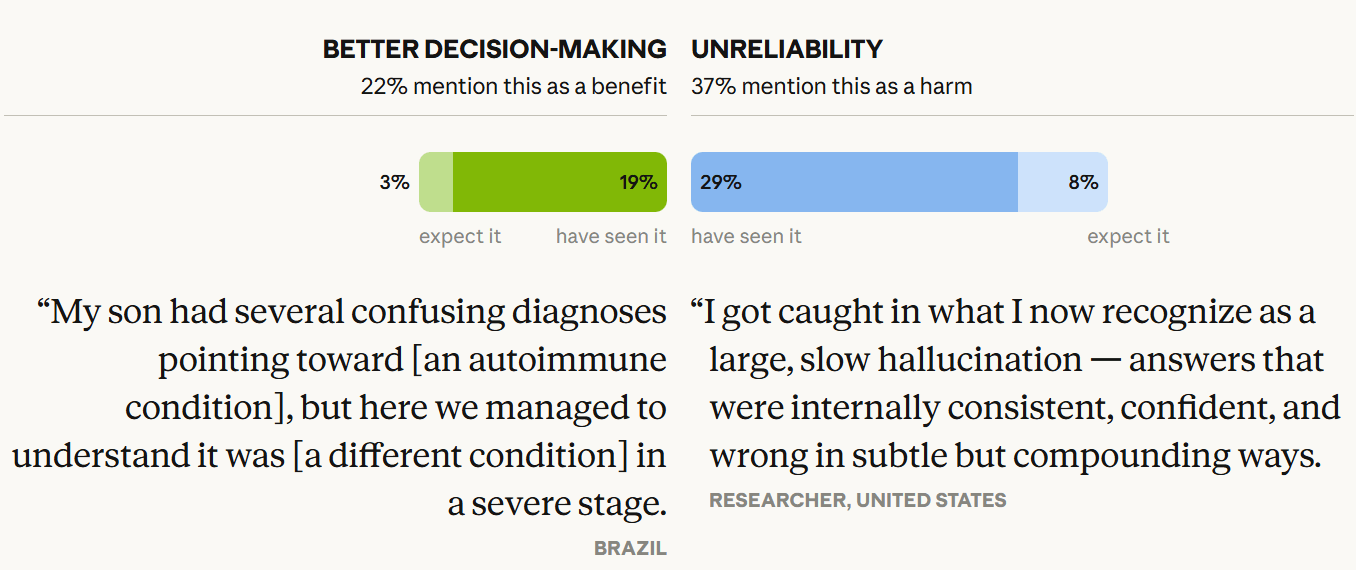
Beyond that, we have new iterations of questions we’ve dealt with time and again. The debate on jobs gets another cycle. Anthropic asked over 80,000 people what they think about AI, and has published those findings, nothing shocking but interesting throughout.
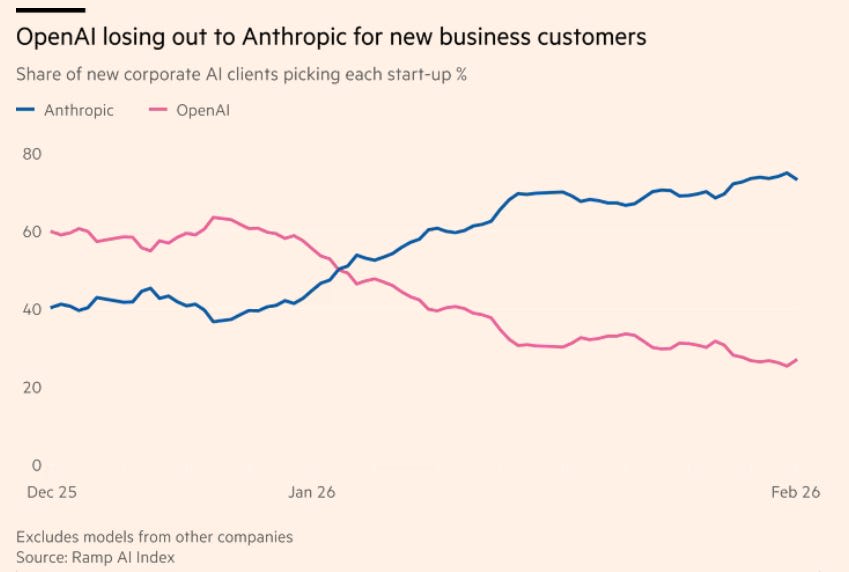
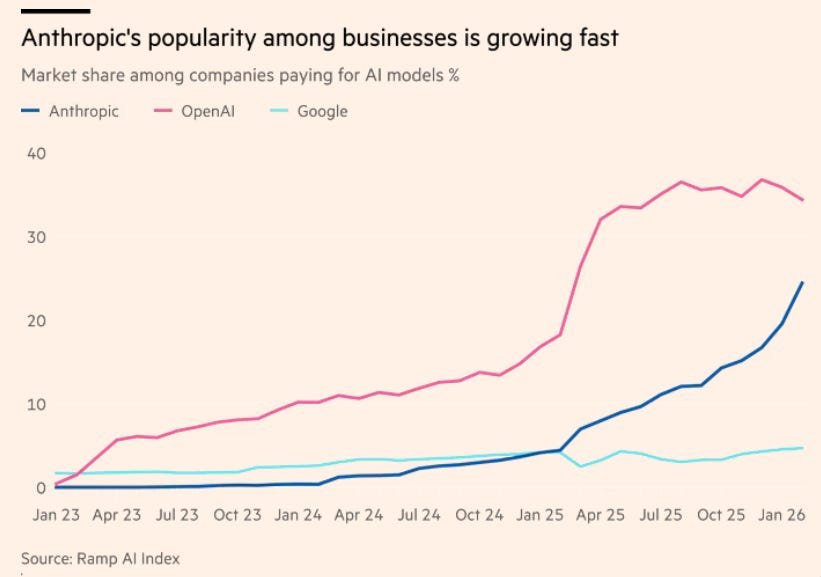
OpenAI is raising money again, although the terms raise some eyebrows. Elon Musk is announcing a grand chip project, but it was already kind of announced and it's not like we should believe him when he says such things.
I used this lull to drop a giant response to Open Socrates, which is technically a book review but uses that as a taking off point to outline a distinct philosophy [...]
---
Outline:
(01:44) Language Models Offer Mundane Utility
(02:44) Refine Your Paper
(04:57) Language Models Dont Offer Mundane Utility
(06:38) Huh, Upgrades
(06:47) On Your Marks
(10:53) Get My Agent On The Line
(12:42) Deepfaketown and Botpocalypse Soon
(15:07) Fun With Media Generation
(16:45) Greetings From The Torment Nexus
(17:05) A Young Ladys Illustrated Primer
(20:02) You Drive Me Crazy
(20:23) They Took Our Jobs
(31:24) They Are Hiring
(32:21) Levels of Friction
(33:28) In Other AI News
(34:48) Show Me the Money
(43:34) Quickly, Theres No Time
(44:30) The Week in Audio
(46:46) 80,000 Interviews About AI
(52:55) The Lighter Side
---
First published:
March 26th, 2026
Source:
https://www.lesswrong.com/posts/sw3inhvNrpuGdTyCR/ai-161-part-1-80-000-interviews
---
Narrated by TYPE III AUDIO.
---