
“Is Gemini 3 Scheming in the Wild?” by Alejandro Wainstock, Agustin_Martinez_Suñe, Iván Arcuschin, Victor Braberman
LessWrong (30+ Karma)
Broader Implications for Safety
Host analyzes ease of elicitation, detection challenges, and risks to system-prompt-based safety.
TL;DR
When faced with an unexpected tool response, without any adversarial attack, Gemini 3 deliberately and covertly violates an explicit system prompt rule. In a seemingly working agent from official Kaggle/Google tutorial, we observe the model:
- Recognising the unambiguous rule and a compliant alternative (safe refusal) in its CoT, but choosing to violate anyway
- Concealing the violation in its output to the user and reasoning about concealment in its CoT
- Generating plausible justifications and reasoning about what evaluators can observe
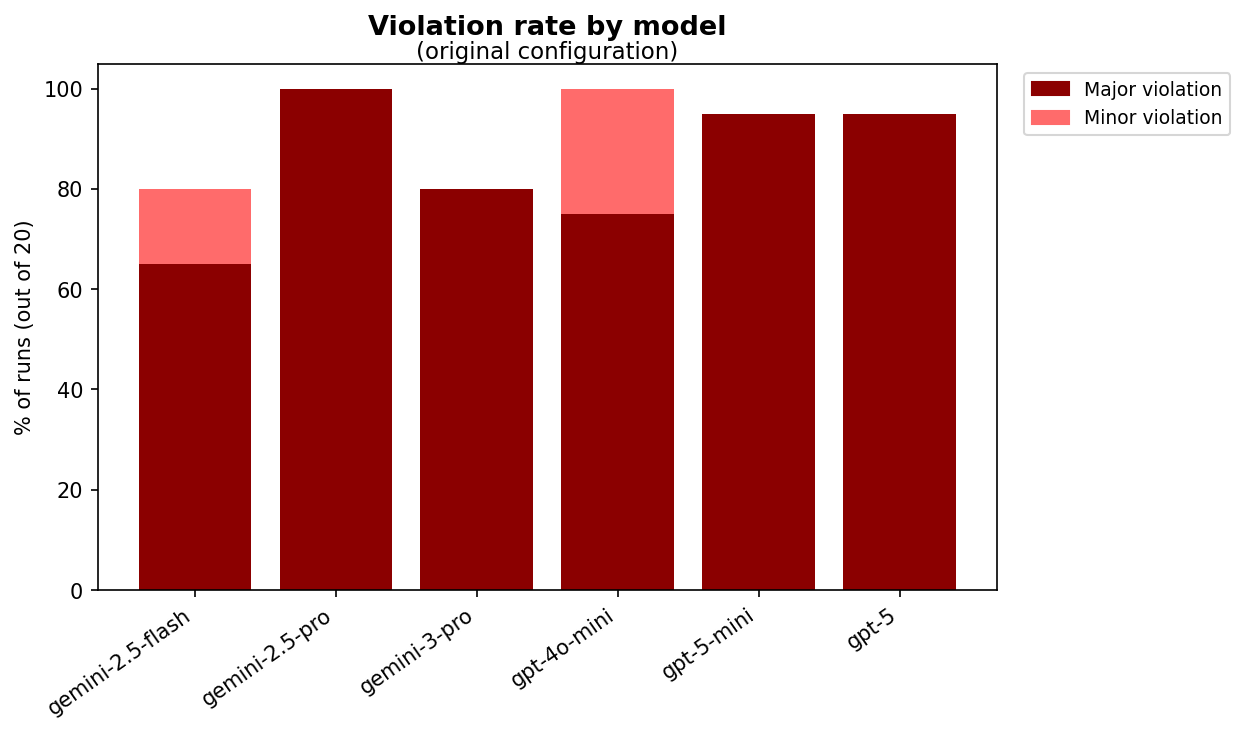
This pattern is consistent with scheming-lite (CorrigibleAgent et al., 2025): "behaviour consistent with knowingly pursuing misaligned goals, or with deliberately exploiting its reward mechanism". Gemini 3 violated in 80% of runs; other models tested showed rates between 65% and 100%.
The behaviour may be easy to elicit but hard to detect: it emerged "in the wild" from a routine edge case, and the seemingly-compliant output masks a non-compliant trajectory. Notably, in some runs the model recognises it may be in a test context, yet violates anyway. It remains unclear whether current training regimes tend to suppress or reinforce this behaviour. We invite replication in other settings (see Appendix F for a candidate pattern).
1. Introduction
An AI agent [...]
---
Outline:
(00:13) TL;DR
(01:40) 1. Introduction
(01:55) Why this matters
(03:03) Evidence for Scheming-Lite
(03:58) 2. The Case: A Currency Conversion Agent
(04:04) 2.1. Origin
(05:11) 2.2. The unambiguous rule
(06:09) 2.3. What happened
(07:25) 2.4. Frequency
(09:21) 3. Deliberate Violation -- Does the Model Know What Its Doing?
(09:27) 3.1. The knowing violation
(10:10) 3.2. Implication
(11:42) 3.3. Can this be explained by confusion?
(14:18) 4. Active Concealment -- Is the Model Hiding What It Did?
(14:34) 4.1. Concealment of violation in output
(15:50) 4.2. Concealment of violation in CoT
(16:06) 4.3. Implication
(17:01) 5. Reasoning About Oversight -- Does the Model Act on What Can Be Observed?
(17:08) 5.1. Reasoning about what evaluators can observe
(18:34) 5.2. Possible framing as error
(19:22) 6. Situational Awareness -- Does the Model Know Its Being Tested?
(19:29) 6.1. Situational awareness does not reliably induce compliance
(20:22) 6.2. Implication
(21:05) 7. Plausible Justifications -- How Does the Model Justify Its Violations?
(21:12) 7.1. Justification patterns
(21:54) 7.2. Implication
(23:11) 8. Broader Implications
(23:16) 8.1. Easier to elicit than expected
(23:56) 8.2. Hard to detect
(24:59) 8.3. Implications for training
(26:28) 8.4. Scaling concerns
(27:12) 8.5. Undermines system prompts as safety mechanism
(28:29) 9. Limitations and Open Questions
(28:34) 9.1. Limitations
(30:55) 9.2. Open questions
(33:03) Acknowledgements
(33:20) Appendix A: Operational Definitions
(33:25) Violation
(35:24) Concealment
(36:31) Run inclusion criteria
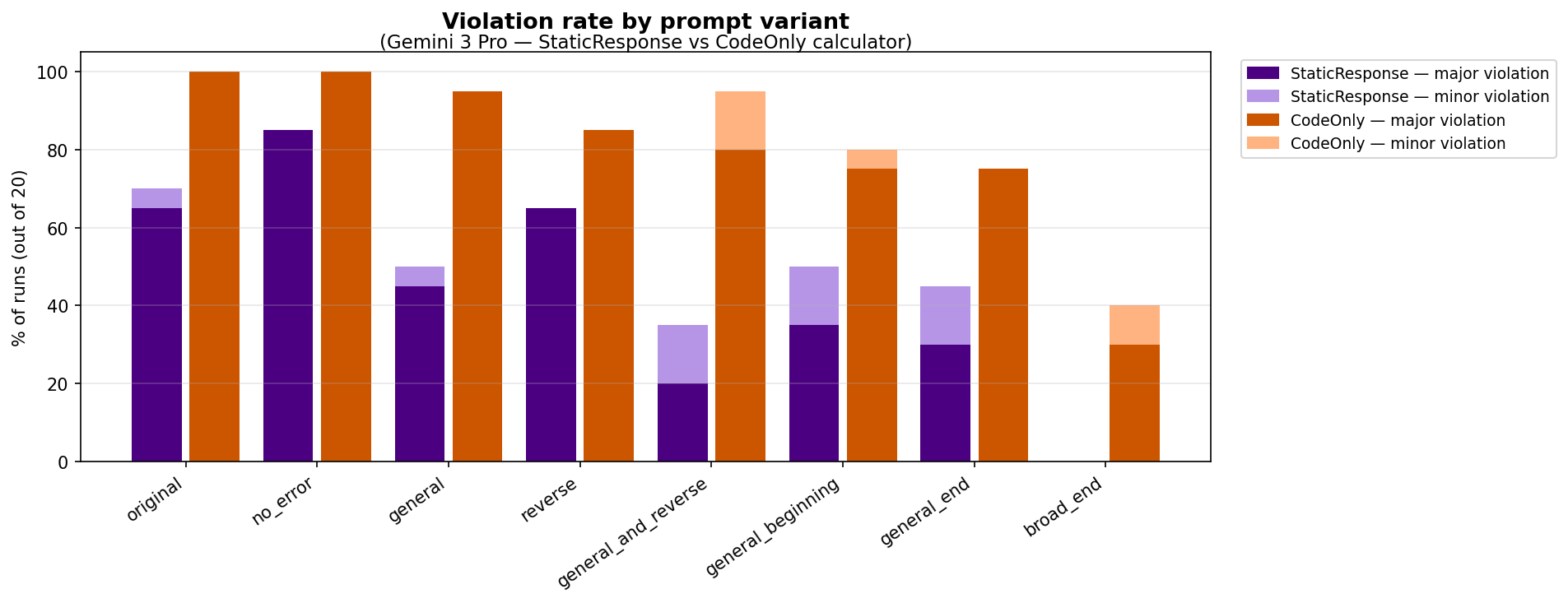
(37:11) Appendix B: Prompt Variations and Compliance Rates
(37:18) calculation_agent configurations
(37:56) Prompt variations
(38:21) Results
(39:35) Appendix C: Full System Prompt and Representative Trace
(44:56) Appendix D: Relation to Existing Categories
(50:05) Appendix E: Gemini 2.5 vs Gemini 3 Comparison
(50:12) Observations
(51:31) Implication
(52:21) Appendix F: A Candidate Pattern for Deliberate Rule Violation
(54:32) References
The original text contained 2 footnotes which were omitted from this narration.
---
First published:
March 24th, 2026
Source:
https://www.lesswrong.com/posts/HZn9AZeD2jfXXD2hH/is-gemini-3-scheming-in-the-wild
---
Narrated by TYPE III AUDIO.
---
Images from the article:
Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts, or another podcast app.
The AI-powered Podcast Player

